DP-900 Practice Questions Free – 50 Exam-Style Questions to Sharpen Your Skills
Are you preparing for the DP-900 certification exam? Kickstart your success with our DP-900 Practice Questions Free – a carefully selected set of 50 real exam-style questions to help you test your knowledge and identify areas for improvement.
Practicing with DP-900 practice questions free gives you a powerful edge by allowing you to:
Understand the exam structure and question formats
Discover your strong and weak areas
Build the confidence you need for test day success
Below, you will find 50 free DP-900 practice questions designed to match the real exam in both difficulty and topic coverage. They’re ideal for self-assessment or final review. You can click on each Question to explore the details.
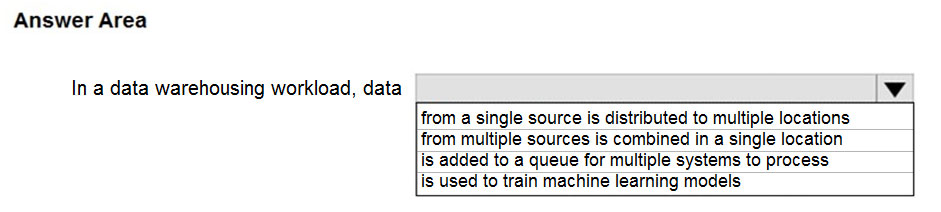
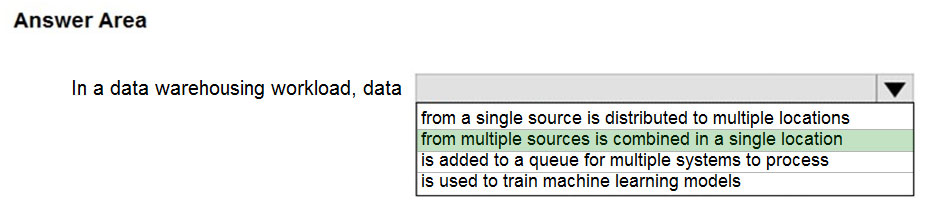
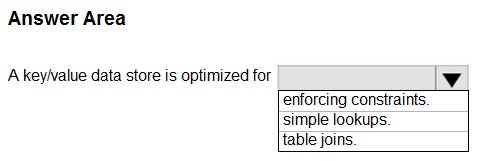
HOTSPOT -
Select the answer that correctly completes the sentence.
Hot Area:
Suggested Answer:
A key/value store associates each data value with a unique key.
Key/value stores are highly optimized for applications performing simple lookups, but are less suitable if you need to query data across different key/value stores.
Key/value stores are also not optimized for querying by value.
A single key/value store can be extremely scalable, as the data store can easily distribute data across multiple nodes on separate machines.
Reference: https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
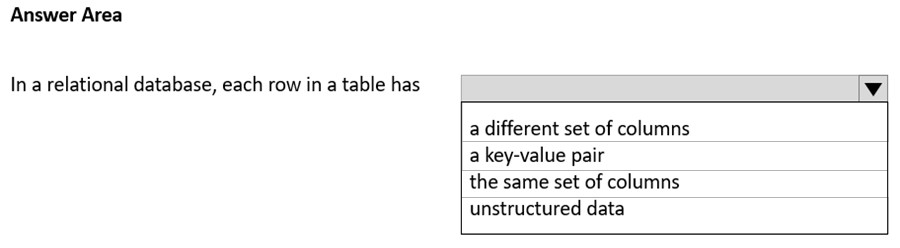
HOTSPOT -
Select the answer that correctly completes the sentence.
Hot Area:
Suggested Answer:
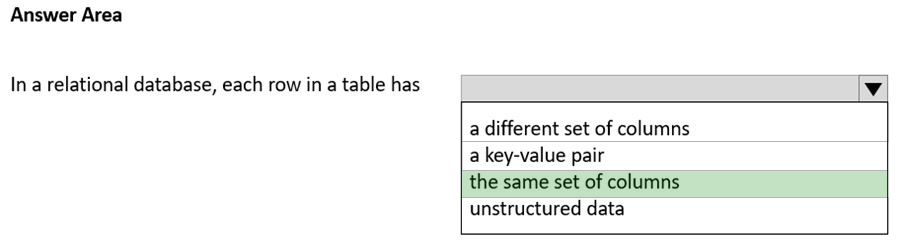
The same set of columns.
