

DP-203 Exam Prep Free – 50 Practice Questions to Get You Ready for Exam Day
Getting ready for the DP-203 certification? Our DP-203 Exam Prep Free resource includes 50 exam-style questions designed to help you practice effectively and feel confident on test day
Effective DP-203 exam prep free is the key to success. With our free practice questions, you can:
- Get familiar with exam format and question style
- Identify which topics you’ve mastered—and which need more review
- Boost your confidence and reduce exam anxiety
Below, you will find 50 realistic DP-203 Exam Prep Free questions that cover key exam topics. These questions are designed to reflect the structure and challenge level of the actual exam, making them perfect for your study routine.
You need to design a data retention solution for the Twitter feed data records. The solution must meet the customer sentiment analytics requirements. Which Azure Storage functionality should you include in the solution?
A. change feed
B. soft delete
C. time-based retention
D. lifecycle management
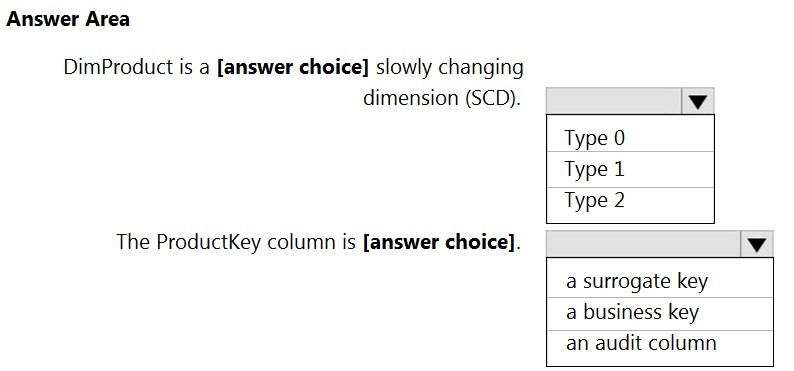
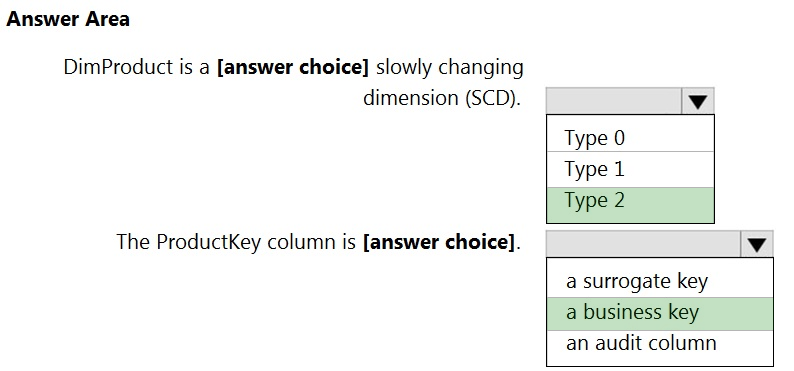
HOTSPOT - You are creating dimensions for a data warehouse in an Azure Synapse Analytics dedicated SQL pool. You create a table by using the Transact-SQL statement shown in the following exhibit.Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
You have an Azure Synapse Analytics workspace named WS1 that contains an Apache Spark pool named Pool1. You plan to create a database named DB1 in Pool1. You need to ensure that when tables are created in DB1, the tables are available automatically as external tables to the built-in serverless SQL pool. Which format should you use for the tables in DB1?
