

DP-203 Practice Questions Free – 50 Exam-Style Questions to Sharpen Your Skills
Are you preparing for the DP-203 certification exam? Kickstart your success with our DP-203 Practice Questions Free – a carefully selected set of 50 real exam-style questions to help you test your knowledge and identify areas for improvement.
Practicing with DP-203 practice questions free gives you a powerful edge by allowing you to:
- Understand the exam structure and question formats
- Discover your strong and weak areas
- Build the confidence you need for test day success
Below, you will find 50 free DP-203 practice questions designed to match the real exam in both difficulty and topic coverage. They’re ideal for self-assessment or final review. You can click on each Question to explore the details.
HOTSPOT - You are designing an Azure Synapse Analytics dedicated SQL pool. Groups will have access to sensitive data in the pool as shown in the following table.You have policies for the sensitive data. The policies vary be region as shown in the following table.
You have a table of patients for each region. The tables contain the following potentially sensitive columns.
You are designing dynamic data masking to maintain compliance. For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL. ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL. ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R. The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in an Azure Data Lake Storage Gen2 container. Which type of trigger should you use?
A. on-demand
B. tumbling window
C. schedule
D. event
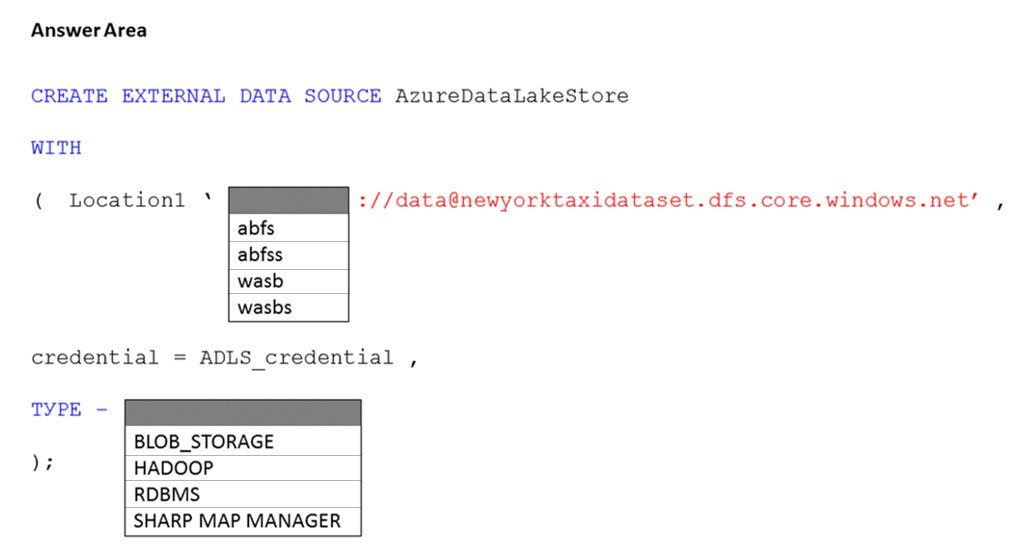
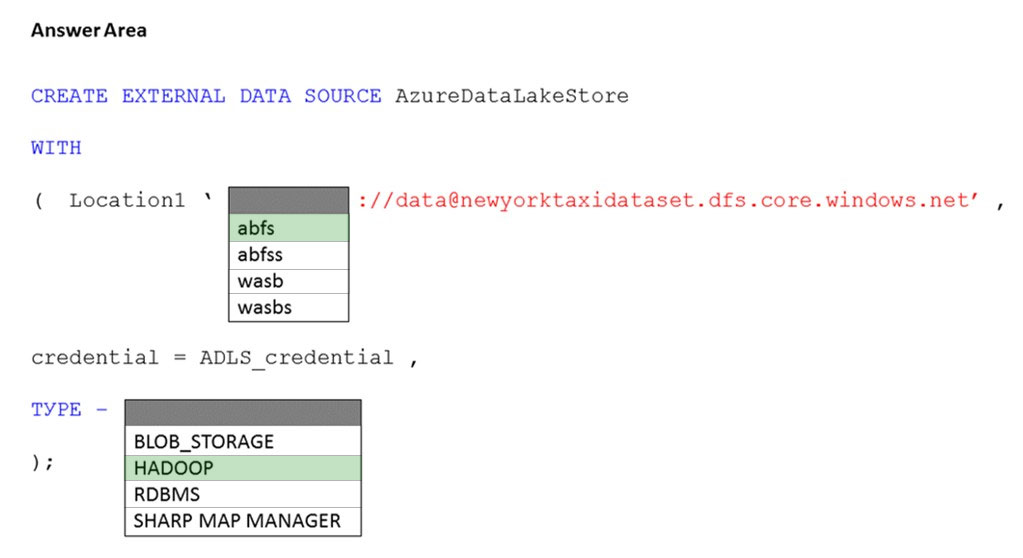
HOTSPOT - You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage account named storage1. Storage1 requires secure transfers. You need to create an external data source in Pool1 that will be used to read .orc files in storage1. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.FactPurchase will have 1 million rows of data added daily and will contain three years of data. Transact-SQL queries similar to the following query will be executed daily. SELECT - SupplierKey, StockItemKey, IsOrderFinalized, COUNT(*) FROM FactPurchase - WHERE DateKey >= 20210101 - AND DateKey <= 20210131 - GROUP By SupplierKey, StockItemKey, IsOrderFinalized Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on IsOrderFinalized
You have an Azure Databricks workspace and an Azure Data Lake Storage Gen2 account named storage1. New files are uploaded daily to storage1. You need to recommend a solution that configures storage1 as a structured streaming source. The solution must meet the following requirements: • Incrementally process new files as they are uploaded to storage1. • Minimize implementation and maintenance effort. • Minimize the cost of processing millions of files. • Support schema inference and schema drift. Which should you include in the recommendation?