In relational databases, a row is a data record within a table. Each row, which represents a complete record of specific item data, holds different data within the same structure. A row is occasionally referred to as a tuple.
Incorrect:
Not: a key value pair.
Unlike relational databases, key-value databases do not have a specified structure. Relational databases store data in tables where each column has an assigned data type. Key-value databases are a collection of key-value pairs that are stored as individual records and do not have a predefined data structure.
Reference: https://www.techopedia.com/definition/4425/database-row
You have an on-premises Microsoft SQL Server database.
You need to migrate the database to the cloud. The solution must meet the following requirements:
* Minimize maintenance effort.
* Support the Database Mail and Service Broker features.
What should you include in the solution?
DRAG DROP -
Match the Azure services to the appropriate requirements.
To answer, drag the appropriate service from the column on the left to its requirement on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Select and Place:
Suggested Answer:
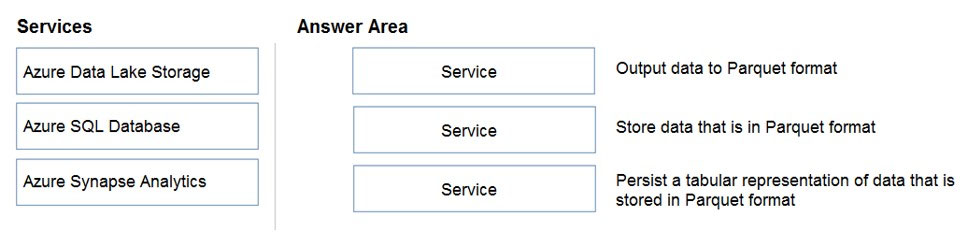
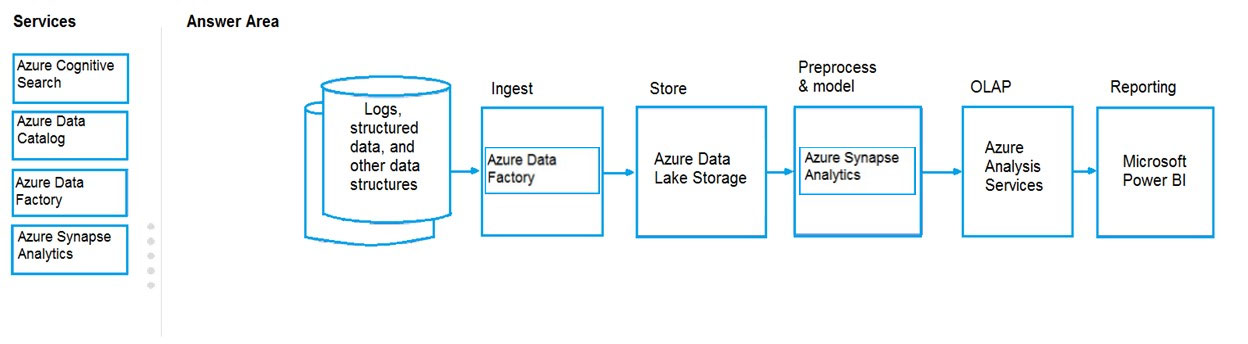
Box 1: Azure Data Factory –
Box 2: Azure Data Lake Storage –
Azure Data Lake Storage (ADLA) now natively supports Parquet files. ADLA adds a public preview of the native extractor and outputter for the popular Parquet file format
Box 3: Azure Synapse Analytics –
Use Azure Synapse Analytics Workspaces.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/supported-file-formats-and-compression-codecs
C. provides built-in or native online analytical processing
D. stores raw data only
Suggested Answer: C
A data warehouse is a centralized repository of integrated data from one or more disparate sources. Data warehouses store current and historical data and are used for reporting and analysis of the data.
The purpose of the analytical data store layer is to satisfy queries issued by analytics and reporting tools against the data warehouse.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/data-warehousing
You have an application that runs on Windows and requires access to a mapped drive.
Which Azure service should you use?
A. Azure Files
B. Azure Blob storage
C. Azure Cosmos DB
D. Azure Table storage
Suggested Answer: A
Azure Files is Microsoft’s easy-to-use cloud file system. Azure file shares can be seamlessly used in Windows and Windows Server.
