

DP-203 Mock Test Free – 50 Realistic Questions to Prepare with Confidence.
Getting ready for your DP-203 certification exam? Start your preparation the smart way with our DP-203 Mock Test Free – a carefully crafted set of 50 realistic, exam-style questions to help you practice effectively and boost your confidence.
Using a mock test free for DP-203 exam is one of the best ways to:
- Familiarize yourself with the actual exam format and question style
- Identify areas where you need more review
- Strengthen your time management and test-taking strategy
Below, you will find 50 free questions from our DP-203 Mock Test Free resource. These questions are structured to reflect the real exam’s difficulty and content areas, helping you assess your readiness accurately.
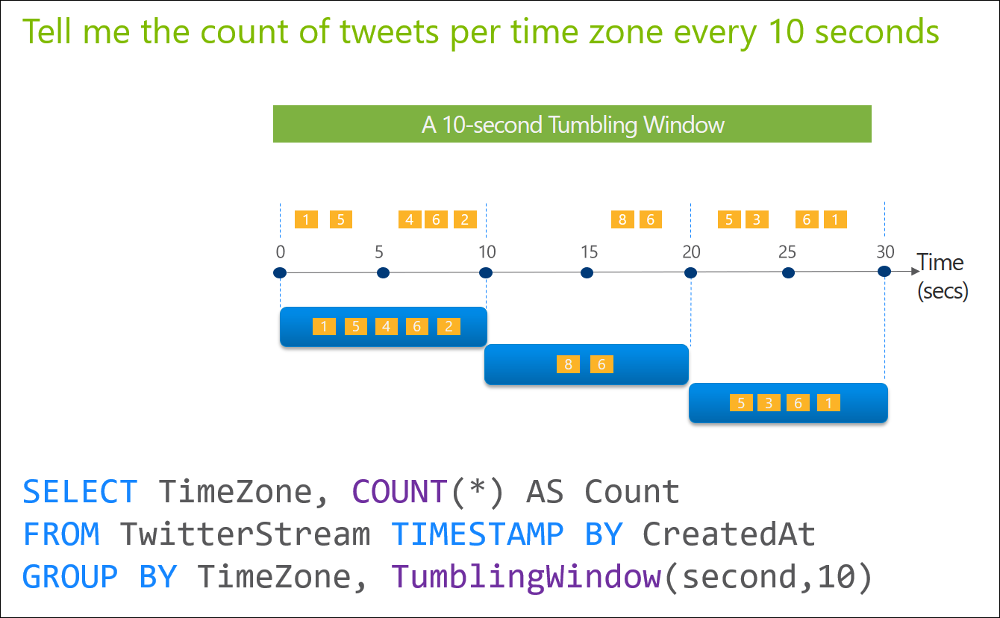
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are designing an Azure Stream Analytics solution that will analyze Twitter data. You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once. Solution: You use a hopping window that uses a hop size of 10 seconds and a window size of 10 seconds. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL. ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL. ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R. The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
You have a data warehouse in Azure Synapse Analytics. You need to ensure that the data in the data warehouse is encrypted at rest. What should you enable?
A. Advanced Data Security for this database
B. Transparent Data Encryption (TDE)
C. Secure transfer required
D. Dynamic Data Masking
HOTSPOT - You need to design a data ingestion and storage solution for the Twitter feeds. The solution must meet the customer sentiment analytics requirements. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


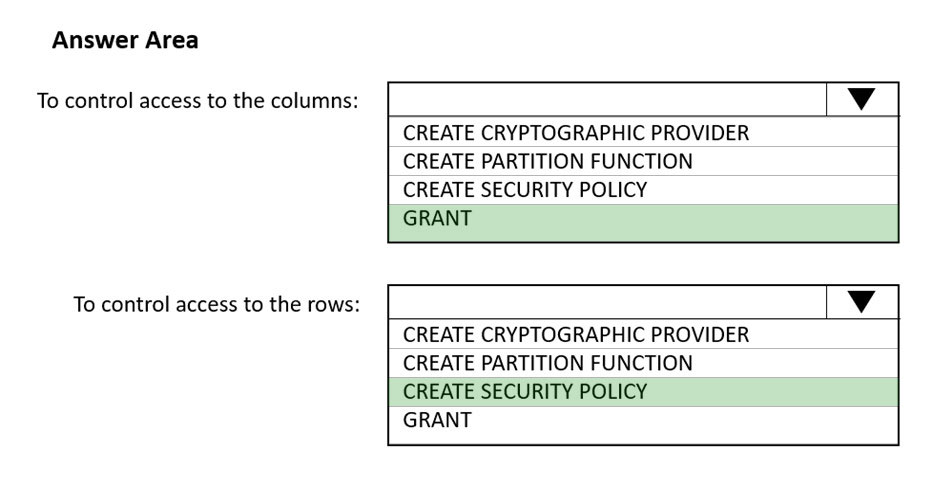
HOTSPOT - You have an Azure Synapse Analytics SQL pool named Pool1. In Azure Active Directory (Azure AD), you have a security group named Group1. You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

