

Google Professional Cloud Developer Practice Exam Free – 50 Questions to Simulate the Real Exam
Are you getting ready for the Google Professional Cloud Developer certification? Take your preparation to the next level with our Google Professional Cloud Developer Practice Exam Free – a carefully designed set of 50 realistic exam-style questions to help you evaluate your knowledge and boost your confidence.
Using a Google Professional Cloud Developer practice exam free is one of the best ways to:
- Experience the format and difficulty of the real exam
- Identify your strengths and focus on weak areas
- Improve your test-taking speed and accuracy
Below, you will find 50 realistic Google Professional Cloud Developer practice exam free questions covering key exam topics. Each question reflects the structure and challenge of the actual exam.
You have an application running in a production Google Kubernetes Engine (GKE) cluster. You use Cloud Deploy to automatically deploy your application to your production GKE cluster. As part of your development process, you are planning to make frequent changes to the application’s source code and need to select the tools to test the changes before pushing them to your remote source code repository. Your toolset must meet the following requirements: • Test frequent local changes automatically. • Local deployment emulates production deployment. Which tools should you use to test building and running a container on your laptop using minimal resources?
A. Docker Compose and dockerd
B. Terraform and kubeadm
C. Minikube and Skaffold
D. kaniko and Tekton
You have an application running in App Engine. Your application is instrumented with Stackdriver Trace. The /product-details request reports details about four known unique products at /sku-details as shown below. You want to reduce the time it takes for the request to complete. What should you do?

A. Increase the size of the instance class.
B. Change the Persistent Disk type to SSD.
C. Change /product-details to perform the requests in parallel.
D. Store the /sku-details information in a database, and replace the webservice call with a database query.
You are a developer at a large organization. You are deploying a web application to Google Kubernetes Engine (GKE). The DevOps team has built a CI/CD pipeline that uses Cloud Deploy to deploy the application to Dev, Test, and Prod clusters in GKE. After Cloud Deploy successfully deploys the application to the Dev cluster, you want to automatically promote it to the Test cluster. How should you configure this process following Google-recommended best practices?
A. 1. Create a Cloud Build trigger that listens for SUCCEEDED Pub/Sub messages from the clouddeploy-operations topic.2. Configure Cloud Build to include a step that promotes the application to the Test cluster.
B. 1. Create a Cloud Function that calls the Google Cloud Deploy API to promote the application to the Test cluster.2. Configure this function to be triggered by SUCCEEDED Pub/Sub messages from the cloud-builds topic.
C. 1. Create a Cloud Function that calls the Google Cloud Deploy API to promote the application to the Test cluster.2. Configure this function to be triggered by SUCCEEDED Pub/Sub messages from the clouddeploy-operations topic.
D. 1. Create a Cloud Build pipeline that uses the gke-deploy builder.2. Create a Cloud Build trigger that listens for SUCCEEDED Pub/Sub messages from the cloud-builds topic.3. Configure this pipeline to run a deployment step to the Test cluster.
Your security team is auditing all deployed applications running in Google Kubernetes Engine. After completing the audit, your team discovers that some of the applications send traffic within the cluster in clear text. You need to ensure that all application traffic is encrypted as quickly as possible while minimizing changes to your applications and maintaining support from Google. What should you do?
A. Use Network Policies to block traffic between applications.
B. Install Istio, enable proxy injection on your application namespace, and then enable mTLS.
C. Define Trusted Network ranges within the application, and configure the applications to allow traffic only from those networks.
D. Use an automated process to request SSL Certificates for your applications from Let’s Encrypt and add them to your applications.
Case study - This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided. To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study. At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section. To start the case study - To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question. Company Overview - HipLocal is a community application designed to facilitate communication between people in close proximity. It is used for event planning and organizing sporting events, and for businesses to connect with their local communities. HipLocal launched recently in a few neighborhoods in Dallas and is rapidly growing into a global phenomenon. Its unique style of hyper-local community communication and business outreach is in demand around the world. Executive Statement - We are the number one local community app; it's time to take our local community services global. Our venture capital investors want to see rapid growth and the same great experience for new local and virtual communities that come online, whether their members are 10 or 10000 miles away from each other. Solution Concept - HipLocal wants to expand their existing service, with updated functionality, in new regions to better serve their global customers. They want to hire and train a new team to support these regions in their time zones. They will need to ensure that the application scales smoothly and provides clear uptime data. Existing Technical Environment - HipLocal's environment is a mix of on-premises hardware and infrastructure running in Google Cloud Platform. The HipLocal team understands their application well, but has limited experience in global scale applications. Their existing technical environment is as follows: * Existing APIs run on Compute Engine virtual machine instances hosted in GCP. * State is stored in a single instance MySQL database in GCP. * Data is exported to an on-premises Teradata/Vertica data warehouse. * Data analytics is performed in an on-premises Hadoop environment. * The application has no logging. * There are basic indicators of uptime; alerts are frequently fired when the APIs are unresponsive. Business Requirements - HipLocal's investors want to expand their footprint and support the increase in demand they are seeing. Their requirements are: * Expand availability of the application to new regions. * Increase the number of concurrent users that can be supported. * Ensure a consistent experience for users when they travel to different regions. * Obtain user activity metrics to better understand how to monetize their product. * Ensure compliance with regulations in the new regions (for example, GDPR). * Reduce infrastructure management time and cost. * Adopt the Google-recommended practices for cloud computing. Technical Requirements - * The application and backend must provide usage metrics and monitoring. * APIs require strong authentication and authorization. * Logging must be increased, and data should be stored in a cloud analytics platform. * Move to serverless architecture to facilitate elastic scaling. * Provide authorized access to internal apps in a secure manner. Which service should HipLocal use to enable access to internal apps?