A. COPY INTO
B. Azure Data Factory
C. Auto Loader
D. Apache Spark FileStreamSource
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices. The company must be able to monitor the devices in real-time. You need to design the solution. What should you recommend?
A. Azure Analysis Services using Azure PowerShell
B. Azure Stream Analytics Edge application using Microsoft Visual Studio
C. Azure Analysis Services using Microsoft Visual Studio
D. Azure Data Factory instance using Azure Portal
You are designing an inventory updates table in an Azure Synapse Analytics dedicated SQL pool. The table will have a clustered columnstore index and will include the following columns:You identify the following usage patterns: ✑ Analysts will most commonly analyze transactions for a warehouse. ✑ Queries will summarize by product category type, date, and/or inventory event type. You need to recommend a partition strategy for the table to minimize query times. On which column should you partition the table?
A. EventTypeID
B. ProductCategoryTypeID
C. EventDate
D. WarehouseID
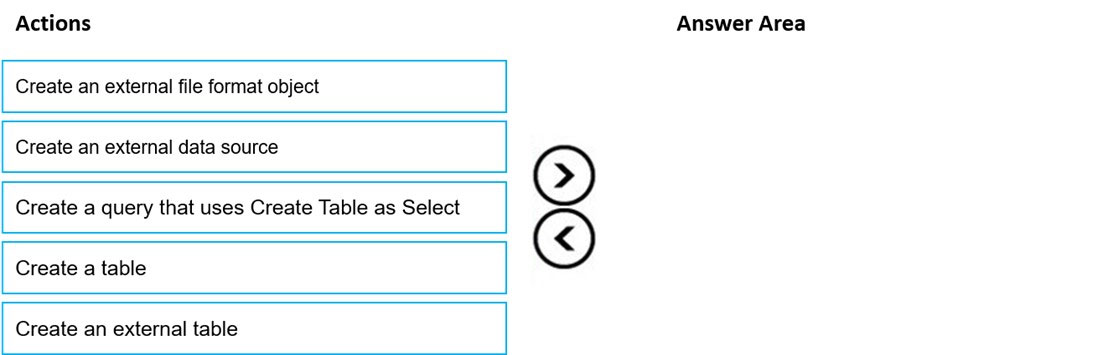
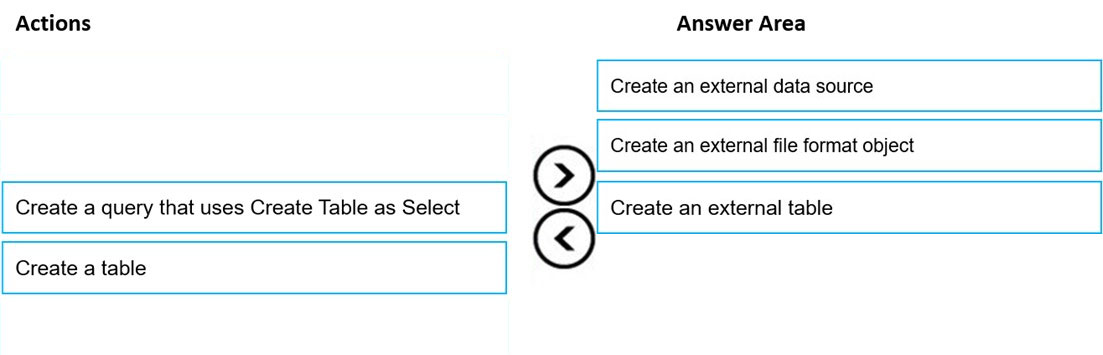
DRAG DROP - You need to build a solution to ensure that users can query specific files in an Azure Data Lake Storage Gen2 account from an Azure Synapse Analytics serverless SQL pool. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:
You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU % Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Backlogged Input Events
B. Watermark Delay
C. Function Events
D. Out of order Events
E. Late Input Events
DRAG DROP - You need to ensure that the Twitter feed data can be analyzed in the dedicated SQL pool. The solution must meet the customer sentiment analytics requirements. Which three Transact-SQL DDL commands should you run in sequence? To answer, move the appropriate commands from the list of commands to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:


You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Contacts. Contacts contains a column named Phone. You need to ensure that users in a specific role only see the last four digits of a phone number when querying the Phone column. What should you include in the solution?
A. table partitions
B. a default value
C. row-level security (RLS)
D. column encryption
E. dynamic data masking
You need to design a solution that will process streaming data from an Azure Event Hub and output the data to Azure Data Lake Storage. The solution must ensure that analysts can interactively query the streaming data. What should you use?
