

DP-203 Practice Exam Free – 50 Questions to Simulate the Real Exam
Are you getting ready for the DP-203 certification? Take your preparation to the next level with our DP-203 Practice Exam Free – a carefully designed set of 50 realistic exam-style questions to help you evaluate your knowledge and boost your confidence.
Using a DP-203 practice exam free is one of the best ways to:
- Experience the format and difficulty of the real exam
- Identify your strengths and focus on weak areas
- Improve your test-taking speed and accuracy
Below, you will find 50 realistic DP-203 practice exam free questions covering key exam topics. Each question reflects the structure and challenge of the actual exam.
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named SQLPool1. SQLPool1 is currently paused. You need to restore the current state of SQLPool1 to a new SQL pool. What should you do first?
A. Create a workspace.
B. Create a user-defined restore point.
C. Resume SQLPool1.
D. Create a new SQL pool.
You have an Azure subscription that contains an Azure SQL database named DB1 and a storage account named storage1. The storage1 account contains a file named File1.txt. File1.txt contains the names of selected tables in DB1. You need to use an Azure Synapse pipeline to copy data from the selected tables in DB1 to the files in storage1. The solution must meet the following requirements: • The Copy activity in the pipeline must be parameterized to use the data in File1.txt to identify the source and destination of the copy. • Copy activities must occur in parallel as often as possible. Which two pipeline activities should you include in the pipeline? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Get Metadata
B. Lookup
C. ForEach
D. If Condition
You need to implement a Type 3 slowly changing dimension (SCD) for product category data in an Azure Synapse Analytics dedicated SQL pool. You have a table that was created by using the following Transact-SQL statement.Which two columns should you add to the table? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. [EffectiveStartDate] [datetime] NOT NULL,
B. [CurrentProductCategory] [nvarchar] (100) NOT NULL,
C. [EffectiveEndDate] [datetime] NULL,
D. [ProductCategory] [nvarchar] (100) NOT NULL,
E. [OriginalProductCategory] [nvarchar] (100) NOT NULL,

You configure monitoring for an Azure Synapse Analytics implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Storage Gen2 using an external table. Files with an invalid schema cause errors to occur. You need to monitor for an invalid schema error. For which error should you monitor?
A. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [com.microsoft.polybase.client.KerberosSecureLogin] occurred while accessing external file.’
B. Cannot execute the query “Remote Query” against OLE DB provider “SQLNCLI11” for linked server “(null)”. Query aborted- the maximum reject threshold (0 rows) was reached while reading from an external source: 1 rows rejected out of total 1 rows processed.
C. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [Unable to instantiate LoginClass] occurred while accessing external file.’
D. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [No FileSystem for scheme: wasbs] occurred while accessing external file.’
DRAG DROP - You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName. You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values. You create the following components: ✑ A destination table in Azure Synapse ✑ An Azure Blob storage container ✑ A service principal Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:


HOTSPOT - You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a webpage. The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has a type of either 'start' or 'end'. You need to calculate the duration between start and end events. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


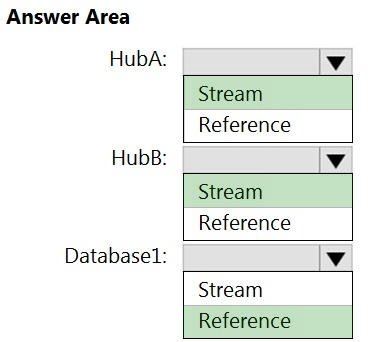
HOTSPOT - You have an Azure SQL database named Database1 and two Azure event hubs named HubA and HubB. The data consumed from each source is shown in the following table.You need to implement Azure Stream Analytics to calculate the average fare per mile by driver. How should you configure the Stream Analytics input for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