A. Cloud VPN
B. Cloud Armor
C. Virtual Private Cloud
D. Cloud Identity-Aware Proxy
You are designing a chat room application that will host multiple rooms and retain the message history for each room. You have selected Firestore as your database. How should you represent the data in Firestore?
A. Create a collection for the rooms. For each room, create a document that lists the contents of the messages
B. Create a collection for the rooms. For each room, create a collection that contains a document for each message
C. Create a collection for the rooms. For each room, create a document that contains a collection for documents, each of which contains a message.
D. Create a collection for the rooms, and create a document for each room. Create a separate collection for messages, with one document per message. Each room’s document contains a list of references to the messages.
Your company has a BigQuery data mart that provides analytics information to hundreds of employees. One user of wants to run jobs without interrupting important workloads. This user isn't concerned about the time it takes to run these jobs. You want to fulfill this request while minimizing cost to the company and the effort required on your part. What should you do?
A. Ask the user to run the jobs as batch jobs.
B. Create a separate project for the user to run jobs.
C. Add the user as a job.user role in the existing project.
D. Allow the user to run jobs when important workloads are not running.
You manage a microservices application on Google Kubernetes Engine (GKE) using Istio. You secure the communication channels between your microservices by implementing an Istio AuthorizationPolicy, a Kubernetes NetworkPolicy, and mTLS on your GKE cluster. You discover that HTTP requests between two Pods to specific URLs fail, while other requests to other URLs succeed. What is the cause of the connection issue?
A. A Kubernetes NetworkPolicy resource is blocking HTTP traffic between the Pods.
B. The Pod initiating the HTTP requests is attempting to connect to the target Pod via an incorrect TCP port.
C. The Authorization Policy of your cluster is blocking HTTP requests for specific paths within your application.
D. The cluster has mTLS configured in permissive mode, but the Pod’s sidecar proxy is sending unencrypted traffic in plain text.
You are running a containerized application on Google Kubernetes Engine. Your container images are stored in Container Registry. Your team uses CI/CD practices. You need to prevent the deployment of containers with known critical vulnerabilities. What should you do?
A. • Use Web Security Scanner to automatically crawl your application• Review your application logs for scan results, and provide an attestation that the container is free of known critical vulnerabilities• Use Binary Authorization to implement a policy that forces the attestation to be provided before the container is deployed
B. • Use Web Security Scanner to automatically crawl your application• Review the scan results in the scan details page in the Cloud Console, and provide an attestation that the container is free of known critical vulnerabilities• Use Binary Authorization to implement a policy that forces the attestation to be provided before the container is deployed
C. • Enable the Container Scanning API to perform vulnerability scanning• Review vulnerability reporting in Container Registry in the Cloud Console, and provide an attestation that the container is free of known critical vulnerabilities• Use Binary Authorization to implement a policy that forces the attestation to be provided before the container is deployed
D. • Enable the Container Scanning API to perform vulnerability scanning• Programmatically review vulnerability reporting through the Container Scanning API, and provide an attestation that the container is free of known critical vulnerabilities• Use Binary Authorization to implement a policy that forces the attestation to be provided before the container is deployed
You recently developed an application that monitors a large number of stock prices. You need to configure Pub/Sub to receive a high volume messages and update the current stock price in a single large in-memory database. A downstream service needs the most up-to-date prices in the in-memory database to perform stock trading transactions. Each message contains three pieces or information: • Stock symbol • Stock price • Timestamp for the update How should you set up your Pub/Sub subscription?
A. Create a pull subscription with exactly-once delivery enabled.
B. Create a push subscription with both ordering and exactly-once delivery turned off.
C. Create a push subscription with exactly-once delivery enabled.
D. Create a pull subscription with both ordering and exactly-once delivery turned off.
Your team develops services that run on Google Cloud. You want to process messages sent to a Pub/Sub topic, and then store them. Each message must be processed exactly once to avoid duplication of data and any data conflicts. You need to use the cheapest and most simple solution. What should you do?