A. Parquet
B. ORC
C. JSON
D. HIVE
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical data store?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a server-level firewall IP rule
D. a database-level firewall IP rule
DRAG DROP - You have an Azure subscription that contains an Azure Data Lake Storage Gen2 account named account1 and a user named User1. In account1, you create a container named container1. In container1, you create a folder named folder1. You need to ensure that User1 can list and read all the files in folder1. The solution must use the principle of least privilege. How should you configure the permissions for each folder? To answer, drag the appropriate permissions to the correct folders. Each permission may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


HOTSPOT - You are developing an Azure Synapse Analytics pipeline that will include a mapping data flow named Dataflow1. Dataflow1 will read customer data from an external source and use a Type 1 slowly changing dimension (SCD) when loading the data into a table named DimCustomer in an Azure Synapse Analytics dedicated SQL pool. You need to ensure that Dataflow1 can perform the following tasks: • Detect whether the data of a given customer has changed in the DimCustomer table. • Perform an upsert to the DimCustomer table. Which type of transformation should you use for each task? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


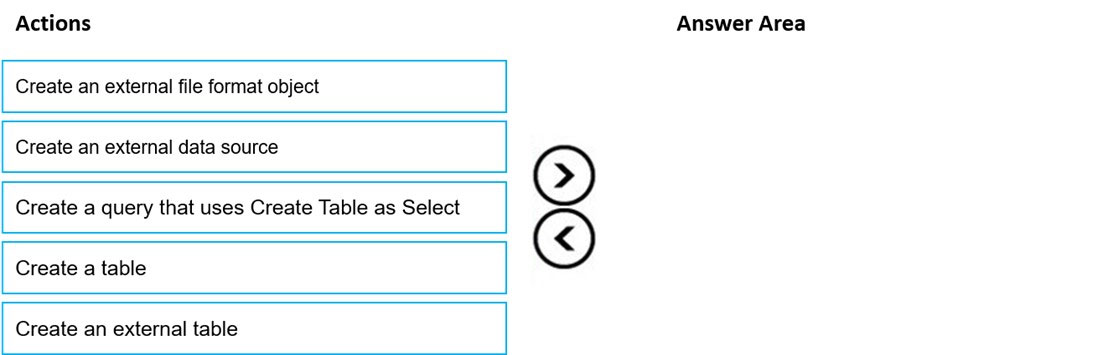
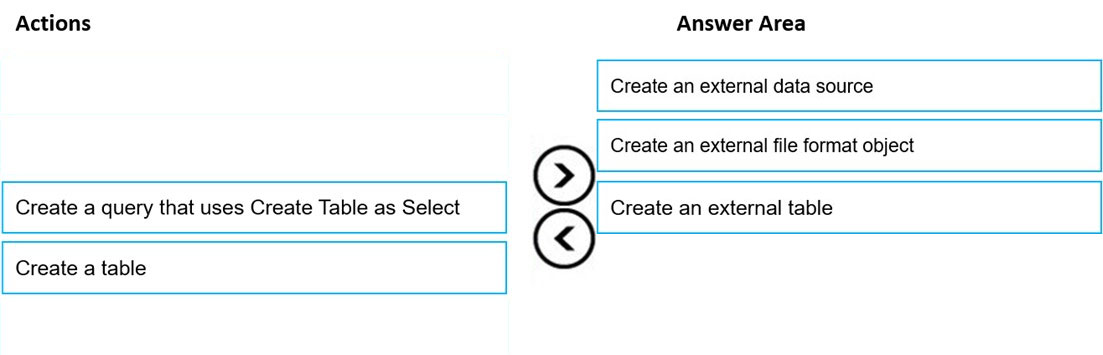
DRAG DROP - You need to build a solution to ensure that users can query specific files in an Azure Data Lake Storage Gen2 account from an Azure Synapse Analytics serverless SQL pool. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:
You have an Azure Synapse Analytics dedicated SQL pool named SA1 that contains a table named Table1. You need to identify tables that have a high percentage of deleted rows. What should you run?
A. sys.pdw_nodes_column_store_segments
B. sys.dm_db_column_store_row_group_operational_stats
C. sys.pdw_nodes_column_store_row_groups
D. sys.dm_db_column_store_row_group_physical_stats
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Storage account that contains 100 GB of files. The files contain rows of text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB. You plan to copy the data from the storage account to an enterprise data warehouse in Azure Synapse Analytics. You need to prepare the files to ensure that the data copies quickly. Solution: You modify the files to ensure that each row is more than 1 MB. Does this meet the goal?