HOTSPOT - You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool. You plan to deploy a solution that will analyze sales data and include the following: • A table named Country that will contain 195 rows • A table named Sales that will contain 100 million rows • A query to identify total sales by country and customer from the past 30 days You need to create the tables. The solution must maximize query performance. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


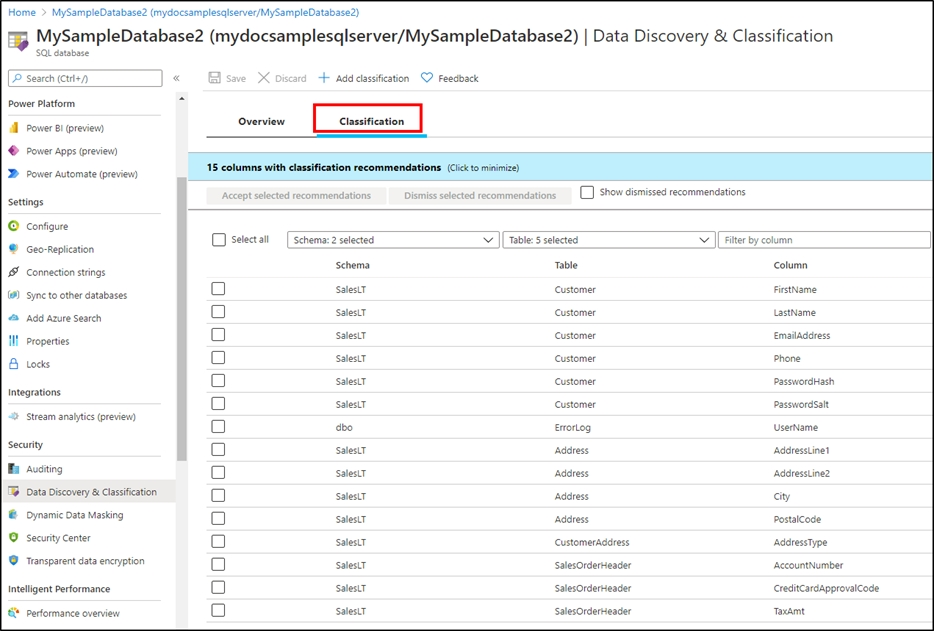
You plan to create an Azure Synapse Analytics dedicated SQL pool. You need to minimize the time it takes to identify queries that return confidential information as defined by the company's data privacy regulations and the users who executed the queues. Which two components should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. sensitivity-classification labels applied to columns that contain confidential information
B. resource tags for databases that contain confidential information
C. audit logs sent to a Log Analytics workspace
D. dynamic data masking for columns that contain confidential information

You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.You create an external table named ExtTable that has LOCATION='/topfolder/'. When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
A. File2.csv and File3.csv only
B. File1.csv and File4.csv only
C. File1.csv, File2.csv, File3.csv, and File4.csv
D. File1.csv only
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.FactPurchase will have 1 million rows of data added daily and will contain three years of data. Transact-SQL queries similar to the following query will be executed daily. SELECT - SupplierKey, StockItemKey, IsOrderFinalized, COUNT(*) FROM FactPurchase - WHERE DateKey >= 20210101 - AND DateKey <= 20210131 - GROUP By SupplierKey, StockItemKey, IsOrderFinalized Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on IsOrderFinalized
You have several Azure Data Factory pipelines that contain a mix of the following types of activities: ✑ Wrangling data flow ✑ Notebook ✑ Copy ✑ Jar Which two Azure services should you use to debug the activities? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point
A. Azure Synapse Analytics
B. Azure HDInsight
C. Azure Machine Learning
D. Azure Data Factory
E. Azure Databricks
HOTSPOT - You have two Azure SQL databases named DB1 and DB2. DB1 contains a table named Table1. Table1 contains a timestamp column named LastModifiedOn. LastModifiedOn contains the timestamp of the most recent update for each individual row. DB2 contains a table named Watermark. Watermark contains a single timestamp column named WatermarkValue. You plan to create an Azure Data Factory pipeline that will incrementally upload into Azure Blob Storage all the rows in Table1 for which the LastModifiedOn column contains a timestamp newer than the most recent value of the WatermarkValue column in Watermark. You need to identify which activities to include in the pipeline. The solution must meet the following requirements: • Minimize the effort to author the pipeline. • Ensure that the number of data integration units allocated to the upload operation can be controlled. What should you identify? To answer, select the appropriate options in the answer area. NOTE: Each correct answer is worth one point.


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1. You plan to insert data from the files in container1 into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1. You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1. Solution: You use an Azure Synapse Analytics serverless SQL pool to create an external table that has an additional DateTime column. Does this meet the goal?
A. Yes
B. No
You have an Azure subscription that contains an Azure Blob Storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool named Pool1. You need to store data in storage1. The data will be read by Pool1. The solution must meet the following requirements: Enable Pool1 to skip columns and rows that are unnecessary in a query.✑ Automatically create column statistics. ✑ Minimize the size of files. Which type of file should you use?
A. JSON
B. Parquet
C. Avro
D. CSV
You have several Azure Data Factory pipelines that contain a mix of the following types of activities: • Power Query • Notebook • Copy • Jar Which two Azure services should you use to debug the activities? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Azure Machine Learning
B. Azure Data Factory
C. Azure Synapse Analytics
D. Azure HDInsight
E. Azure Databricks
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact table named Table1. You need to identify the extent of the data skew in Table1. What should you do in Synapse Studio?