A. Process the messages with a Dataproc job, and write the output to storage.
B. Process the messages with a Dataflow streaming pipeline using Apache Beam’s PubSubIO package, and write the output to storage.
C. Process the messages with a Cloud Function, and write the results to a BigQuery location where you can run a job to deduplicate the data.
D. Retrieve the messages with a Dataflow streaming pipeline, store them in Cloud Bigtable, and use another Dataflow streaming pipeline to deduplicate messages.
You need to containerize a web application that will be hosted on Google Cloud behind a global load balancer with SSL certificates. You don’t have the time to develop authentication at the application level, and you want to offload SSL encryption and management from your application. You want to configure the architecture using managed services where possible. What should you do?
A. Host the application on Google Kubernetes Engine, and deploy an NGINX Ingress Controller to handle authentication.
B. Host the application on Google Kubernetes Engine, and deploy cert-manager to manage SSL certificates.
C. Host the application on Compute Engine, and configure Cloud Endpoints for your application.
D. Host the application on Google Kubernetes Engine, and use Identity-Aware Proxy (IAP) with Cloud Load Balancing and Google-managed certificates.
Your team detected a spike of errors in an application running on Cloud Run in your production project. The application is configured to read messages from Pub/Sub topic A, process the messages, and write the messages to topic
A. You want to conduct tests to identify the cause of the errors. You can use a set of mock messages for testing. What should you do?
B. Deploy the Pub/Sub and Cloud Run emulators on your local machine. Deploy the application locally, and change the logging level in the application to DEBUG or INFO. Write mock messages to topic A, and then analyze the logs.
C. Use the gcloud CLI to write mock messages to topic
D. Change the logging level in the application to DEBUG or INFO, and then analyze the logs.
E. Deploy the Pub/Sub emulator on your local machine. Point the production application to your local Pub/Sub topics. Write mock messages to topic A, and then analyze the logs.
F. Use the Google Cloud console to write mock messages to topic
G. Change the logging level in the application to DEBUG or INFO, and then analyze the logs.
You are deploying a Python application to Cloud Run using Cloud Source Repositories and Cloud Build. The Cloud Build pipeline is shown below:You want to optimize deployment times and avoid unnecessary steps. What should you do?
A. Remove the step that pushes the container to Artifact Registry.
B. Deploy a new Docker registry in a VPC, and use Cloud Build worker pools inside the VPC to run the build pipeline.
C. Store image artifacts in a Cloud Storage bucket in the same region as the Cloud Run instance.
D. Add the –cache-from argument to the Docker build step in your build config file.
You are planning to deploy your application in a Google Kubernetes Engine (GKE) cluster. The application exposes an HTTP-based health check at /healthz. You want to use this health check endpoint to determine whether traffic should be routed to the pod by the load balancer. Which code snippet should you include in your Pod configuration?


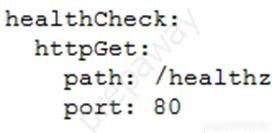
You have an on-premises application that authenticates to the Cloud Storage API using a user-managed service account with a user-managed key. The application connects to Cloud Storage using Private Google Access over a Dedicated Interconnect link. You discover that requests from the application to access objects in the Cloud Storage bucket are failing with a 403 Permission Denied error code. What is the likely cause of this issue?
A. The folder structure inside the bucket and object paths have changed.
B. The permissions of the service account’s predefined role have changed.
C. The service account key has been rotated but not updated on the application server.
D. The Interconnect link from the on-premises data center to Google Cloud is experiencing a temporary outage.
You are developing an application that will allow users to read and post comments on news articles. You want to configure your application to store and display user-submitted comments using Firestore. How should you design the schema to support an unknown number of comments and articles?
A. Store each comment in a subcollection of the article.
B. Add each comment to an array property on the article.
C. Store each comment in a document, and add the comment’s key to an array property on the article.
D. Store each comment in a document, and add the comment’s key to an array property on the user profile.
You are developing an online gaming platform as a microservices application on Google Kubernetes Engine (GKE). Users on social media are complaining about long loading times for certain URL requests to the application. You need to investigate performance bottlenecks in the application and identify which HTTP requests have a significantly high latency span in user requests. What should you do?
A. Configure GKE workload metrics using kubectl. Select all Pods to send their metrics to Cloud Monitoring. Create a custom dashboard of application metrics in Cloud Monitoring to determine performance bottlenecks of your GKE cluster.
B. Update your microservices to log HTTP request methods and URL paths to STDOUT. Use the logs router to send container logs to Cloud Logging. Create filters in Cloud Logging to evaluate the latency of user requests across different methods and URL paths.
C. Instrument your microservices by installing the OpenTelemetry tracing package. Update your application code to send traces to Trace for inspection and analysis. Create an analysis report on Trace to analyze user requests.