A. Azure Stream Analytics and Azure Synapse notebooks
B. Structured Streaming in Azure Databricks
C. event triggers in Azure Data Factory
D. Azure Queue storage and read-access geo-redundant storage (RA-GRS)
You have an Azure subscription that contains a storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool. The storage1 account contains a CSV file that requires an account key for access. You plan to read the contents of the CSV file by using an external table. You need to create an external data source for the external table. What should you create first?
A. a database role
B. a database scoped credential
C. a database view
D. an external file format
You are designing the folder structure for an Azure Data Lake Storage Gen2 account. You identify the following usage patterns: • Users will query data by using Azure Synapse Analytics serverless SQL pools and Azure Synapse Analytics serverless Apache Spark pools. • Most queries will include a filter on the current year or week. • Data will be secured by data source. You need to recommend a folder structure that meets the following requirements: • Supports the usage patterns • Simplifies folder security • Minimizes query times Which folder structure should you recommend?
A. DataSourceSubjectAreaYYYYWWFileData_YYYY_MM_DD.parquet
B. DataSourceSubjectAreaYYYY-WWFileData_YYYY_MM_DD.parquet
C. DataSourceSubjectAreaWWYYYYFileData_YYYY_MM_DD.parquet
D. YYYYWWDataSourceSubjectAreaFileData_YYYY_MM_DD.parquet
E. WWYYYYSubjectAreaDataSourceFileData_YYYY_MM_DD.parquet
You are performing exploratory analysis of the bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool. You execute the Transact-SQL query shown in the following exhibit.What do the query results include?
A. Only CSV files in the tripdata_2020 subfolder.
B. All files that have file names that beginning with “tripdata_2020”.
C. All CSV files that have file names that contain “tripdata_2020”.
D. Only CSV that have file names that beginning with “tripdata_2020”.
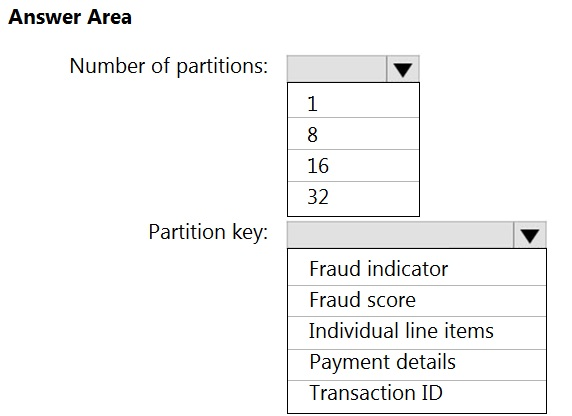
HOTSPOT - You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as the partition key. You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the payment details, a fraud score, and a fraud indicator. You plan to send the output to an Azure event hub named fraudhub. You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as possible. How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

HOTSPOT - You have an Azure subscription that contains the resources shown in the following table.The storage1 account contains a container named container1. The container1 container contains the following files.
In Pool1, you run the following script.
In the Built-in serverless SQL pool, you run the following script.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You have an Azure subscription that is linked to a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant that contains a security group named Group1. The subscription contains an Azure Data Lake Storage account named myaccount1. The myaccount1 account contains two containers named container1 and container2. You need to grant Group1 read access to container1. The solution must use the principle of least privilege. Which role should you assign to Group1?
A. Storage Table Data Reader for myaccount1
B. Storage Blob Data Reader for container1
C. Storage Blob Data Reader for myaccount1
D. Storage Table Data Reader for container1
HOTSPOT - You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool. You plan to deploy a solution that will analyze sales data and include the following: • A table named Country that will contain 195 rows • A table named Sales that will contain 100 million rows • A query to identify total sales by country and customer from the past 30 days You need to create the tables. The solution must maximize query performance. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


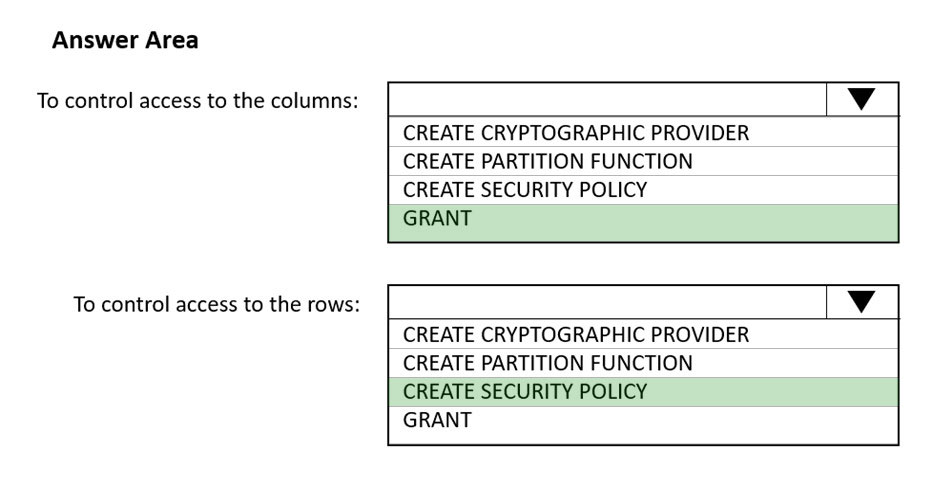
HOTSPOT - You have an Azure Synapse Analytics SQL pool named Pool1. In Azure Active Directory (Azure AD), you have a security group named Group1. You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

A company plans to use Apache Spark analytics to analyze intrusion detection data. You need to recommend a solution to analyze network and system activity data for malicious activities and policy violations. The solution must minimize administrative efforts. What should you recommend?