To use an Azure file share with Windows, you must either mount it, which means assigning it a drive letter or mount point path, or access it via its UNC path.
Reference: https://docs.microsoft.com/en-us/azure/storage/files/storage-how-to-use-files-windows
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
DRAG DROP -
Match the Azure services to the appropriate locations in the architecture.
To answer, drag the appropriate service from the column on the left to its location on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Select and Place:
You need to create an Azure Storage account.
Data in the account must replicate outside the Azure region automatically.
Which two types of replication can you use for the storage account? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. zone-redundant storage (ZRS)
B. read-access geo-redundant storage (RA-GRS)
C. locally-redundant storage (LRS)
D. geo-redundant storage (GRS)
Suggested Answer: BD
D: Azure Storage offers two options for copying your data to a secondary region:
✑ Geo-redundant storage (GRS)
✑ Geo-zone-redundant storage (GZRS)
B: With GRS or GZRS, the data in the secondary region isn’t available for read or write access unless there is a failover to the secondary region. For read access to the secondary region, configure your storage account to use read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-
GZRS).
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy#redundancy-in-a-secondary-region
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Yes –
Azure Databricks can consume data from SQL Databases using JDBC and from SQL Databases using the Apache Spark connector.
The Apache Spark connector for Azure SQL Database and SQL Server enables these databases to act as input data sources and output data sinks for Apache
Spark jobs.
Box 2: Yes –
You can stream data into Azure Databricks using Event Hubs.
Box 3: Yes –
You can run Spark jobs with data stored in Azure Cosmos DB using the Cosmos DB Spark connector. Cosmos can be used for batch and stream processing, and as a serving layer for low latency access.
You can use the connector with Azure Databricks or Azure HDInsight, which provide managed Spark clusters on Azure.
Reference: https://docs.microsoft.com/en-us/azure/databricks/data/data-sources/sql-databases-azure https://docs.microsoft.com/en-us/azure/databricks/scenarios/databricks-stream-from-eventhubs
DRAG DROP
-
Match the job roles to the appropriate tasks.
To answer, drag the appropriate role from the column on the left to its task on the right. Each role may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
DRAG DROP
-
Match the job roles to the appropriate tasks.
To answer, drag the appropriate role from the column on the left to its task on the right. Each role may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: No –
Database normalization is the process of restructuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
Full normalisation will generally not improve performance, in fact it can often make it worse but it will keep your data duplicate free.
Box 2: No –
Analytics systems are deformalized to increase performance.
Transactional database systems are normalized to increase data consistency.
Box 3: Yes –
Transactional database systems are more normalized and requires more joins.
Reference: https://www.sqlshack.com/what-is-database-normalization-in-sql-server
HOTSPOT
-
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
You need to query a table named Products in an Azure SQL database.
Which three requirements must be met to query the table from the internet? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. You must be assigned the Reader role for the resource group that contains the database.
B. You must have SELECT access to the Products table.
C. You must have a user in the database.
D. You must be assigned the Contributor role for the resource group that contains the database.
E. Your IP address must be allowed to connect to the database.
You are deploying a software as a service (SaaS) application that requires a relational database for Online Transaction Processing (OLTP).
Which Azure service should you use to support the application?
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
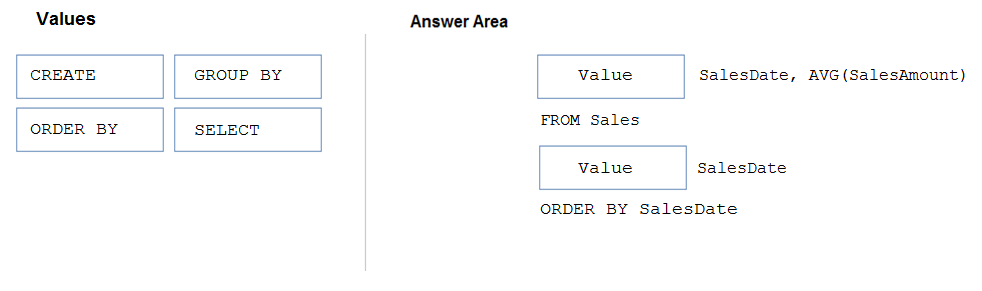
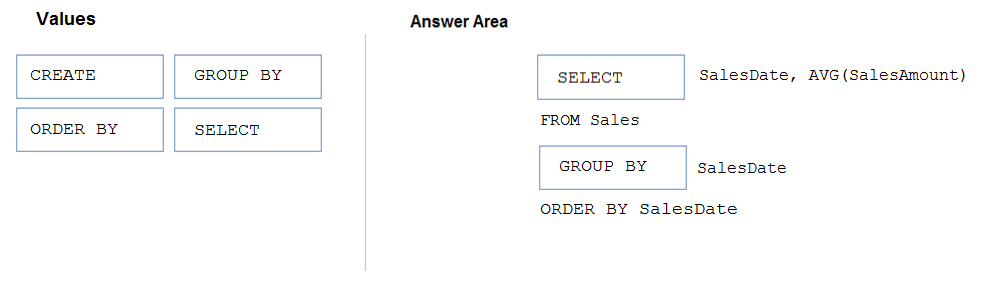
DRAG DROP -
You have a table named Sales that contains the following data.