A. Connect to the built-in pool and query sys.dm_pdw_nodes_db_partition_stats.
B. Connect to the built-in pool and run DBCC CHECKALLOC.
C. Connect to Pool1 and query sys.dm_pdw_node_status.
D. Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
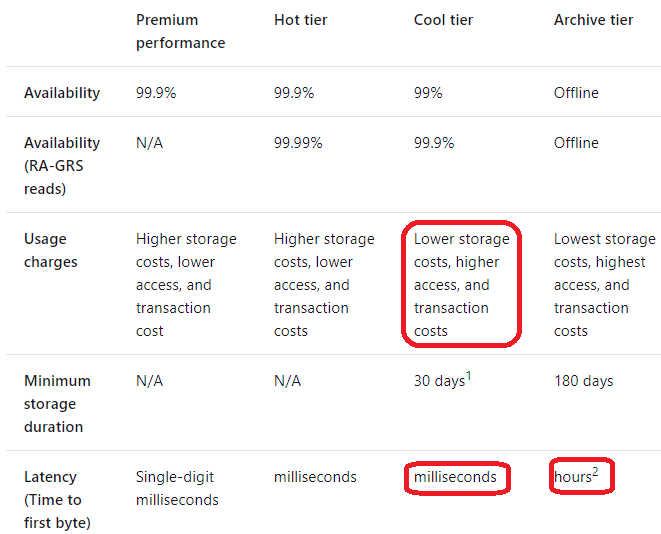
HOTSPOT - You have an Azure Data Lake Storage Gen2 container. Data is ingested into the container, and then transformed by a data integration application. The data is NOT modified after that. Users can read files in the container but cannot modify the files. You need to design a data archiving solution that meets the following requirements: ✑ New data is accessed frequently and must be available as quickly as possible. ✑ Data that is older than five years is accessed infrequently but must be available within one second when requested. ✑ Data that is older than seven years is NOT accessed. After seven years, the data must be persisted at the lowest cost possible. ✑ Costs must be minimized while maintaining the required availability. How should you manage the data? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point Hot Area:


DRAG DROP - You have an Azure subscription. You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model. Pool1 will contain the following tables.You need to design the table storage for pool1. The solution must meet the following requirements: ✑ Maximize the performance of data loading operations to Staging.WebSessions. ✑ Minimize query times for reporting queries against the dimensional model. Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are designing an Azure Stream Analytics solution that will analyze Twitter data. You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once. Solution: You use a hopping window that uses a hop size of 5 seconds and a window size 10 seconds. Does this meet the goal?
A. Yes
B. No
You have an enterprise data warehouse in Azure Synapse Analytics. Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse. The external table has three columns. You discover that the Parquet files have a fourth column named ItemID. Which command should you run to add the ItemID column to the external table? A.B.
C.
D.
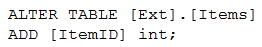
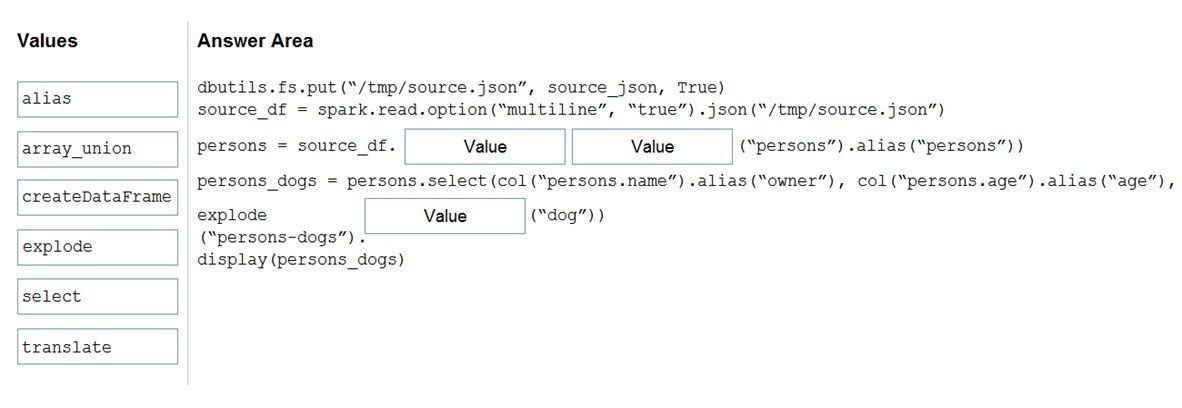
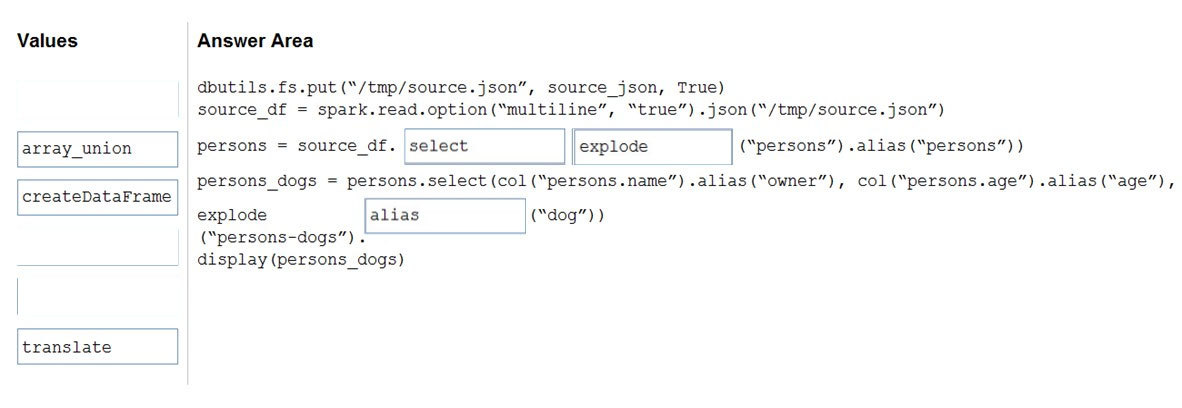
DRAG DROP - You use PySpark in Azure Databricks to parse the following JSON input.You need to output the data in the following tabular format.