D. Install tcpdump on your GKE nodes. Run tcpdump to capture network traffic over an extended period of time to collect data. Analyze the data files using Wireshark to determine the cause of high latency.
You are developing a web application that contains private images and videos stored in a Cloud Storage bucket. Your users are anonymous and do not have Google Accounts. You want to use your application-specific logic to control access to the images and videos. How should you configure access?
A. Cache each web application user’s IP address to create a named IP table using Google Cloud Armor. Create a Google Cloud Armor security policy that allows users to access the backend bucket.
B. Grant the Storage Object Viewer IAM role to allUsers. Allow users to access the bucket after authenticating through your web application.
C. Configure Identity-Aware Proxy (IAP) to authenticate users into the web application. Allow users to access the bucket after authenticating through IAP.
D. Generate a signed URL that grants read access to the bucket. Allow users to access the URL after authenticating through your web application.
You recently developed an application. You need to call the Cloud Storage API from a Compute Engine instance that doesn't have a public IP address. What should you do?
A. Use Carrier Peering
B. Use VPC Network Peering
C. Use Shared VPC networks
D. Use Private Google Access
Your development team has built several Cloud Functions using Java along with corresponding integration and service tests. You are building and deploying the functions and launching the tests using Cloud Build. Your Cloud Build job is reporting deployment failures immediately after successfully validating the code. What should you do?
A. Check the maximum number of Cloud Function instances.
B. Verify that your Cloud Build trigger has the correct build parameters.
C. Retry the tests using the truncated exponential backoff polling strategy.
D. Verify that the Cloud Build service account is assigned the Cloud Functions Developer role.
You are writing a Compute Engine hosted application in project A that needs to securely authenticate to a Cloud Pub/Sub topic in project
A. What should you do?
B. Configure the instances with a service account owned by project
C. Add the service account as a Cloud Pub/Sub publisher to project
D. Configure the instances with a service account owned by project
E. Add the service account as a publisher on the topic.
F. Configure Application Default Credentials to use the private key of a service account owned by project
G. Add the service account as a Cloud Pub/Sub publisher to project
H. Configure Application Default Credentials to use the private key of a service account owned by project
Your data is stored in Cloud Storage buckets. Fellow developers have reported that data downloaded from Cloud Storage is resulting in slow API performance. You want to research the issue to provide details to the GCP support team. Which command should you run?
A. gsutil test ג€”o output.json gs://my-bucket
B. gsutil perfdiag ג€”o output.json gs://my-bucket
C. gcloud compute scp example-instance:~/test-data ג€”o output.json gs://my-bucket
D. gcloud services test ג€”o output.json gs://my-bucket
Your application takes an input from a user and publishes it to the user's contacts. This input is stored in a table in Cloud Spanner. Your application is more sensitive to latency and less sensitive to consistency. How should you perform reads from Cloud Spanner for this application?
A. Perform Read-Only transactions.
B. Perform stale reads using single-read methods.
C. Perform strong reads using single-read methods.
D. Perform stale reads using read-write transactions.
You are using Cloud Run to host a global ecommerce web application. Your company’s design team is creating a new color scheme for the web app. You have been tasked with determining whether the new color scheme will increase sales. You want to conduct testing on live production traffic. How should you design the study?
A. Use an external HTTP(S) load balancer to route a predetermined percentage of traffic to two different color schemes of your application. Analyze the results to determine whether there is a statistically significant difference in sales.
B. Use an external HTTP(S) load balancer to route traffic to the original color scheme while the new deployment is created and tested. After testing is complete, reroute all traffic to the new color scheme. Analyze the results to determine whether there is a statistically significant difference in sales.
C. Use an external HTTP(S) load balancer to mirror traffic to the new version of your application. Analyze the results to determine whether there is a statistically significant difference in sales.
D. Enable a feature flag that displays the new color scheme to half of all users. Monitor sales to see whether they increase for this group of users.
You are deploying your applications on Compute Engine. One of your Compute Engine instances failed to launch. What should you do? (Choose two.)
A. Determine whether your file system is corrupted.
B. Access Compute Engine as a different SSH user.
C. Troubleshoot firewall rules or routes on an instance.
D. Check whether your instance boot disk is completely full.
E. Check whether network traffic to or from your instance is being dropped.
You are developing a new public-facing application that needs to retrieve specific properties in the metadata of users’ objects in their respective Cloud Storage buckets. Due to privacy and data residency requirements, you must retrieve only the metadata and not the object data. You want to maximize the performance of the retrieval process. How should you retrieve the metadata?
A. Use the patch method.
B. Use the compose method.
C. Use the copy method.
D. Use the fields request parameter.
You work on an application that relies on Cloud Spanner as its main datastore. New application features have occasionally caused performance regressions. You want to prevent performance issues by running an automated performance test with Cloud Build for each commit made. If multiple commits are made at the same time, the tests might run concurrently. What should you do?