A. Yes
B. No
You implement an enterprise data warehouse in Azure Synapse Analytics. You have a large fact table that is 10 terabytes (TB) in size. Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table:You need to distribute the large fact table across multiple nodes to optimize performance of the table. Which technology should you use?
A. hash distributed table with clustered index
B. hash distributed table with clustered Columnstore index
C. round robin distributed table with clustered index
D. round robin distributed table with clustered Columnstore index
E. heap table with distribution replicate
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1. You plan to insert data from the files in container1 into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1. You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1. Solution: You use an Azure Synapse Analytics serverless SQL pool to create an external table that has an additional DateTime column. Does this meet the goal?
A. Yes
B. No
DRAG DROP - You have an Azure Data Lake Storage account named account1. You use an Azure Synapse Analytics serverless SQL pool to access sales data stored in account1. You need to create a bar chart that displays sales by product. The solution must minimize development effort. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.You need to alter the table to meet the following requirements: ✑ Ensure that users can identify the current manager of employees. ✑ Support creating an employee reporting hierarchy for your entire company. ✑ Provide fast lookup of the managers' attributes such as name and job title. Which column should you add to the table?
A. [ManagerEmployeeID] [smallint] NULL
B. [ManagerEmployeeKey] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
DRAG DROP - You have a data warehouse. You need to implement a slowly changing dimension (SCD) named Product that will include three columns named ProductName, ProductColor, and ProductSize. The solution must meet the following requirements: • Prevent changes to the values stored in ProductName. • Retain only the current and the last values in ProductSize. • Retain all the current and previous values in ProductColor. Which type of SCD should you implement for each column? To answer, drag the appropriate types to the correct columns. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


You have an Azure subscription that contains an Azure Data Lake Storage account named dl1 and an Azure Analytics Synapse workspace named workspace1. You need to query the data in dl1 by using an Apache Spark pool named Pool1 in workspace1. The solution must ensure that the data is accessible Pool1. Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. Implement Azure Synapse Link.
B. Load the data to the primary storage account of workspace1.
C. From workspace1, create a linked service for the dl1.
D. From Microsoft Purview, register dl1 as a data source.
You have an Azure Synapse Analytics dedicated SQL pool. You need to create a fact table named Table1 that will store sales data from the last three years. The solution must be optimized for the following query operations: • Show order counts by week. • Calculate sales totals by region. • Calculate sales totals by product. • Find all the orders from a given month. Which data should you use to partition Table1?
A. product
B. month
C. week
D. region
You have an enterprise data warehouse in Azure Synapse Analytics. You need to monitor the data warehouse to identify whether you must scale up to a higher service level to accommodate the current workloads. Which is the best metric to monitor? More than one answer choice may achieve the goal. Select the BEST answer.
A. DWU used
B. CPU percentage
C. DWU percentage
D. Data IO percentage
HOTSPOT - You have an Azure subscription. You need to deploy an Azure Data Lake Storage Gen2 Premium account. The solution must meet the following requirements: * Blobs that are older than 365 days must be deleted. * Administrative effort must be minimized. * Costs must be minimized. What should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns and 5 billion rows and is a heap. Most queries against the table aggregate values from approximately 100 million rows and return only two columns. You discover that the queries against the fact table are very slow. Which type of index should you add to provide the fastest query times?
A. nonclustered columnstore
B. clustered columnstore
C. nonclustered
D. clustered
HOTSPOT - You have an Azure Data Lake Storage account that contains one CSV file per hour for January 1, 2020, through January 31, 2023. The files are partitioned by using the following folder structure.You need to query the files by using an Azure Synapse Analytics serverless SQL pool. The solution must return the row count of each file created during the last three months of 2022. How should you complete the query? To answer, select the appropriate options in the answer area.