How should you complete the PySpark code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the spit bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
You have an Azure data factory named DF1. DF1 contains a pipeline that has five activities. You need to monitor queue times across the activities by using Log Analytics. What should you do in DF1?
A. Connect DF1 to a Microsoft Purview account.
B. Add a diagnostic setting that sends activity runs to a Log Analytics workspace.
C. Enable auto refresh for the Activity Logs Insights workbook.
D. Add a diagnostic setting that sends pipeline runs to a Log Analytics workspace.
You have an Azure Synapse Analytics dedicated SQL pool named pool1. You need to perform a monthly audit of SQL statements that affect sensitive data. The solution must minimize administrative effort. What should you include in the solution?
A. workload management
B. sensitivity labels
C. dynamic data masking
D. Microsoft Defender for SQL
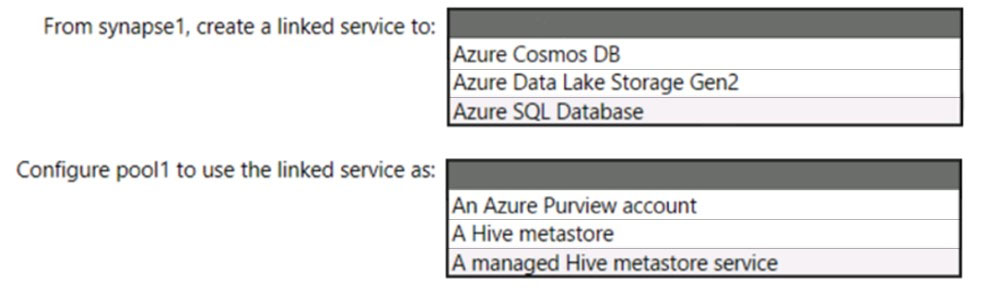
HOTSPOT - You have an Azure subscription that contains an Azure Databricks workspace named databricks1 and an Azure Synapse Analytics workspace named synapse1. The synapse1 workspace contains an Apache Spark pool named pool1. You need to share an Apache Hive catalog of pool1 with databricks1. What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.You need to alter the table to meet the following requirements: ✑ Ensure that users can identify the current manager of employees. ✑ Support creating an employee reporting hierarchy for your entire company. ✑ Provide fast lookup of the managers' attributes such as name and job title. Which column should you add to the table?
A. [ManagerEmployeeID] [smallint] NULL
B. [ManagerEmployeeKey] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
You have an Azure Databricks resource. You need to log actions that relate to changes in compute for the Databricks resource. Which Databricks services should you log?
A. clusters
B. workspace
C. DBFS
D. SSH
E. jobs
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 receives new data once every 24 hours. You have the following function.You have the following query.
The query is executed once every 15 minutes and the @parameter value is set to the current date. You need to minimize the time it takes for the query to return results. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create an index on the avg_f column.
B. Convert the avg_c column into a calculated column.
C. Create an index on the sensorid column.
D. Enable result set caching.
E. Change the table distribution to replicate.
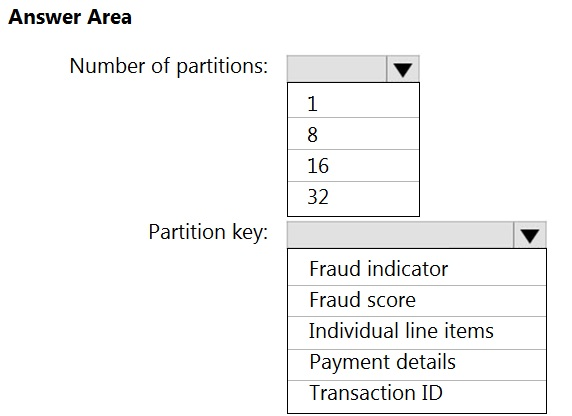
HOTSPOT - You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as the partition key. You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the payment details, a fraud score, and a fraud indicator. You plan to send the output to an Azure event hub named fraudhub. You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as possible. How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You have a Log Analytics workspace named la1 and an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 sends logs to la1. You need to identify whether a recently executed query on Pool1 used the result set cache. What are two ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Review the sys.dm_pdw_sql_requests dynamic management view in Pool1.