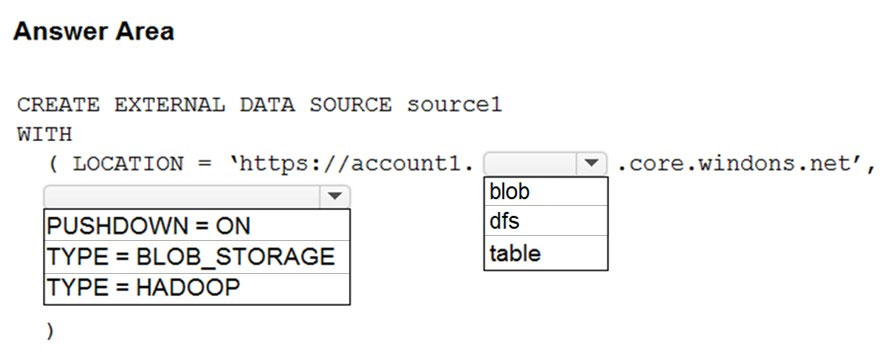
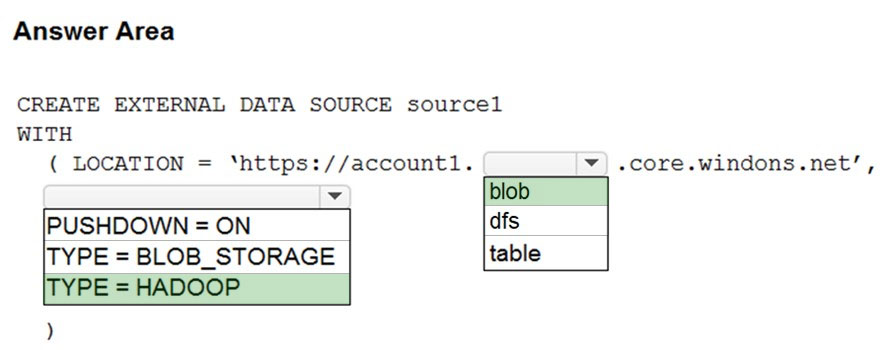
HOTSPOT - You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named Account1. You plan to access the files in Account1 by using an external table. You need to create a data source in Pool1 that you can reference when you create the external table. How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are designing a solution that will use tables in Delta Lake on Azure Databricks. You need to minimize how long it takes to perform the following: • Queries against non-partitioned tables • Joins on non-partitioned columns Which two options should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. the clone command
B. Z-Ordering
C. Apache Spark caching
D. dynamic file pruning (DFP)
You are planning a solution to aggregate streaming data that originates in Apache Kafka and is output to Azure Data Lake Storage Gen2. The developers who will implement the stream processing solution use Java. Which service should you recommend using to process the streaming data?
A. Azure Event Hubs
B. Azure Data Factory
C. Azure Stream Analytics
D. Azure Databricks