You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. You need to monitor Pool1. The solution must ensure that you capture the start and end times of each query completed in Pool1. Which diagnostic setting should you use?
A. Sql Requests
B. Request Steps
C. Dms Workers
D. Exec Requests
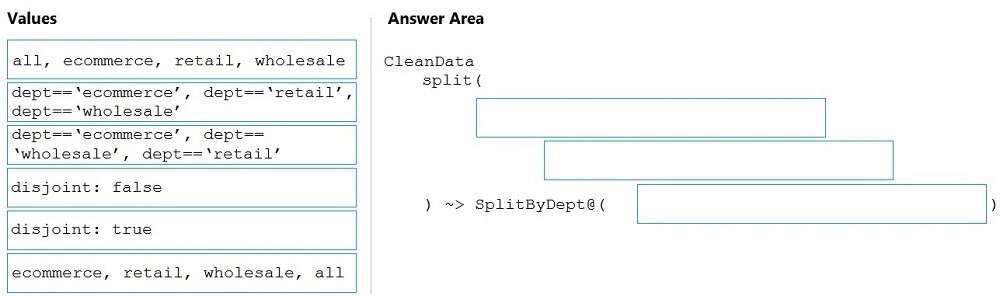
DRAG DROP - You need to create an Azure Data Factory pipeline to process data for the following three departments at your company: Ecommerce, retail, and wholesale. The solution must ensure that data can also be processed for the entire company. How should you complete the Data Factory data flow script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:

You have a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant contains a group named Group1. You have an Azure subscription that contains the resources shown in the following table.You need to ensure that members of Group1 can read CSV files from storage1 by using the OPENROWSET function. The solution must meet the following requirements: • The members of Group1 must use credential1 to access storage1. • The principle of least privilege must be followed. Which permission should you grant to Group1?
A. EXECUTE
B. CONTROL
C. REFERENCES
D. SELECT
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices. The company must be able to monitor the devices in real-time. You need to design the solution. What should you recommend?
A. Azure Analysis Services using Azure PowerShell
B. Azure Data Factory instance using Azure PowerShell
C. Azure Stream Analytics cloud job using Azure Portal
D. Azure Data Factory instance using Microsoft Visual Studio
HOTSPOT - You have an Azure Blob storage account that contains a folder. The folder contains 120,000 files. Each file contains 62 columns. Each day, 1,500 new files are added to the folder. You plan to incrementally load five data columns from each new file into an Azure Synapse Analytics workspace. You need to minimize how long it takes to perform the incremental loads. What should you use to store the files and in which format? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You manage an enterprise data warehouse in Azure Synapse Analytics. Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries. You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
A. DWU limit
B. Data IO percentage
C. Cache hit percentage
D. CPU percentage
DRAG DROP - You have an Azure Synapse Analytics dedicated SQL pool named SQL1 that contains a hash-distributed fact table named Table1. You need to recreate Table1 and add a new distribution column. The solution must maximize the availability of data. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


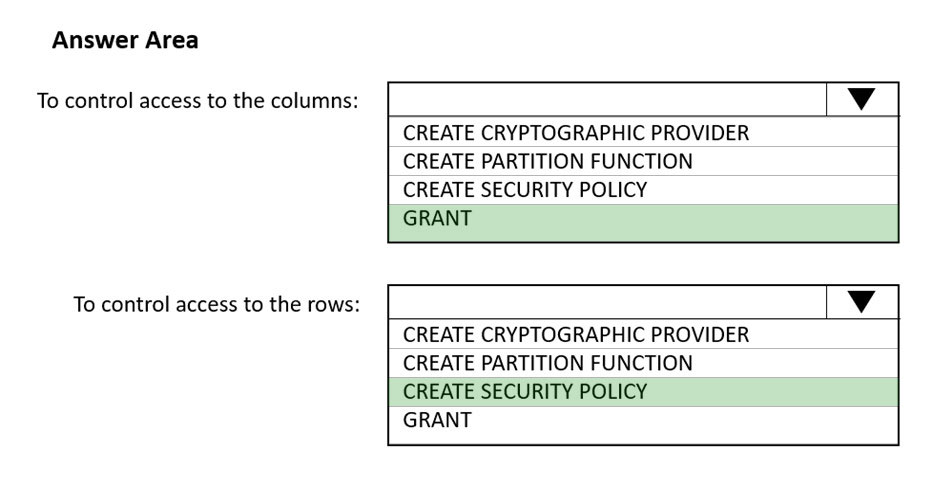
HOTSPOT - You have an Azure Synapse Analytics SQL pool named Pool1. In Azure Active Directory (Azure AD), you have a security group named Group1. You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

What should you do to improve high availability of the real-time data processing solution?