B. Review the sys.dm_pdw_exec_requests dynamic management view in Pool1.
C. Use the Monitor hub in Synapse Studio.
D. Review the AzureDiagnostics table in la1.
E. Review the sys.dm_pdw_request_steps dynamic management view in Pool1.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Data Lake Storage account that contains a staging zone. You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics. Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse. Does this meet the goal?
A. Yes
B. No
You are planning a solution to aggregate streaming data that originates in Apache Kafka and is output to Azure Data Lake Storage Gen2. The developers who will implement the stream processing solution use Java. Which service should you recommend using to process the streaming data?
A. Azure Event Hubs
B. Azure Data Factory
C. Azure Stream Analytics
D. Azure Databricks

DRAG DROP - You have a data warehouse. You need to implement a slowly changing dimension (SCD) named Product that will include three columns named ProductName, ProductColor, and ProductSize. The solution must meet the following requirements: • Prevent changes to the values stored in ProductName. • Retain only the current and the last values in ProductSize. • Retain all the current and previous values in ProductColor. Which type of SCD should you implement for each column? To answer, drag the appropriate types to the correct columns. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


You have an Azure Synapse Analytics dedicated SQL pool named SA1 that contains a table named Table1. You need to identify tables that have a high percentage of deleted rows. What should you run?
A. sys.pdw_nodes_column_store_segments
B. sys.dm_db_column_store_row_group_operational_stats
C. sys.pdw_nodes_column_store_row_groups
D. sys.dm_db_column_store_row_group_physical_stats
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1. Several users execute ad hoc queries to DW1 concurrently. You regularly perform automated data loads to DW1. You need to ensure that the automated data loads have enough memory available to complete quickly and successfully when the adhoc queries run. What should you do?
A. Hash distribute the large fact tables in DW1 before performing the automated data loads.
B. Assign a smaller resource class to the automated data load queries.
C. Assign a larger resource class to the automated data load queries.
D. Create sampled statistics for every column in each table of DW1.
HOTSPOT -
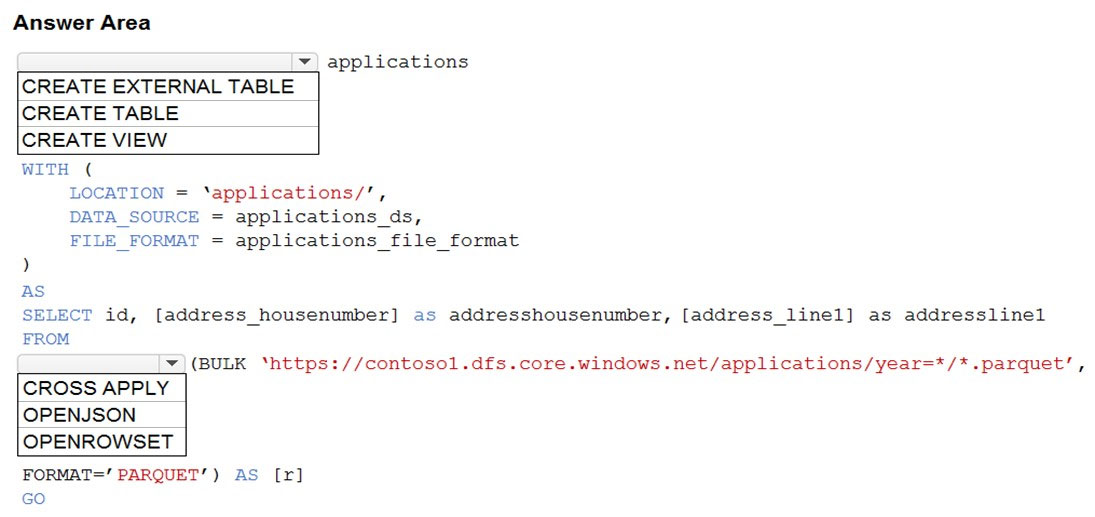
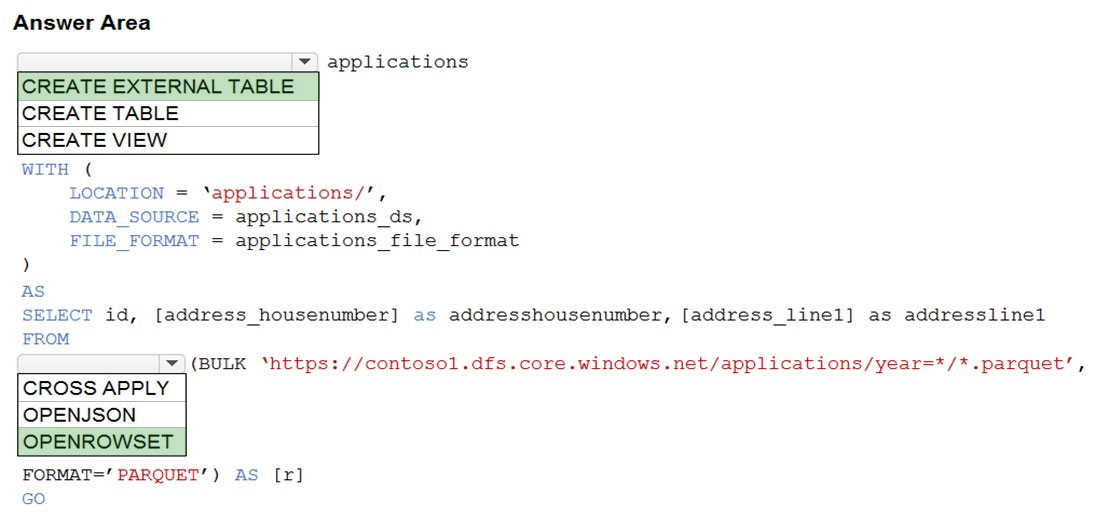
You are building a database in an Azure Synapse Analytics serverless SQL pool.