A. Create a new project with a random name for every build. Load the required data. Delete the project after the test is run.
B. Create a new Cloud Spanner instance for every build. Load the required data. Delete the Cloud Spanner instance after the test is run.
C. Create a project with a Cloud Spanner instance and the required data. Adjust the Cloud Build build file to automatically restore the data to its previous state after the test is run.
D. Start the Cloud Spanner emulator locally. Load the required data. Shut down the emulator after the test is run.
You recently migrated a monolithic application to Google Cloud by breaking it down into microservices. One of the microservices is deployed using Cloud Functions. As you modernize the application, you make a change to the API of the service that is backward-incompatible. You need to support both existing callers who use the original API and new callers who use the new API. What should you do?
A. Leave the original Cloud Function as-is and deploy a second Cloud Function with the new API. Use a load balancer to distribute calls between the versions.
B. Leave the original Cloud Function as-is and deploy a second Cloud Function that includes only the changed API. Calls are automatically routed to the correct function.
C. Leave the original Cloud Function as-is and deploy a second Cloud Function with the new API. Use Cloud Endpoints to provide an API gateway that exposes a versioned API.
D. Re-deploy the Cloud Function after making code changes to support the new API. Requests for both versions of the API are fulfilled based on a version identifier included in the call.
Case study - This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided. To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study. At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section. To start the case study - To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question. Company Overview - HipLocal is a community application designed to facilitate communication between people in close proximity. It is used for event planning and organizing sporting events, and for businesses to connect with their local communities. HipLocal launched recently in a few neighborhoods in Dallas and is rapidly growing into a global phenomenon. Its unique style of hyper-local community communication and business outreach is in demand around the world. Executive Statement - We are the number one local community app; it's time to take our local community services global. Our venture capital investors want to see rapid growth and the same great experience for new local and virtual communities that come online, whether their members are 10 or 10000 miles away from each other. Solution Concept - HipLocal wants to expand their existing service, with updated functionality, in new regions to better serve their global customers. They want to hire and train a new team to support these regions in their time zones. They will need to ensure that the application scales smoothly and provides clear uptime data. Existing Technical Environment - HipLocal's environment is a mix of on-premises hardware and infrastructure running in Google Cloud Platform. The HipLocal team understands their application well, but has limited experience in global scale applications. Their existing technical environment is as follows: * Existing APIs run on Compute Engine virtual machine instances hosted in GCP. * State is stored in a single instance MySQL database in GCP. * Data is exported to an on-premises Teradata/Vertica data warehouse. * Data analytics is performed in an on-premises Hadoop environment. * The application has no logging. * There are basic indicators of uptime; alerts are frequently fired when the APIs are unresponsive. Business Requirements - HipLocal's investors want to expand their footprint and support the increase in demand they are seeing. Their requirements are: * Expand availability of the application to new regions. * Increase the number of concurrent users that can be supported. * Ensure a consistent experience for users when they travel to different regions. * Obtain user activity metrics to better understand how to monetize their product. * Ensure compliance with regulations in the new regions (for example, GDPR). * Reduce infrastructure management time and cost. * Adopt the Google-recommended practices for cloud computing. Technical Requirements - * The application and backend must provide usage metrics and monitoring. * APIs require strong authentication and authorization. * Logging must be increased, and data should be stored in a cloud analytics platform. * Move to serverless architecture to facilitate elastic scaling. * Provide authorized access to internal apps in a secure manner. In order to meet their business requirements, how should HipLocal store their application state?
A. Use local SSDs to store state.
B. Put a memcache layer in front of MySQL.
C. Move the state storage to Cloud Spanner.
D. Replace the MySQL instance with Cloud SQL.
You developed a JavaScript web application that needs to access Google Drive's API and obtain permission from users to store files in their Google Drives. You need to select an authorization approach for your application. What should you do?
A. Create an API key.
B. Create a SAML token.
C. Create a service account.
D. Create an OAuth Client ID.
You are deploying a microservices application to Google Kubernetes Engine (GKE). The application will receive daily updates. You expect to deploy a large number of distinct containers that will run on the Linux operating system (OS). You want to be alerted to any known OS vulnerabilities in the new containers. You want to follow Google-recommended best practices. What should you do?
A. Use the gcloud CLI to call Container Analysis to scan new container images. Review the vulnerability results before each deployment.
B. Enable Container Analysis, and upload new container images to Artifact Registry. Review the vulnerability results before each deployment.
C. Enable Container Analysis, and upload new container images to Artifact Registry. Review the critical vulnerability results before each deployment.
D. Use the Container Analysis REST API to call Container Analysis to scan new container images. Review the vulnerability results before each deployment.
Your company’s product team has a new requirement based on customer demand to autoscale your stateless and distributed service running in a Google Kubernetes Engine (GKE) duster. You want to find a solution that minimizes changes because this feature will go live in two weeks. What should you do?