A. Deploy a High Concurrency Databricks cluster.
B. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
C. Set Data Lake Storage to use geo-redundant storage (GRS).
D. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
You have an Azure data factory named DF1. DF1 contains a single pipeline that is executed by using a schedule trigger. From Diagnostics settings, you configure pipeline runs to be sent to a resource-specific destination table in a Log Analytics workspace. You need to run KQL queries against the table. Which table should you query?
A. ADFPipelineRun
B. ADFTriggerRun
C. ADFActivityRun
D. AzureDiagnostics
You need to design an Azure Synapse Analytics dedicated SQL pool that meets the following requirements: ✑ Can return an employee record from a given point in time. ✑ Maintains the latest employee information. ✑ Minimizes query complexity. How should you model the employee data?
A. as a temporal table
B. as a SQL graph table
C. as a degenerate dimension table
D. as a Type 2 slowly changing dimension (SCD) table
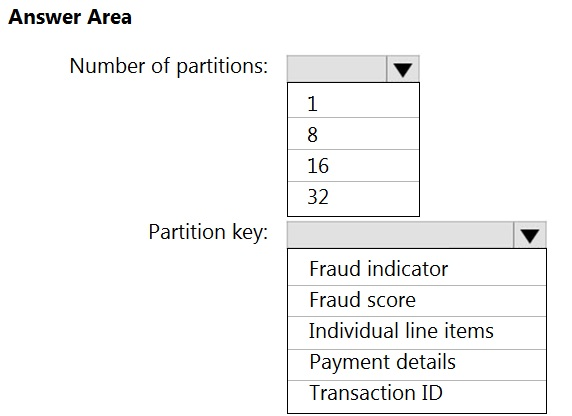
HOTSPOT - You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as the partition key. You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the payment details, a fraud score, and a fraud indicator. You plan to send the output to an Azure event hub named fraudhub. You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as possible. How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You have an Azure subscription that contains an Azure SQL database named DB1 and a storage account named storage1. The storage1 account contains a file named File1.txt. File1.txt contains the names of selected tables in DB1. You need to use an Azure Synapse pipeline to copy data from the selected tables in DB1 to the files in storage1. The solution must meet the following requirements: • The Copy activity in the pipeline must be parameterized to use the data in File1.txt to identify the source and destination of the copy. • Copy activities must occur in parallel as often as possible. Which two pipeline activities should you include in the pipeline? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Get Metadata
B. Lookup
C. ForEach
D. If Condition
HOTSPOT - You use Azure Data Factory to prepare data to be queried by Azure Synapse Analytics serverless SQL pools. Files are initially ingested into an Azure Data Lake Storage Gen2 account as 10 small JSON files. Each file contains the same data attributes and data from a subsidiary of your company. You need to move the files to a different folder and transform the data to meet the following requirements: ✑ Provide the fastest possible query times. ✑ Automatically infer the schema from the underlying files. How should you configure the Data Factory copy activity? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You are designing an Azure Stream Analytics job to process incoming events from sensors in retail environments. You need to process the events to produce a running average of shopper counts during the previous 15 minutes, calculated at five-minute intervals. Which type of window should you use?