You have data stored in Parquet files in an Azure Data Lake Storege Gen2 container.
Records are structured as shown in the following sample.
{
"id": 123,
"address_housenumber": "19c",
"address_line": "Memory Lane",
"applicant1_name": "Jane",
"applicant2_name": "Dev"
}
The records contain two applicants at most.
You need to build a table that includes only the address fields.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You are designing a solution that will use tables in Delta Lake on Azure Databricks. You need to minimize how long it takes to perform the following: • Queries against non-partitioned tables • Joins on non-partitioned columns Which two options should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. the clone command
B. Z-Ordering
C. Apache Spark caching
D. dynamic file pruning (DFP)
HOTSPOT - You have an Azure Synapse Analytics serverless SQL pool that contains a database named db1. The data model for db1 is shown in the following exhibit.Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the exhibit. NOTE: Each correct selection is worth one point.


HOTSPOT - You have a self-hosted integration runtime in Azure Data Factory. The current status of the integration runtime has the following configurations: ✑ Status: Running ✑ Type: Self-Hosted ✑ Version: 4.4.7292.1 ✑ Running / Registered Node(s): 1/1 ✑ High Availability Enabled: False ✑ Linked Count: 0 ✑ Queue Length: 0 ✑ Average Queue Duration. 0.00s The integration runtime has the following node details: ✑ Name: X-M ✑ Status: Running ✑ Version: 4.4.7292.1 ✑ Available Memory: 7697MB ✑ CPU Utilization: 6% ✑ Network (In/Out): 1.21KBps/0.83KBps ✑ Concurrent Jobs (Running/Limit): 2/14 ✑ Role: Dispatcher/Worker ✑ Credential Status: In Sync Use the drop-down menus to select the answer choice that completes each statement based on the information presented. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You need to design a data ingestion and storage solution for the Twitter feeds. The solution must meet the customer sentiment analytics requirements. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have the following Azure Data Factory pipelines: ✑ Ingest Data from System1 ✑ Ingest Data from System2 ✑ Populate Dimensions ✑ Populate Facts Ingest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest Data from System2. Populate Facts must execute after Populate Dimensions pipeline. All the pipelines must execute every eight hours. What should you do to schedule the pipelines for execution?
A. Add an event trigger to all four pipelines.
B. Add a schedule trigger to all four pipelines.
C. Create a patient pipeline that contains the four pipelines and use a schedule trigger.
D. Create a patient pipeline that contains the four pipelines and use an event trigger.
HOTSPOT - You have an Azure Synapse serverless SQL pool. You need to read JSON documents from a file by using the OPENROWSET function. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact table named Table1. You need to identify the extent of the data skew in Table1. What should you do in Synapse Studio?
A. Connect to the built-in pool and run sys.dm_pdw_nodes_db_partition_stats.
B. Connect to Pool1 and run DBCC CHECKALLOC.
C. Connect to the built-in pool and run DBCC CHECKALLOC.
D. Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
DRAG DROP - You have an Azure Synapse Analytics serverless SQL pool. You have an Azure Data Lake Storage account named adls1 that contains a public container named container1. The container1 container contains a folder named folder1. You need to query the top 100 rows of all the CSV files in folder1. How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point


HOTSPOT - You need to design the partitions for the product sales transactions. The solution must meet the sales transaction dataset requirements. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You are designing an enterprise data warehouse in Azure Synapse Analytics that will contain a table named Customers. Customers will contain credit card information. You need to recommend a solution to provide salespeople with the ability to view all the entries in Customers. The solution must prevent all the salespeople from viewing or inferring the credit card information. What should you include in the recommendation?