A. Deploy a Vertical Pod Autoscaler, and scale based on the CPU load.
B. Deploy a Vertical Pod Autoscaler, and scale based on a custom metric.
C. Deploy a Horizontal Pod Autoscaler, and scale based on the CPU toad.
D. Deploy a Horizontal Pod Autoscaler, and scale based on a custom metric.
You are developing an application that will allow clients to download a file from your website for a specific period of time. How should you design the application to complete this task while following Google-recommended best practices?
A. Configure the application to send the file to the client as an email attachment.
B. Generate and assign a Cloud Storage-signed URL for the file. Make the URL available for the client to download.
C. Create a temporary Cloud Storage bucket with time expiration specified, and give download permissions to the bucket. Copy the file, and send it to the client.
D. Generate the HTTP cookies with time expiration specified. If the time is valid, copy the file from the Cloud Storage bucket, and make the file available for the client to download.
You have two tables in an ANSI-SQL compliant database with identical columns that you need to quickly combine into a single table, removing duplicate rows from the result set. What should you do?
A. Use the JOIN operator in SQL to combine the tables.
B. Use nested WITH statements to combine the tables.
C. Use the UNION operator in SQL to combine the tables.
D. Use the UNION ALL operator in SQL to combine the tables.
Your organization has recently begun an initiative to replatform their legacy applications onto Google Kubernetes Engine. You need to decompose a monolithic application into microservices. Multiple instances have read and write access to a configuration file, which is stored on a shared file system. You want to minimize the effort required to manage this transition, and you want to avoid rewriting the application code. What should you do?
A. Create a new Cloud Storage bucket, and mount it via FUSE in the container.
B. Create a new persistent disk, and mount the volume as a shared PersistentVolume.
C. Create a new Filestore instance, and mount the volume as an NFS PersistentVolume.
D. Create a new ConfigMap and volumeMount to store the contents of the configuration file.
You manage your company's ecommerce platform's payment system, which runs on Google Cloud. Your company must retain user logs for 1 year for internal auditing purposes and for 3 years to meet compliance requirements. You need to store new user logs on Google Cloud to minimize on-premises storage usage and ensure that they are easily searchable. You want to minimize effort while ensuring that the logs are stored correctly. What should you do?
A. Store the logs in a Cloud Storage bucket with bucket lock turned on.
B. Store the logs in a Cloud Storage bucket with a 3-year retention period.
C. Store the logs in Cloud Logging as custom logs with a custom retention period.
D. Store the logs in a Cloud Storage bucket with a 1-year retention period. After 1 year, move the logs to another bucket with a 2-year retention period.
You are in the final stage of migrating an on-premises data center to Google Cloud. You are quickly approaching your deadline, and discover that a web API is running on a server slated for decommissioning. You need to recommend a solution to modernize this API while migrating to Google Cloud. The modernized web API must meet the following requirements: • Autoscales during high traffic periods at the end of each month • Written in Python 3.x • Developers must be able to rapidly deploy new versions in response to frequent code changes You want to minimize cost, effort, and operational overhead of this migration. What should you do?
A. Modernize and deploy the code on App Engine flexible environment.
B. Modernize and deploy the code on App Engine standard environment.
C. Deploy the modernized application to an n1-standard-1 Compute Engine instance.
D. Ask the development team to re-write the application to run as a Docker container on Google Kubernetes Engine.
Your application is logging to Stackdriver. You want to get the count of all requests on all /api/alpha/* endpoints. What should you do?
A. Add a Stackdriver counter metric for path:/api/alpha/.
B. Add a Stackdriver counter metric for endpoint:/api/alpha/*.
C. Export the logs to Cloud Storage and count lines matching /api/alpha.
D. Export the logs to Cloud Pub/Sub and count lines matching /api/alpha.
You are a lead developer working on a new retail system that runs on Cloud Run and Firestore. A web UI requirement is for the user to be able to browse through all products. A few months after go-live, you notice that Cloud Run instances are terminated with HTTP 500: Container instances are exceeding memory limits errors during busy times. This error coincides with spikes in the number of Firestore queries. You need to prevent Cloud Run from crashing and decrease the number of Firestore queries. You want to use a solution that optimizes system performance. What should you do?
A. Modify the query that returns the product list using cursors with limits.
B. Create a custom index over the products.
C. Modify the query that returns the product list using integer offsets.
D. Modify the Cloud Run configuration to increase the memory limits.
Your application is deployed in a Google Kubernetes Engine (GKE) cluster. You want to expose this application publicly behind a Cloud Load Balancing HTTP(S) load balancer. What should you do?