A. snapshot
B. tumbling
C. hopping
D. sliding
HOTSPOT - You have an Azure Synapse Analytics dedicated SQL pool. You need to monitor the database for long-running queries and identify which queries are waiting on resources. Which dynamic management view should you use for each requirement? To answer, select the appropriate options in the answer area. NOTE: Each correct answer is worth one point.


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Data Lake Storage account that contains a staging zone. You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics. Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script. Does this meet the goal?
A. Yes
B. No
HOTSPOT - You have an Azure Synapse Analytics pipeline named Pipeline1 that contains a data flow activity named Dataflow1. Pipeline1 retrieves files from an Azure Data Lake Storage Gen 2 account named storage1. Dataflow1 uses the AutoResolveIntegrationRuntime integration runtime configured with a core count of 128. You need to optimize the number of cores used by Dataflow1 to accommodate the size of the files in storage1. What should you configure? To answer, select the appropriate options in the answer area. Hot Area:


You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. You have the queries shown in the following table.You are evaluating whether to enable result set caching for Pool1. Which query results will be cached if result set caching is enabled?
A. Query1 only
B. Query2 only
C. Query1 and Query2 only
D. Query1 and Query3 only
E. Query1, Query2, and Query3 only
You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.You create an external table named ExtTable that has LOCATION='/topfolder/'. When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
A. File2.csv and File3.csv only
B. File1.csv and File4.csv only
C. File1.csv, File2.csv, File3.csv, and File4.csv
D. File1.csv only
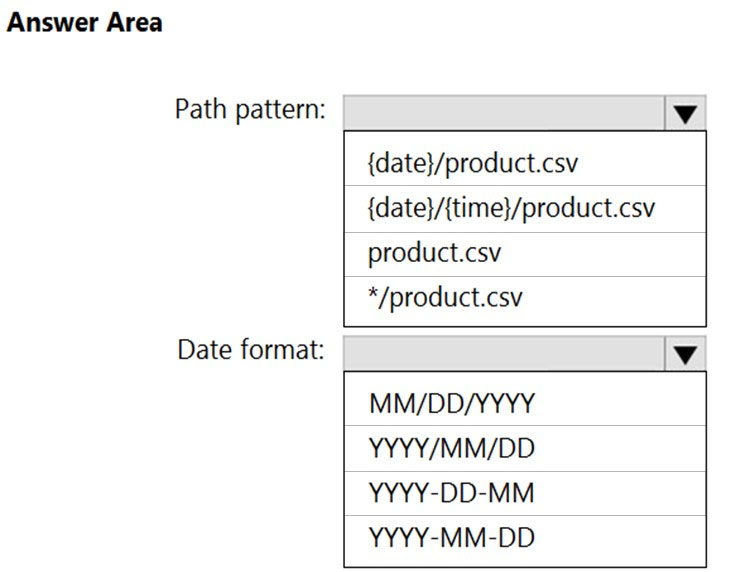
HOTSPOT - You are building an Azure Stream Analytics job that queries reference data from a product catalog file. The file is updated daily. The reference data input details for the file are shown in the Input exhibit. (Click the Input tab.)The storage account container view is shown in the Refdata exhibit. (Click the Refdata tab.)