A. data masking
B. Always Encrypted
C. column-level security
D. row-level security
HOTSPOT - You are designing a monitoring solution for a fleet of 500 vehicles. Each vehicle has a GPS tracking device that sends data to an Azure event hub once per minute. You have a CSV file in an Azure Data Lake Storage Gen2 container. The file maintains the expected geographical area in which each vehicle should be. You need to ensure that when a GPS position is outside the expected area, a message is added to another event hub for processing within 30 seconds. The solution must minimize cost. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

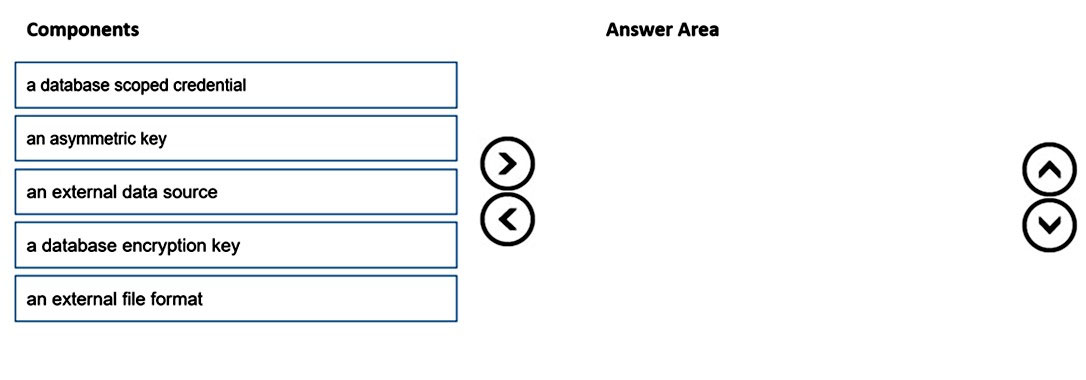
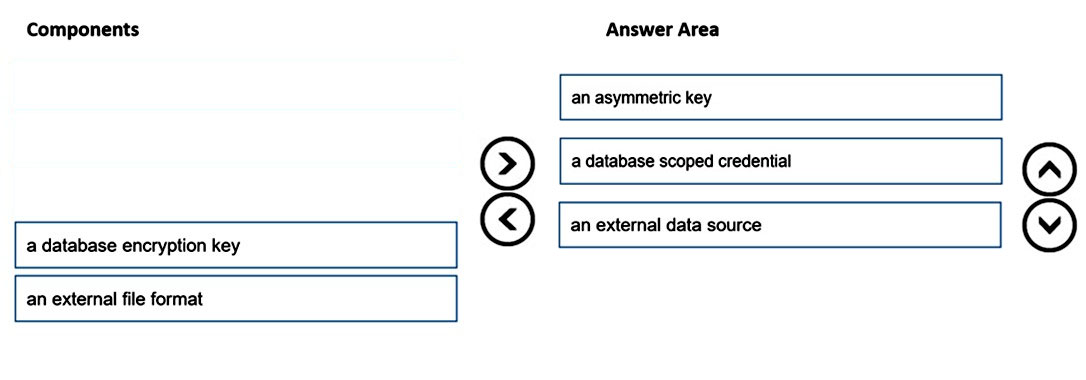
DRAG DROP - You are responsible for providing access to an Azure Data Lake Storage Gen2 account. Your user account has contributor access to the storage account, and you have the application ID and access key. You plan to use PolyBase to load data into an enterprise data warehouse in Azure Synapse Analytics. You need to configure PolyBase to connect the data warehouse to storage account. Which three components should you create in sequence? To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order. Select and Place:
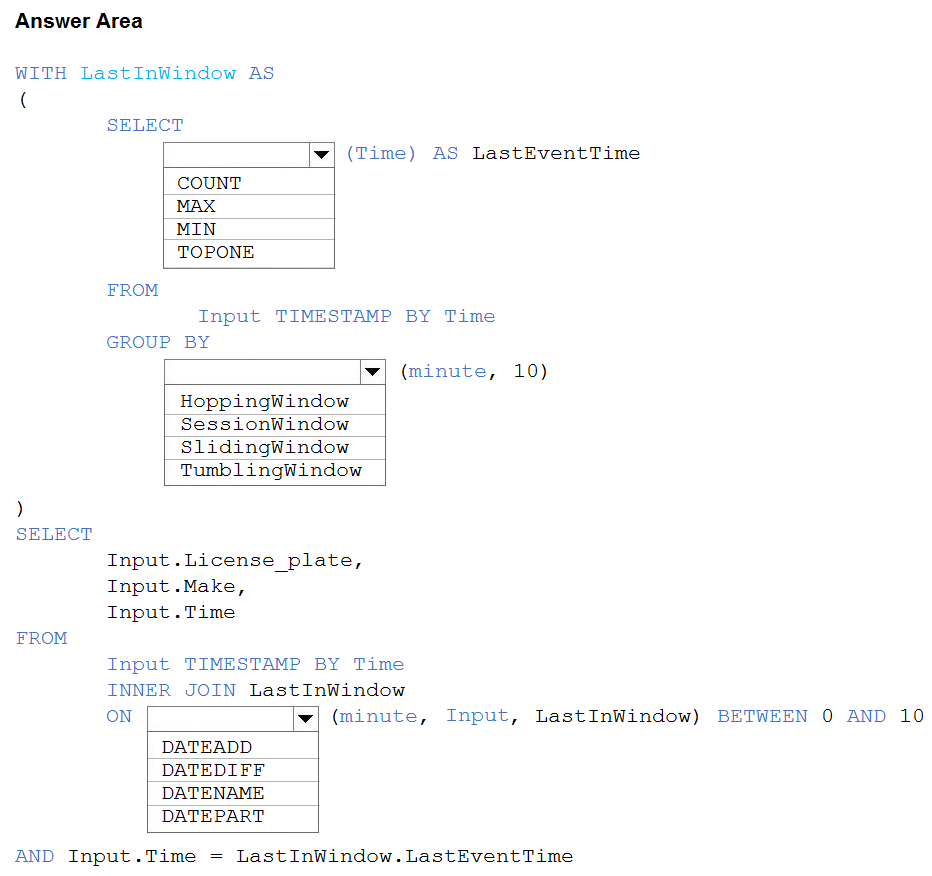
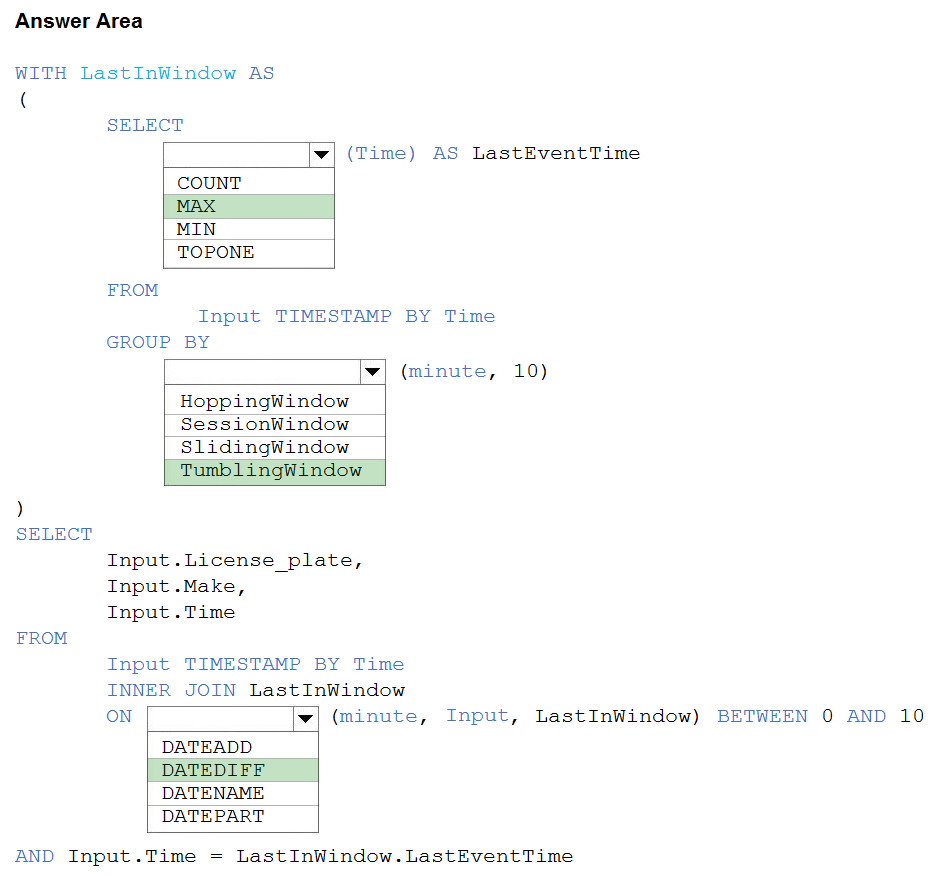
HOTSPOT - You are processing streaming data from vehicles that pass through a toll booth. You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have an Azure subscription that contains an Azure Synapse Analytics workspace name workspace1, workspace1 contains an Azure Synapse Analytics dedicated SQL pool named Pool1. You create a mapping data flow in an Azure Synapse pipeline that writes data to Pool1. You execute the data flow and capture the execution information. You need to identify how long it takes to write the data to Pool1. Which metric should you use?
A. the rows written
B. the sink processing time
C. the transformation processing time
D. the post processing time
Free Access Full DP-203 Practice Exam Free
Looking for additional practice? Click here to access a full set of DP-203 practice exam free questions and continue building your skills across all exam domains.
Our question sets are updated regularly to ensure they stay aligned with the latest exam objectives—so be sure to visit often!
Good luck with your DP-203 certification journey!