You have a partitioned table in an Azure Synapse Analytics dedicated SQL pool. You need to design queries to maximize the benefits of partition elimination. What should you include in the Transact-SQL queries?
A. JOIN
B. WHERE
C. DISTINCT
D. GROUP BY
You are designing a slowly changing dimension (SCD) for supplier data in an Azure Synapse Analytics dedicated SQL pool. You plan to keep a record of changes to the available fields. The supplier data contains the following columns.Which three additional columns should you add to the data to create a Type 2 SCD? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. surrogate primary key
B. effective start date
C. business key
D. last modified date
E. effective end date
F. foreign key
You have an Azure Stream Analytics job named Job1. The metrics of Job1 from the last hour are shown in the following table.The late arrival tolerance for Job1 is set to five seconds. You need to optimize Job1. Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. Increase the number of SUs.
B. Parallelize the query.
C. Resolve errors in output processing.
D. Resolve errors in input processing.
You are designing an Azure Synapse Analytics workspace. You need to recommend a solution to provide double encryption of all the data at rest. Which two components should you include in the recommendation? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. an X.509 certificate
B. an RSA key
C. an Azure virtual network that has a network security group (NSG)
D. an Azure Policy initiative
E. an Azure key vault that has purge protection enabled
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in an Azure Data Lake Storage Gen2 container. Which type of trigger should you use?
A. on-demand
B. tumbling window
C. schedule
D. storage event
You have an Azure Synapse Analytics dedicated SQL pool. You need to ensure that data in the pool is encrypted at rest. The solution must NOT require modifying applications that query the data. What should you do?
A. Enable encryption at rest for the Azure Data Lake Storage Gen2 account.
B. Enable Transparent Data Encryption (TDE) for the pool.
C. Use a customer-managed key to enable double encryption for the Azure Synapse workspace.
D. Create an Azure key vault in the Azure subscription grant access to the pool.
DRAG DROP - You have an Azure subscription that contains an Azure Data Lake Storage Gen2 account named account1 and a user named User1. In account1, you create a container named container1. In container1, you create a folder named folder1. You need to ensure that User1 can list and read all the files in folder1. The solution must use the principle of least privilege. How should you configure the permissions for each folder? To answer, drag the appropriate permissions to the correct folders. Each permission may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


You manage an enterprise data warehouse in Azure Synapse Analytics. Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries. You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
A. DWU percentage
B. Cache hit percentage
C. DWU limit
D. Data IO percentage
A company uses Azure Stream Analytics to monitor devices. The company plans to double the number of devices that are monitored. You need to monitor a Stream Analytics job to ensure that there are enough processing resources to handle the additional load. Which metric should you monitor?
A. Early Input Events
B. Late Input Events
C. Watermark delay
D. Input Deserialization Errors
DRAG DROP - You are batch loading a table in an Azure Synapse Analytics dedicated SQL pool. You need to load data from a staging table to the target table. The solution must ensure that if an error occurs while loading the data to the target table, all the inserts in that batch are undone. How should you complete the Transact-SQL code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


You are implementing a batch dataset in the Parquet format. Data files will be produced be using Azure Data Factory and stored in Azure Data Lake Storage Gen2. The files will be consumed by an Azure Synapse Analytics serverless SQL pool. You need to minimize storage costs for the solution. What should you do?
A. Use Snappy compression for the files.
B. Use OPENROWSET to query the Parquet files.
C. Create an external table that contains a subset of columns from the Parquet files.
D. Store all data as string in the Parquet files.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure data factory named ADF1. From Azure Data Factory Studio, you build a complex data pipeline in ADF1. You discover that the Save button is unavailable, and there are validation errors that prevent the pipeline from being published. You need to ensure that you can save the logic of the pipeline. Solution: You export ADF1 as an Azure Resource Manager (ARM) template. Does this meet the goal?
A. Yes
B. No
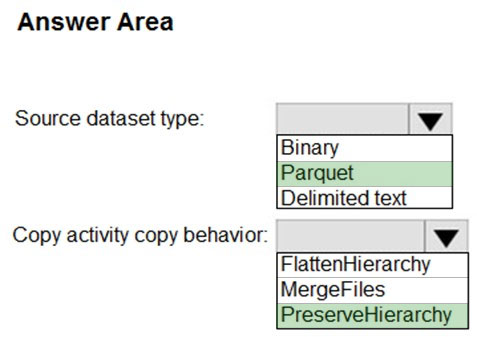
HOTSPOT - You have two Azure Storage accounts named Storage1 and Storage2. Each account holds one container and has the hierarchical namespace enabled. The system has files that contain data stored in the Apache Parquet format. You need to copy folders and files from Storage1 to Storage2 by using a Data Factory copy activity. The solution must meet the following requirements: ✑ No transformations must be performed. ✑ The original folder structure must be retained. ✑ Minimize time required to perform the copy activity. How should you configure the copy activity? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