A. Azure HDInsight
B. Azure Data Factory
C. Azure Data Lake Storage
D. Azure Databricks
You have an Azure subscription that contains an Azure Blob Storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool named Pool1. You need to store data in storage1. The data will be read by Pool1. The solution must meet the following requirements: Enable Pool1 to skip columns and rows that are unnecessary in a query.✑ Automatically create column statistics. ✑ Minimize the size of files. Which type of file should you use?
A. JSON
B. Parquet
C. Avro
D. CSV
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 receives new data once every 24 hours. You have the following function.You have the following query.
The query is executed once every 15 minutes and the @parameter value is set to the current date. You need to minimize the time it takes for the query to return results. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create an index on the avg_f column.
B. Convert the avg_c column into a calculated column.
C. Create an index on the sensorid column.
D. Enable result set caching.
E. Change the table distribution to replicate.
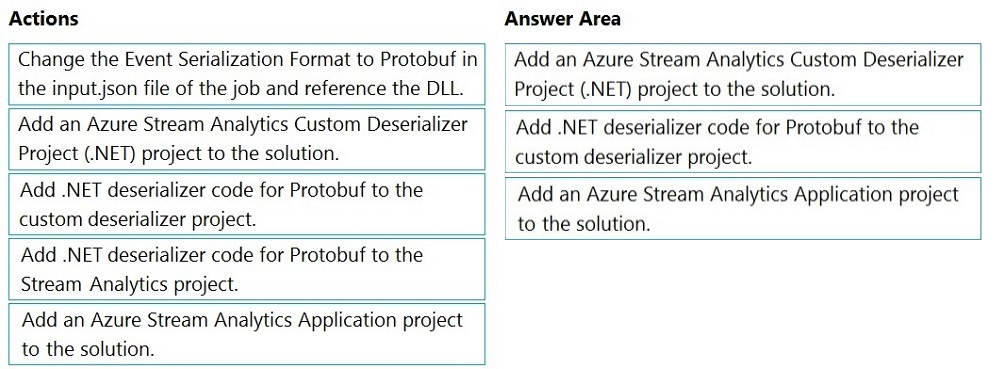
DRAG DROP - You have an Azure Stream Analytics job that is a Stream Analytics project solution in Microsoft Visual Studio. The job accepts data generated by IoT devices in the JSON format. You need to modify the job to accept data generated by the IoT devices in the Protobuf format. Which three actions should you perform from Visual Studio on sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You are designing a solution that will use tables in Delta Lake on Azure Databricks. You need to minimize how long it takes to perform the following: • Queries against non-partitioned tables • Joins on non-partitioned columns Which two options should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. the clone command
B. Z-Ordering
C. Apache Spark caching
D. dynamic file pruning (DFP)
HOTSPOT - You have Azure Data Factory configured with Azure Repos Git integration. The collaboration branch and the publish branch are set to the default values. You have a pipeline named pipeline1. You build a new version of pipeline1 in a branch named feature1. From the Data Factory Studio, you select Publish. The source code of which branch will be built, and which branch will contain the output of the Azure Resource Manager (ARM) template? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You have an Azure Synapse Analytics serverless SQL pool. You have an Apache Parquet file that contains 10 columns. You need to query data from the file. The solution must return only two columns. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You manage an enterprise data warehouse in Azure Synapse Analytics. Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries. You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
A. Local tempdb percentage
B. Cache used percentage
C. Data IO percentage
D. CPU percentage
HOTSPOT - You plan to use an Azure Data Lake Storage Gen2 account to implement a Data Lake development environment that meets the following requirements: • Read and write access to data must be maintained if an availability zone becomes unavailable. • Data that was last modified more than two years ago must be deleted automatically. • Costs must be minimized. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have a Log Analytics workspace named la1 and an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 sends logs to la1. You need to identify whether a recently executed query on Pool1 used the result set cache. What are two ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Review the sys.dm_pdw_sql_requests dynamic management view in Pool1.
B. Review the sys.dm_pdw_exec_requests dynamic management view in Pool1.
C. Use the Monitor hub in Synapse Studio.
D. Review the AzureDiagnostics table in la1.
E. Review the sys.dm_pdw_request_steps dynamic management view in Pool1.
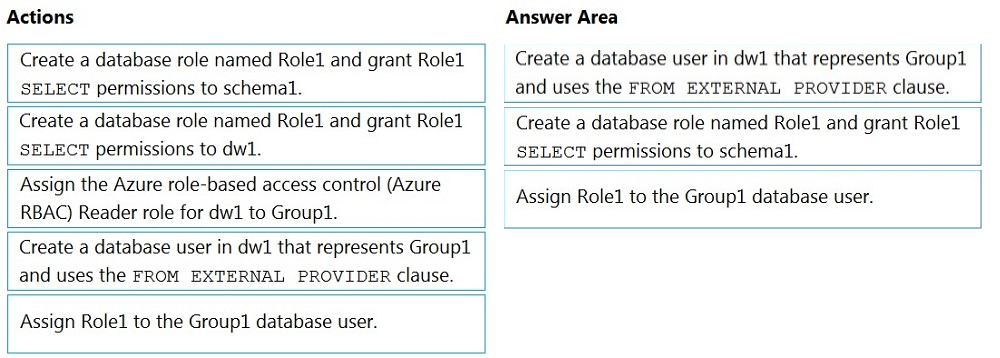
DRAG DROP - You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1. You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:

A company uses Azure Stream Analytics to monitor devices. The company plans to double the number of devices that are monitored. You need to monitor a Stream Analytics job to ensure that there are enough processing resources to handle the additional load. Which metric should you monitor?