You need to query the table to return the average sales amount per day. The output must produce the following results.
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: SELECT –
Box 2: GROUP BY –
Example:
When used with a GROUP BY clause, each aggregate function produces a single value covering each group, instead of a single value covering the whole table.
The following example produces summary values for each sales territory in the AdventureWorks2012 database. The summary lists the average bonus received by the sales people in each territory, and the sum of year-to-date sales for each territory.
SELECT TerritoryID, AVG(Bonus)as ‘Average bonus’, SUM(SalesYTD) as ‘YTD sales’
FROM Sales.SalesPerson –
GROUP BY TerritoryID;
Reference: https://docs.microsoft.com/en-us/sql/t-sql/functions/avg-transact-sql
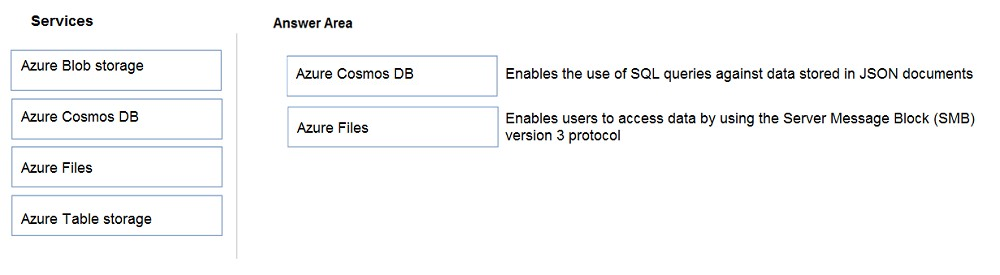
DRAG DROP -
Match the datastore services to the appropriate descriptions.
To answer, drag the appropriate service from the column on the left to its description on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Select and Place:
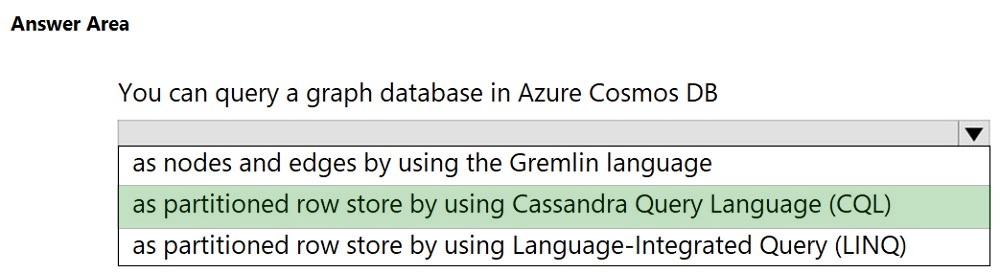
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: No –
The API determines the type of account to create. Azure Cosmos DB provides five APIs: Core (SQL) and MongoDB for document data, Gremlin for graph data,
Azure Table, and Cassandra. Currently, you must create a separate account for each API.
Box 2: Yes –
Azure Cosmos DB uses partitioning to scale individual containers in a database to meet the performance needs of your application. In partitioning, the items in a container are divided into distinct subsets called logical partitions. Logical partitions are formed based on the value of a partition key that is associated with each item in a container.
Box 3: No –
Logical partitions are formed based on the value of a partition key that is associated with each item in a container.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/partitioning-overview
HOTSPOT -
To complete the sentence, select the appropriate option in the answer area.