A. Configure a GKE Ingress resource.
B. Configure a GKE Service resource.
C. Configure a GKE Ingress resource with type: LoadBalancer.
D. Configure a GKE Service resource with type: LoadBalancer.
You are developing an HTTP API hosted on a Compute Engine virtual machine instance that needs to be invoked by multiple clients within the same Virtual Private Cloud (VPC). You want clients to be able to get the IP address of the service. What should you do?
A. Reserve a static external IP address and assign it to an HTTP(S) load balancing service’s forwarding rule. Clients should use this IP address to connect to the service.
B. Reserve a static external IP address and assign it to an HTTP(S) load balancing service’s forwarding rule. Then, define an A record in Cloud DNS. Clients should use the name of the A record to connect to the service.
C. Ensure that clients use Compute Engine internal DNS by connecting to the instance name with the url https://[INSTANCE_NAME].[ZONE].c. [PROJECT_ID].internal/.
D. Ensure that clients use Compute Engine internal DNS by connecting to the instance name with the url https://[API_NAME]/[API_VERSION]/.
You manage a microservice-based ecommerce platform on Google Cloud that sends confirmation emails to a third-party email service provider using a Cloud Function. Your company just launched a marketing campaign, and some customers are reporting that they have not received order confirmation emails. You discover that the services triggering the Cloud Function are receiving HTTP 500 errors. You need to change the way emails are handled to minimize email loss. What should you do?
A. Increase the Cloud Function’s timeout to nine minutes.
B. Configure the sender application to publish the outgoing emails in a message to a Pub/Sub topic. Update the Cloud Function configuration to consume the Pub/Sub queue.
C. Configure the sender application to write emails to Memorystore and then trigger the Cloud Function. When the function is triggered, it reads the email details from Memorystore and sends them to the email service.
D. Configure the sender application to retry the execution of the Cloud Function every one second if a request fails.
You want to upload files from an on-premises virtual machine to Google Cloud Storage as part of a data migration. These files will be consumed by Cloud DataProc Hadoop cluster in a GCP environment. Which command should you use?
A. gsutil cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
B. gcloud cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
C. hadoop fs cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
D. gcloud dataproc cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
Your team is developing an application in Google Cloud that executes with user identities maintained by Cloud Identity. Each of your application's users will have an associated Pub/Sub topic to which messages are published, and a Pub/Sub subscription where the same user will retrieve published messages. You need to ensure that only authorized users can publish and subscribe to their own specific Pub/Sub topic and subscription. What should you do?
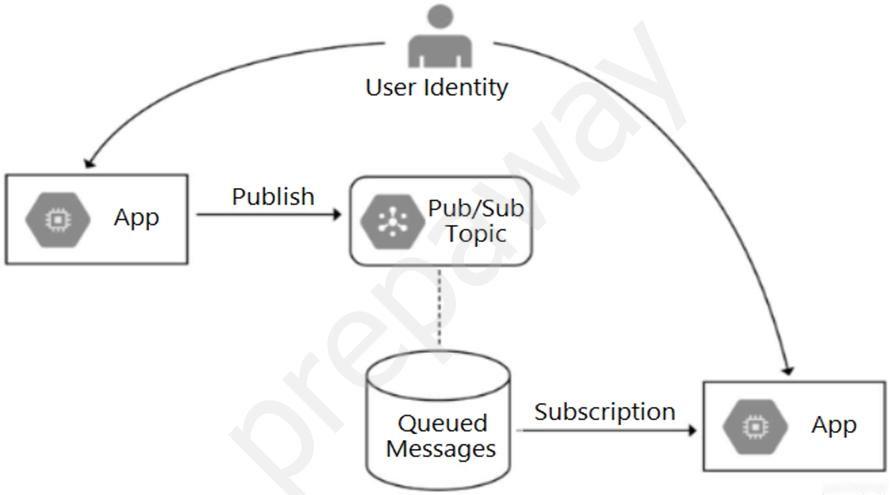
A. Bind the user identity to the pubsub.publisher and pubsub.subscriber roles at the resource level.
B. Grant the user identity the pubsub.publisher and pubsub.subscriber roles at the project level.
C. Grant the user identity a custom role that contains the pubsub.topics.create and pubsub.subscriptions.create permissions.
D. Configure the application to run as a service account that has the pubsub.publisher and pubsub.subscriber roles.
You are developing a web application that will be accessible over both HTTP and HTTPS and will run on Compute Engine instances. On occasion, you will need to SSH from your remote laptop into one of the Compute Engine instances to conduct maintenance on the app. How should you configure the instances while following Google-recommended best practices?
A. Set up a backend with Compute Engine web server instances with a private IP address behind a TCP proxy load balancer.
B. Configure the firewall rules to allow all ingress traffic to connect to the Compute Engine web servers, with each server having a unique external IP address.
C. Configure Cloud Identity-Aware Proxy API for SSH access. Then configure the Compute Engine servers with private IP addresses behind an HTTP(s) load balancer for the application web traffic.