A. Early Input Events
B. Late Input Events
C. Watermark delay
D. Input Deserialization Errors
You have a Microsoft Entra tenant. The tenant contains an Azure Data Lake Storage Gen2 account named storage1 that has two containers named fs1 and fs2. You have a Microsoft Entra group named DepartmentA. You need to meet the following requirements: • DepartmentA must be able to read, write, and list all the files in fs1. • DepartmentA must be prevented from accessing any files in fs2. • The solution must use the principle of least privilege. Which role should you assign to DepartmentA?
A. Contributor for fs1
B. Storage Blob Data Owner for fs1
C. Storage Blob Data Contributor for storage1
D. Storage Blob Data Contributor for fs1
DRAG DROP - You have an Azure Synapse Analytics workspace named Workspace1. You perform the following changes: • Implement source control for Workspace1. • Create a branch named Feature based on the collaboration branch. • Switch to the Feature branch. • Modify Workspace1. You need to publish the changes to Azure Synapse. From which branch should you perform each change? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point


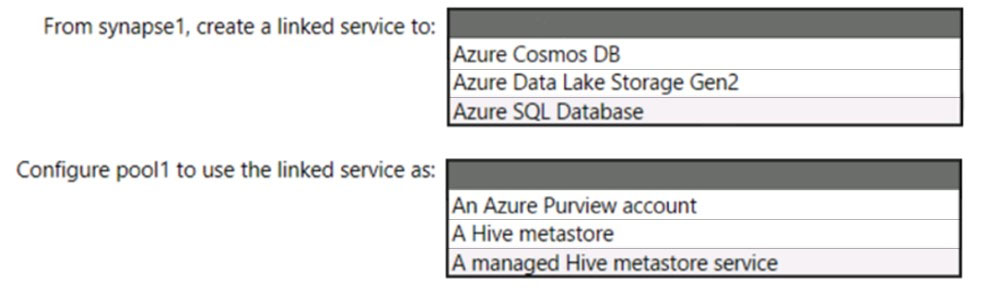
HOTSPOT - You have an Azure subscription that contains an Azure Databricks workspace named databricks1 and an Azure Synapse Analytics workspace named synapse1. The synapse1 workspace contains an Apache Spark pool named pool1. You need to share an Apache Hive catalog of pool1 with databricks1. What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You have an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 contains a partitioned fact table named dbo.Sales and a staging table named stg.Sales that has the matching table and partition definitions. You need to overwrite the content of the first partition in dbo.Sales with the content of the same partition in stg.Sales. The solution must minimize load times. What should you do?
A. Insert the data from stg.Sales into dbo.Sales.
B. Switch the first partition from dbo.Sales to stg.Sales.
C. Switch the first partition from stg.Sales to dbo.Sales.
D. Update dbo.Sales from stg.Sales.
You have a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant contains a group named Group1. You have an Azure subscription that contains the resources shown in the following table.You need to ensure that members of Group1 can read CSV files from storage1 by using the OPENROWSET function. The solution must meet the following requirements: • The members of Group1 must use credential1 to access storage1. • The principle of least privilege must be followed. Which permission should you grant to Group1?