Hot Area:
Suggested Answer:
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on your computer is organized. With a hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace
HOTSPOT -
To complete the sentence, select the appropriate option in the answer area.
Hot Area:
Suggested Answer:
When to use batch processing.
You might expect latencies when using batch processing. For many situations, however, this type of delay before the transfer of data begins is not a big issue – the processes that use this function are not mission critical at the exact moment.
Reference: https://www.bmc.com/blogs/what-is-batch-processing-batch-processing-explained/
Which command-line tool can you use to query Azure SQL databases?
A. sqlcmd
B. bcp
C. azdata
D. Azure CLI
Suggested Answer: A
The sqlcmd utility lets you enter Transact-SQL statements, system procedures, and script files at the command prompt.
Incorrect Answers:
B: The bulk copy program utility (bcp) bulk copies data between an instance of Microsoft SQL Server and a data file in a user-specified format.
D: The Azure CLI is the defacto tool for cross-platform and command-line tools for building and managing Azure resources.
Reference: https://docs.microsoft.com/en-us/sql/tools/overview-sql-tools?view=sql-server-ver15
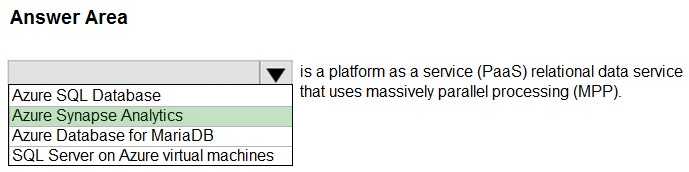
HOTSPOT -
Select the answer that correctly completes the sentence.
Hot Area:
Suggested Answer:
Azure Synapse Analytics is an platform as a service (PAAS) that combines data integration, warehousing, and analytics into one solution.
Azure Synapse Analytics offers cloud-based, relational data warehousing services, massively parallel processing (MPP) scale-out technology, and enough computational power to efficiently manage petabytes and petabytes of data.
Incorrect:
* Azure Database for MariaDB is a relational database service based on the open-source MariaDB Server engine. It’s a fully managed database as a service offering that can handle mission-critical workloads with predictable performance and dynamic scalability.
* Azure SQL Database is a fully managed platform as a service (PaaS) database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. Azure SQL Database is always running on the latest stable version of the SQL Server database engine and patched OS with 99.99% availability. PaaS capabilities built into Azure SQL Database enable you to focus on the domain-specific database administration and optimization activities that are critical for your business.
Reference: https://cswsolutions.com/blog/posts/2021/august/what-is-azure-synapse-analytics/ https://www.integrate.io/blog/what-is-azure-synapse-analytics/
DRAG DROP
-
Match the Azure Cosmos DB APIs to the appropriate data structures.
To answer, drag the appropriate API from the column on the left to its data structure on the right. Each API may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
DRAG DROP -
Match the processes to the appropriate scenarios.
To answer, drag the appropriate process from the column on the left to its scenario on the right. Each process may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Select and Place:
Want more hands-on practice? Click here to access the full bank of DP-900 practice questions free and reinforce your understanding of all exam objectives.
We update our question sets regularly, so check back often for new and relevant content.












Which type of data store should you use?





















You need to query the table to return the average sales amount per day. The output must produce the following results.
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
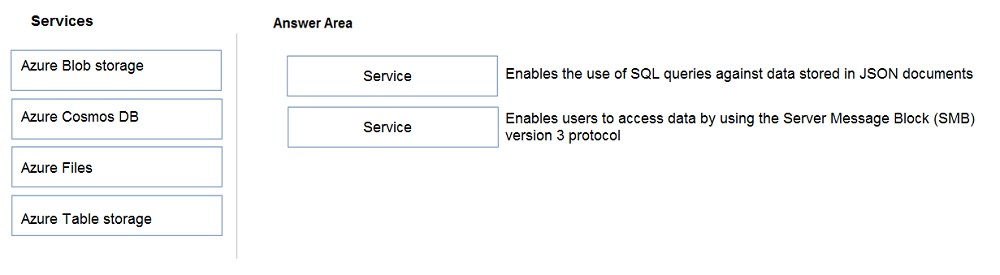















What should you create in Power BI Desktop?