HOTSPOT - You have an Azure Databricks workspace. You read data from a CSV file by using a notebook, and then load the data to a DataFrame. You need to add rows from the DataFrame to an existing Delta table by using Python code. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


What should you do to improve high availability of the real-time data processing solution?
A. Deploy a High Concurrency Databricks cluster.
B. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
C. Set Data Lake Storage to use geo-redundant storage (GRS).
D. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
You have an Azure Synapse Analytics serverless SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named storage1. The AllowBlobPublicAccess property is disabled for storage1. You need to create an external data source that can be used by Azure Active Directory (Azure AD) users to access storage from Pool1. What should you create first?
A. an external resource pool
B. an external library
C. database scoped credentials
D. a remote service binding
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns and 5 billion rows and is a heap. Most queries against the table aggregate values from approximately 100 million rows and return only two columns. You discover that the queries against the fact table are very slow. Which type of index should you add to provide the fastest query times?
A. nonclustered columnstore
B. clustered columnstore
C. nonclustered
D. clustered
DRAG DROP - You have an Azure subscription. You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model. Pool1 will contain the following tables.You need to design the table storage for pool1. The solution must meet the following requirements: ✑ Maximize the performance of data loading operations to Staging.WebSessions. ✑ Minimize query times for reporting queries against the dimensional model. Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


HOTSPOT - You need to design an analytical storage solution for the transactional data. The solution must meet the sales transaction dataset requirements. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


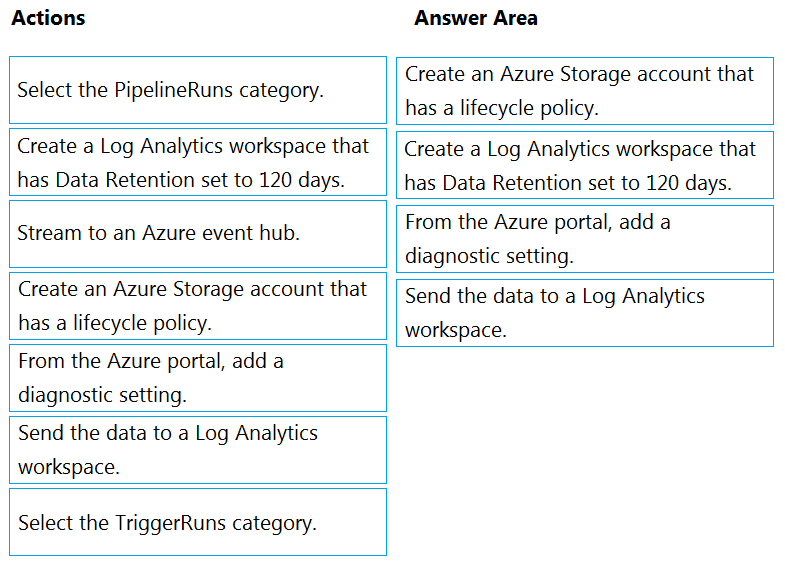
DRAG DROP - You have an Azure data factory. You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:

A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices. The company must be able to monitor the devices in real-time. You need to design the solution. What should you recommend?
A. Azure Analysis Services using Azure Portal
B. Azure Stream Analytics Edge application using Microsoft Visual Studio
C. Azure Analysis Services using Azure PowerShell
D. Azure Analysis Services using Microsoft Visual Studio
HOTSPOT - You use Azure Data Factory to prepare data to be queried by Azure Synapse Analytics serverless SQL pools. Files are initially ingested into an Azure Data Lake Storage Gen2 account as 10 small JSON files. Each file contains the same data attributes and data from a subsidiary of your company. You need to move the files to a different folder and transform the data to meet the following requirements: ✑ Provide the fastest possible query times. ✑ Automatically infer the schema from the underlying files. How should you configure the Data Factory copy activity? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