A. EXECUTE
B. CONTROL
C. REFERENCES
D. SELECT
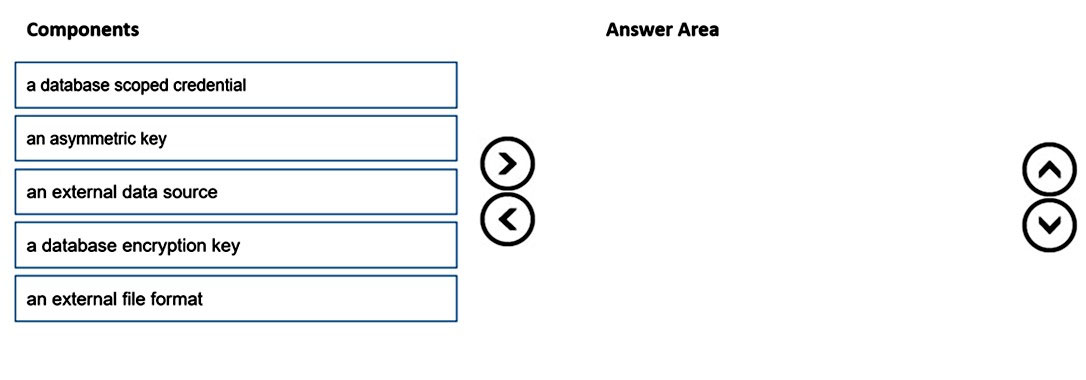
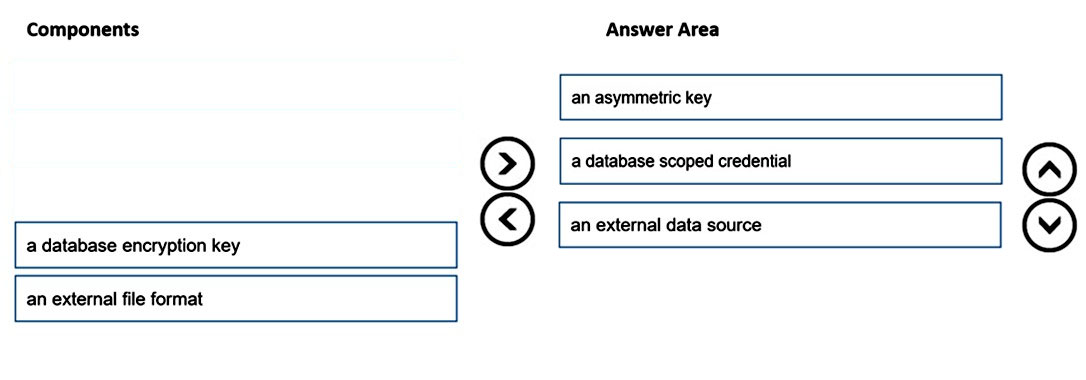
DRAG DROP - You are responsible for providing access to an Azure Data Lake Storage Gen2 account. Your user account has contributor access to the storage account, and you have the application ID and access key. You plan to use PolyBase to load data into an enterprise data warehouse in Azure Synapse Analytics. You need to configure PolyBase to connect the data warehouse to storage account. Which three components should you create in sequence? To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order. Select and Place:
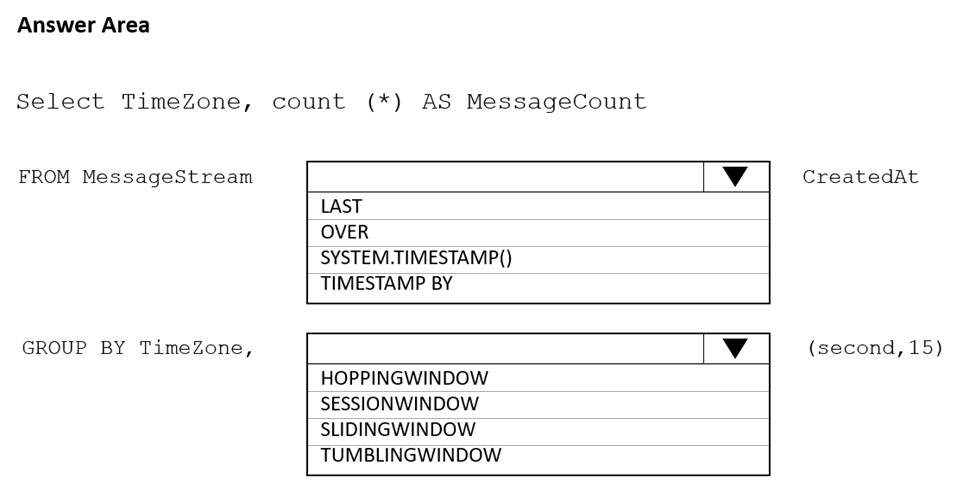
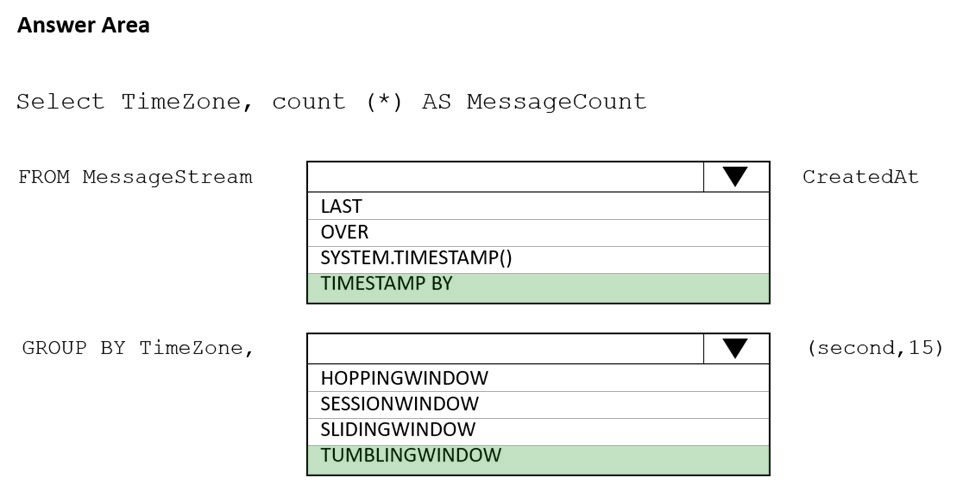
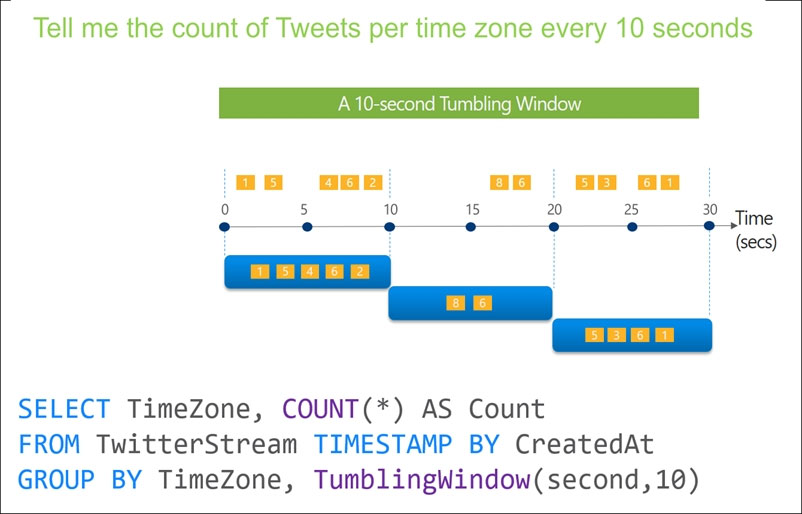
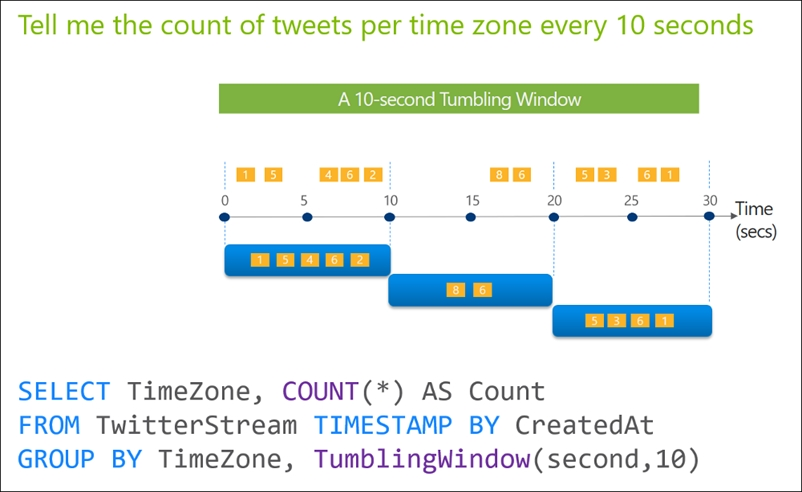
HOTSPOT - You are designing an Azure Stream Analytics solution that receives instant messaging data from an Azure Event Hub. You need to ensure that the output from the Stream Analytics job counts the number of messages per time zone every 15 seconds. How should you complete the Stream Analytics