D. Set up a backend with Compute Engine web server instances with a private IP address behind an HTTP(S) load balancer. Set up a bastion host with a public IP address and open firewall ports. Connect to the web instances using the bastion host.
You are tasked with using C++ to build and deploy a microservice for an application hosted on Google Cloud. The codefineeds to be containerized and use several custom software libraries that your team has built. You do not want to maintain the underlying infrastructure of the application. How should you deploy the microservice?
A. Use Cloud Functions to deploy the microservice.
B. Use Cloud Build to create the container, and deploy it on Cloud Run.
C. Use Cloud Shell to containerize your microservice, and deploy it on a Container-Optimized OS Compute Engine instance.
D. Use Cloud Shell to containerize your microservice, and deploy it on standard Google Kubernetes Engine.
Case study - This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided. To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study. At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section. To start the case study - To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question. Company Overview - HipLocal is a community application designed to facilitate communication between people in close proximity. It is used for event planning and organizing sporting events, and for businesses to connect with their local communities. HipLocal launched recently in a few neighborhoods in Dallas and is rapidly growing into a global phenomenon. Its unique style of hyper-local community communication and business outreach is in demand around the world. Executive Statement - We are the number one local community app; it's time to take our local community services global. Our venture capital investors want to see rapid growth and the same great experience for new local and virtual communities that come online, whether their members are 10 or 10000 miles away from each other. Solution Concept - HipLocal wants to expand their existing service, with updated functionality, in new regions to better serve their global customers. They want to hire and train a new team to support these regions in their time zones. They will need to ensure that the application scales smoothly and provides clear uptime data. Existing Technical Environment - HipLocal's environment is a mix of on-premises hardware and infrastructure running in Google Cloud Platform. The HipLocal team understands their application well, but has limited experience in global scale applications. Their existing technical environment is as follows: * Existing APIs run on Compute Engine virtual machine instances hosted in GCP. * State is stored in a single instance MySQL database in GCP. * Data is exported to an on-premises Teradata/Vertica data warehouse. * Data analytics is performed in an on-premises Hadoop environment. * The application has no logging. * There are basic indicators of uptime; alerts are frequently fired when the APIs are unresponsive. Business Requirements - HipLocal's investors want to expand their footprint and support the increase in demand they are seeing. Their requirements are: * Expand availability of the application to new regions. * Increase the number of concurrent users that can be supported. * Ensure a consistent experience for users when they travel to different regions. * Obtain user activity metrics to better understand how to monetize their product. * Ensure compliance with regulations in the new regions (for example, GDPR). * Reduce infrastructure management time and cost. * Adopt the Google-recommended practices for cloud computing. Technical Requirements - * The application and backend must provide usage metrics and monitoring. * APIs require strong authentication and authorization. * Logging must be increased, and data should be stored in a cloud analytics platform. * Move to serverless architecture to facilitate elastic scaling. * Provide authorized access to internal apps in a secure manner. HipLocal's APIs are having occasional application failures. They want to collect application information specifically to troubleshoot the issue. What should they do?
A. Take frequent snapshots of the virtual machines.
B. Install the Cloud Logging agent on the virtual machines.
C. Install the Cloud Monitoring agent on the virtual machines.
D. Use Cloud Trace to look for performance bottlenecks.
You are a developer working with the CI/CD team to troubleshoot a new feature that your team introduced. The CI/CD team used HashiCorp Packer to create a new Compute Engine image from your development branch. The image was successfully built, but is not booting up. You need to investigate the issue with the CI/ CD team. What should you do?
A. Create a new feature branch, and ask the build team to rebuild the image.
B. Shut down the deployed virtual machine, export the disk, and then mount the disk locally to access the boot logs.
C. Install Packer locally, build the Compute Engine image locally, and then run it in your personal Google Cloud project.
D. Check Compute Engine OS logs using the serial port, and check the Cloud Logging logs to confirm access to the serial port.
You have an application deployed in Google Kubernetes Engine (GKE) that reads and processes Pub/Sub messages. Each Pod handles a fixed number of messages per minute. The rate at which messages are published to the Pub/Sub topic varies considerably throughout the day and week, including occasional large batches of messages published at a single moment. You want to scale your GKE Deployment to be able to process messages in a timely manner. What GKE feature should you use to automatically adapt your workload?
A. Vertical Pod Autoscaler in Auto mode
B. Vertical Pod Autoscaler in Recommendation mode
C. Horizontal Pod Autoscaler based on an external metric
D. Horizontal Pod Autoscaler based on resources utilization
Free Access Full Google Professional Cloud Developer Practice Exam Free
Looking for additional practice? Click here to access a full set of Google Professional Cloud Developer practice exam free questions and continue building your skills across all exam domains.
Our question sets are updated regularly to ensure they stay aligned with the latest exam objectives—so be sure to visit often!
Good luck with your Google Professional Cloud Developer certification journey!