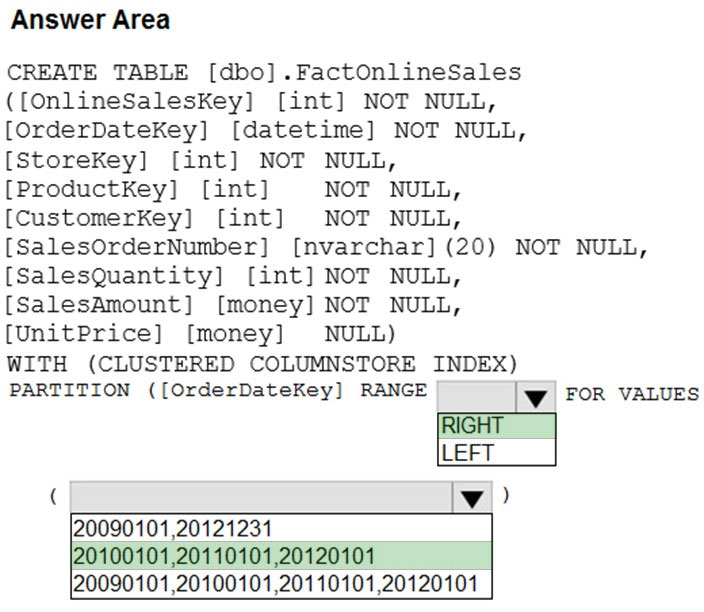
DRAG DROP - You need to create a partitioned table in an Azure Synapse Analytics dedicated SQL pool. How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are designing an Azure Stream Analytics solution that will analyze Twitter data. You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once. Solution: You use a tumbling window, and you set the window size to 10 seconds. Does this meet the goal?
A. Yes
B. No
You have an Azure subscription that is linked to a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant that contains a security group named Group1. The subscription contains an Azure Data Lake Storage account named myaccount1. The myaccount1 account contains two containers named container1 and container2. You need to grant Group1 read access to container1. The solution must use the principle of least privilege. Which role should you assign to Group1?
A. Storage Table Data Reader for myaccount1
B. Storage Blob Data Reader for container1
C. Storage Blob Data Reader for myaccount1
D. Storage Table Data Reader for container1
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1. You plan to insert data from the files in container1 into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1. You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1. Solution: In an Azure Synapse Analytics pipeline, you use a data flow that contains a Derived Column transformation. Does this meet the goal?
A. Yes
B. No
You have an Azure Synapse Analytics workspace that contains an Apache Spark pool named SparkPool1. SparkPool1 contains a Delta Lake table named SparkTable1. You need to recommend a solution that supports Transact-SQL queries against the data referenced by SparkTable1. The solution must ensure that the queries can use partition elimination. What should you include in the recommendation?
A. a partitioned table in a dedicated SQL pool
B. a partitioned view in a dedicated SQL pool
C. a partitioned index in a dedicated SQL pool
D. a partitioned view in a serverless SQL pool
DRAG DROP - You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName. You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values. You create the following components: ✑ A destination table in Azure Synapse ✑ An Azure Blob storage container ✑ A service principal Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:


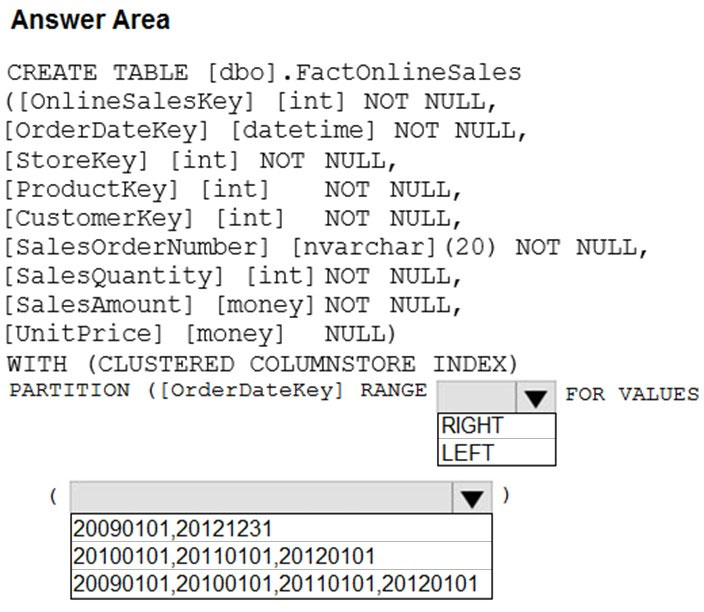
HOTSPOT - You have an enterprise data warehouse in Azure Synapse Analytics that contains a table named FactOnlineSales. The table contains data from the start of 2009 to the end of 2012. You need to improve the performance of queries against FactOnlineSales by using table partitions. The solution must meet the following requirements: ✑ Create four partitions based on the order date. ✑ Ensure that each partition contains all the orders placed during a given calendar year. How should you complete the T-SQL command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.FactPurchase will have 1 million rows of data added daily and will contain three years of data. Transact-SQL queries similar to the following query will be executed daily. SELECT - SupplierKey, StockItemKey, COUNT(*) FROM FactPurchase - WHERE DateKey >= 20210101 - AND DateKey <= 20210131 - GROUP By SupplierKey, StockItemKey Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on DateKey
HOTSPOT - You have Azure Data Factory configured with Azure Repos Git integration. The collaboration branch and the publish branch are set to the default values. You have a pipeline named pipeline1. You build a new version of pipeline1 in a branch named feature1. From the Data Factory Studio, you select Publish. The source code of which branch will be built, and which branch will contain the output of the Azure Resource Manager (ARM) template? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Storage account that contains 100 GB of files. The files contain rows of text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB. You plan to copy the data from the storage account to an enterprise data warehouse in Azure Synapse Analytics. You need to prepare the files to ensure that the data copies quickly. Solution: You modify the files to ensure that each row is less than 1 MB. Does this meet the goal?
A. Yes
B. No
You have an Azure Synapse Analytics workspace named WS1 that contains an Apache Spark pool named Pool1. You plan to create a database named DB1 in Pool1. You need to ensure that when tables are created in DB1, the tables are available automatically as external tables to the built-in serverless SQL pool. Which format should you use for the tables in DB1?
A. Parquet
B. ORC
C. JSON
D. HIVE
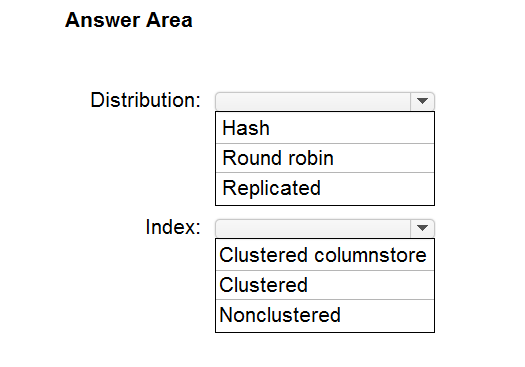
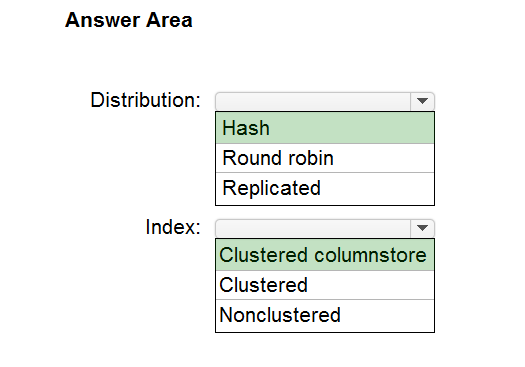
HOTSPOT - You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytics in a star schema. You plan to have a fact table for website visits. The table will be approximately 5 GB. You need to recommend which distribution type and index type to use for the table. The solution must provide the fastest query performance. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
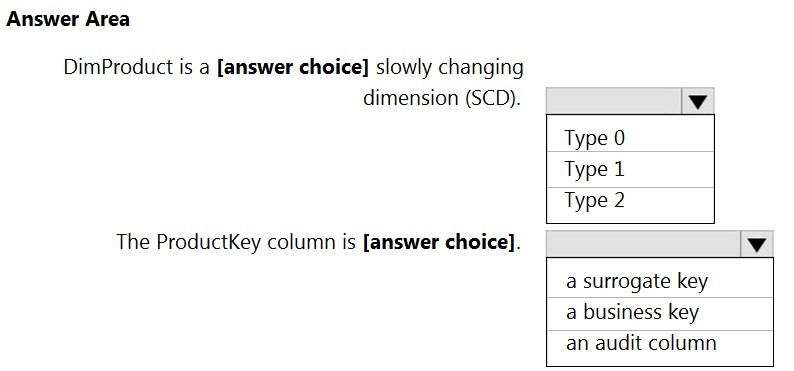
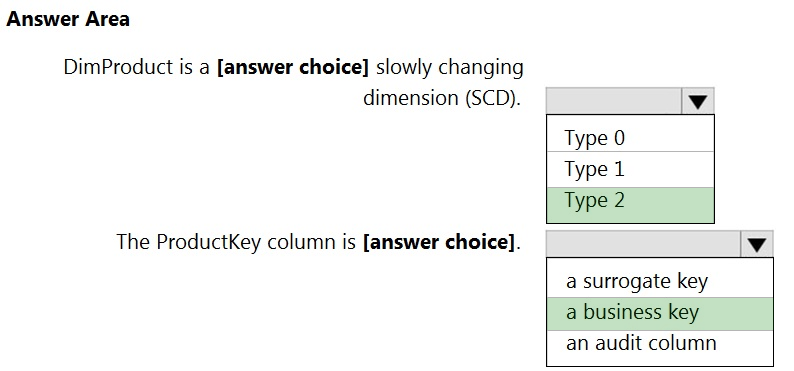
HOTSPOT - You are creating dimensions for a data warehouse in an Azure Synapse Analytics dedicated SQL pool. You create a table by using the Transact-SQL statement shown in the following exhibit.Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
You have an Azure Data Lake Storage Gen2 container that contains 100 TB of data. You need to ensure that the data in the container is available for read workloads in a secondary region if an outage occurs in the primary region. The solution must minimize costs. Which type of data redundancy should you use?
A. geo-redundant storage (GRS)
B. read-access geo-redundant storage (RA-GRS)
C. zone-redundant storage (ZRS)
D. locally-redundant storage (LRS)
HOTSPOT - You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a webpage. The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has a type of either 'start' or 'end'. You need to calculate the duration between start and end events. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You are designing an Azure Synapse Analytics dedicated SQL pool. You need to ensure that you can audit access to Personally Identifiable Information (PII). What should you include in the solution?
A. column-level security
B. dynamic data masking
C. row-level security (RLS)
D. sensitivity classifications
HOTSPOT - You have two Azure SQL databases named DB1 and DB2. DB1 contains a table named Table1. Table1 contains a timestamp column named LastModifiedOn. LastModifiedOn contains the timestamp of the most recent update for each individual row. DB2 contains a table named Watermark. Watermark contains a single timestamp column named WatermarkValue. You plan to create an Azure Data Factory pipeline that will incrementally upload into Azure Blob Storage all the rows in Table1 for which the LastModifiedOn column contains a timestamp newer than the most recent value of the WatermarkValue column in Watermark. You need to identify which activities to include in the pipeline. The solution must meet the following requirements: • Minimize the effort to author the pipeline. • Ensure that the number of data integration units allocated to the upload operation can be controlled. What should you identify? To answer, select the appropriate options in the answer area. NOTE: Each correct answer is worth one point.