query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure data factory named ADF1. From Azure Data Factory Studio, you build a complex data pipeline in ADF1. You discover that the Save button is unavailable, and there are validation errors that prevent the pipeline from being published. You need to ensure that you can save the logic of the pipeline. Solution: You export ADF1 as an Azure Resource Manager (ARM) template. Does this meet the goal?
A. Yes
B. No
HOTSPOT -
You have an Azure Storage account that generates 200,000 new files daily. The file names have a format of {YYYY}/{MM}/{DD}/{HH}/{CustomerID}.csv.
You need to design an Azure Data Factory solution that will load new data from the storage account to an Azure Data Lake once hourly. The solution must minimize load times and costs.
How should you configure the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:


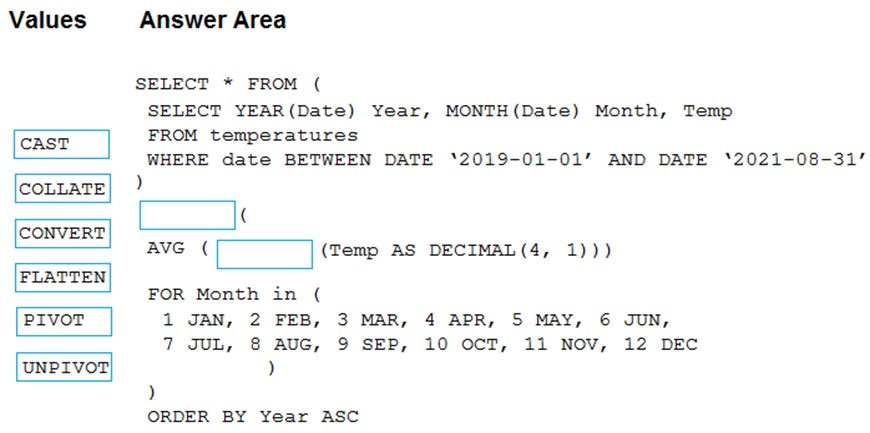
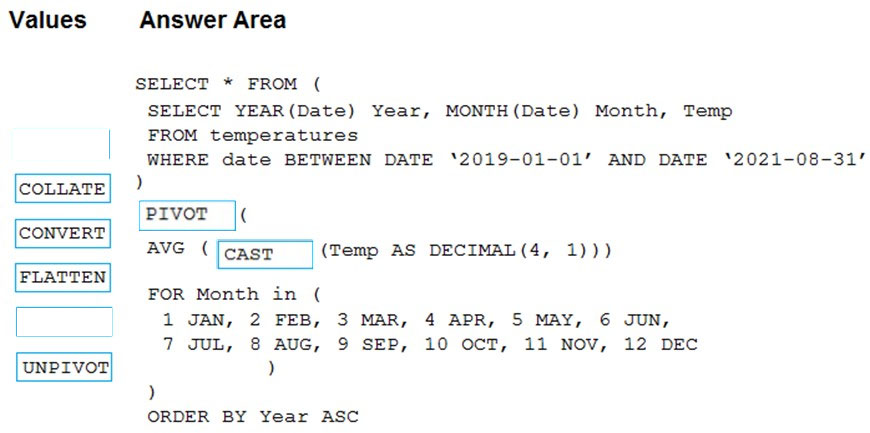
DRAG DROP - You have an Apache Spark DataFrame named temperatures. A sample of the data is shown in the following table.You need to produce the following table by using a Spark SQL query.