You have an Azure subscription that contains an Azure Data Lake Storage account named dl1 and an Azure Analytics Synapse workspace named workspace1. You need to query the data in dl1 by using an Apache Spark pool named Pool1 in workspace1. The solution must ensure that the data is accessible Pool1. Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. Implement Azure Synapse Link.
B. Load the data to the primary storage account of workspace1.
C. From workspace1, create a linked service for the dl1.
D. From Microsoft Purview, register dl1 as a data source.
You have an Azure Synapse Analytics job that uses Scala. You need to view the status of the job. What should you do?
A. From Synapse Studio, select the workspace. From Monitor, select SQL requests.
B. From Azure Monitor, run a Kusto query against the AzureDiagnostics table.
C. From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications.
D. From Azure Monitor, run a Kusto query against the SparkLoggingEvent_CL table.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL. ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL. ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R. The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a High Concurrency cluster for the jobs. Does this meet the goal?
A. Yes
B. No
Access Full DP-203 Mock Test Free
Want a full-length mock test experience? Click here to unlock the complete DP-203 Mock Test Free set and get access to hundreds of additional practice questions covering all key topics.
We regularly update our question sets to stay aligned with the latest exam objectives—so check back often for fresh content!
Start practicing with our DP-203 mock test free today—and take a major step toward exam success!