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
HOTSPOT - You have an Azure subscription that contains the resources shown in the following table.You need to ensure that you can run Spark notebooks in ws1.The solution must ensure that you can retrieve secrets from kv1 by using UAMI1. What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have a partitioned table in an Azure Synapse Analytics dedicated SQL pool. You need to design queries to maximize the benefits of partition elimination. What should you include in the Transact-SQL queries?
A. JOIN
B. WHERE
C. DISTINCT
D. GROUP BY
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table. Which output mode should you use?
A. update
B. complete
C. append
HOTSPOT - You plan to create a real-time monitoring app that alerts users when a device travels more than 200 meters away from a designated location. You need to design an Azure Stream Analytics job to process the data for the planned app. The solution must minimize the amount of code developed and the number of technologies used. What should you include in the Stream Analytics job? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


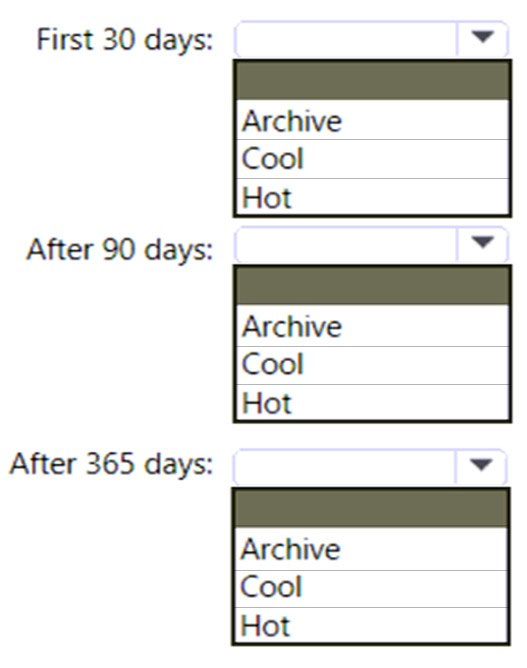
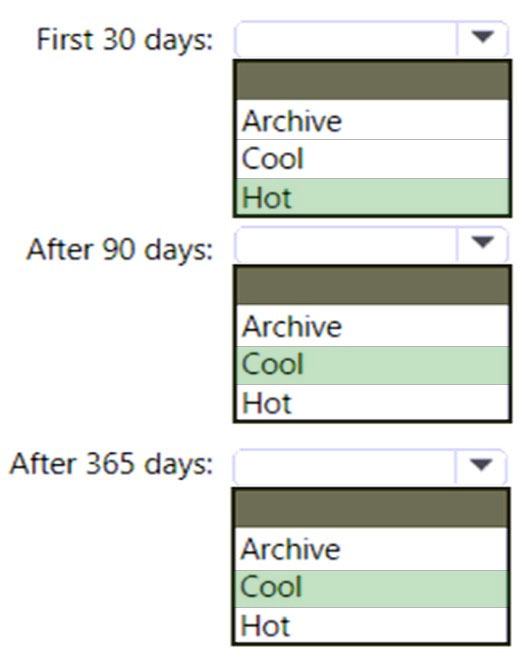
HOTSPOT - You are designing an application that will use an Azure Data Lake Storage Gen 2 account to store petabytes of license plate photos from toll booths. The account will use zone-redundant storage (ZRS). You identify the following usage patterns: * The data will be accessed several times a day during the first 30 days after the data is created. The data must meet an availability SLA of 99.9%. * After 90 days, the data will be accessed infrequently but must be available within 30 seconds. * After 365 days, the data will be accessed infrequently but must be available within five minutes. You need to recommend a data retention solution. The solution must minimize costs. Which access tier should you recommend for each time frame? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are designing a statistical analysis solution that will use custom proprietary Python functions on near real-time data from Azure Event Hubs. You need to recommend which Azure service to use to perform the statistical analysis. The solution must minimize latency. What should you recommend?
A. Azure Synapse Analytics
B. Azure Databricks
C. Azure Stream Analytics
D. Azure SQL Database
You are designing a streaming data solution that will ingest variable volumes of data. You need to ensure that you can change the partition count after creation. Which service should you use to ingest the data?
A. Azure Event Hubs Dedicated
B. Azure Stream Analytics
C. Azure Data Factory
D. Azure Synapse Analytics
Free Access Full DP-203 Practice Questions Free
Want more hands-on practice? Click here to access the full bank of DP-203 practice questions free and reinforce your understanding of all exam objectives.
We update our question sets regularly, so check back often for new and relevant content.
Good luck with your DP-203 certification journey!