You need to configure the Stream Analytics job to pick up the new reference data. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

DRAG DROP - You have an Azure Synapse Analytics workspace named Workspace1. You perform the following changes: • Implement source control for Workspace1. • Create a branch named Feature based on the collaboration branch. • Switch to the Feature branch. • Modify Workspace1. You need to publish the changes to Azure Synapse. From which branch should you perform each change? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point


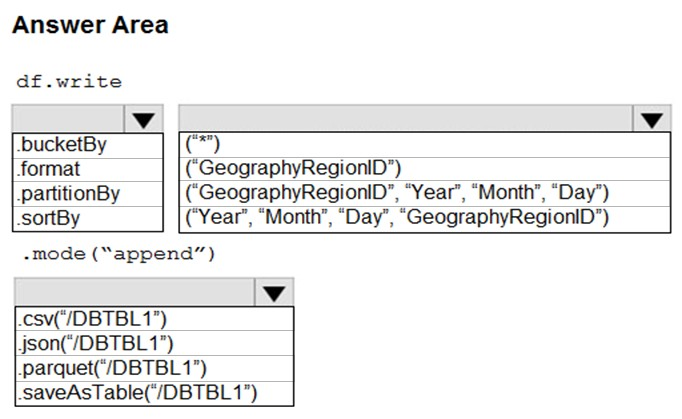
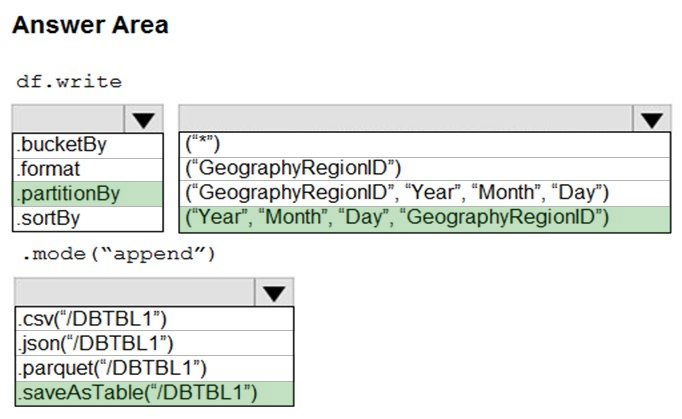
HOTSPOT - You develop a dataset named DBTBL1 by using Azure Databricks. DBTBL1 contains the following columns: ✑ SensorTypeID ✑ GeographyRegionID ✑ Year ✑ Month ✑ Day ✑ Hour ✑ Minute ✑ Temperature ✑ WindSpeed ✑ Other You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
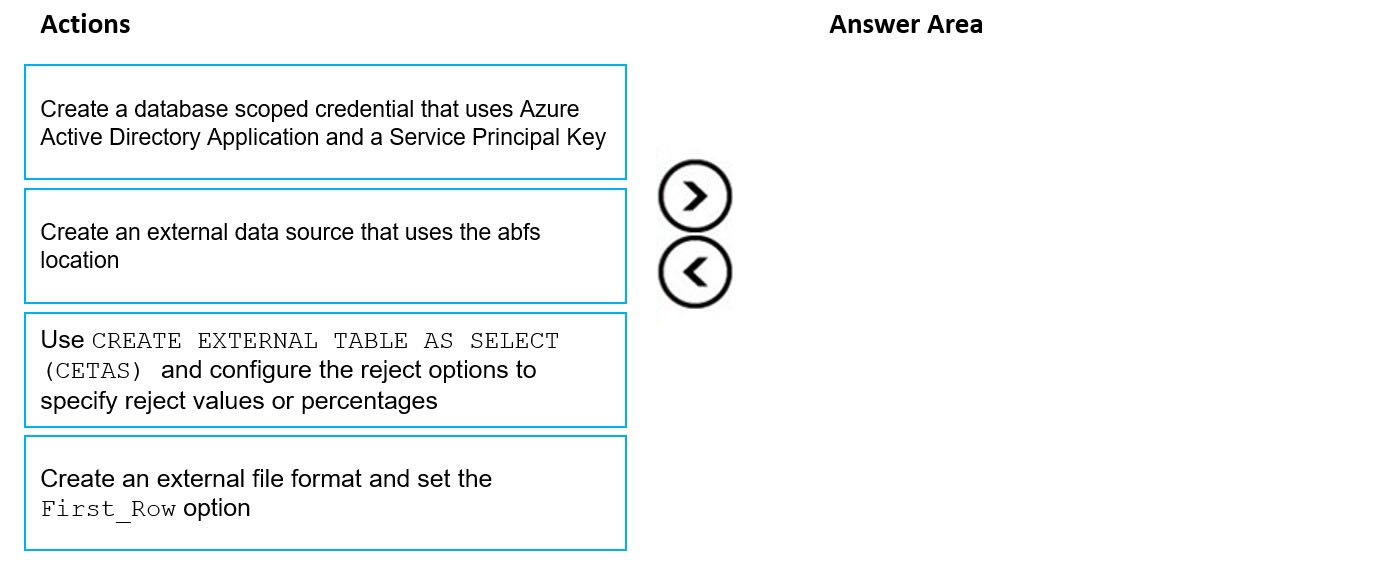
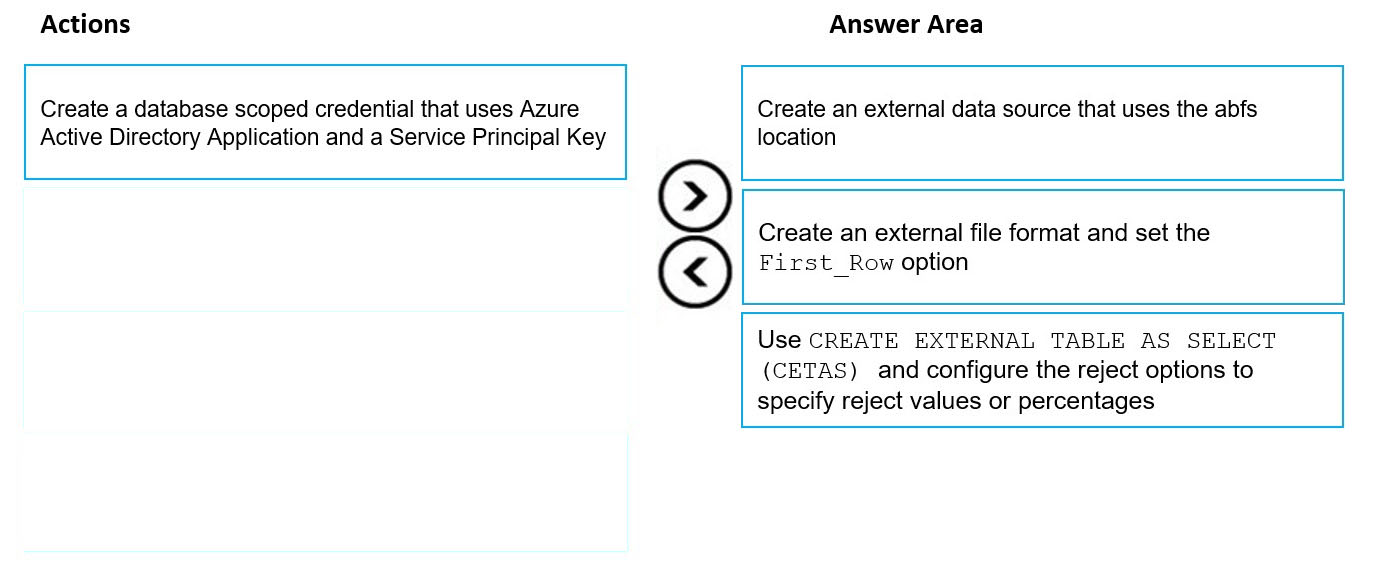
DRAG DROP - You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a properly formatted carriage return (/ r) and line feed (/n). You are implementing a pattern that batch loads the files daily into a dedicated SQL pool in Azure Synapse Analytics by using PolyBase. You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: Each correct selection is worth one point Select and Place:
HOTSPOT - You have an Azure Synapse Analytics serverless SQL pool. You have an Apache Parquet file that contains 10 columns. You need to query data from the file. The solution must return only two columns. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Stream Analytics job named Job1. The metrics of Job1 from the last hour are shown in the following table.The late arrival tolerance for Job1 is set to five seconds. You need to optimize Job1. Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. Increase the number of SUs.
B. Parallelize the query.
C. Resolve errors in output processing.
D. Resolve errors in input processing.
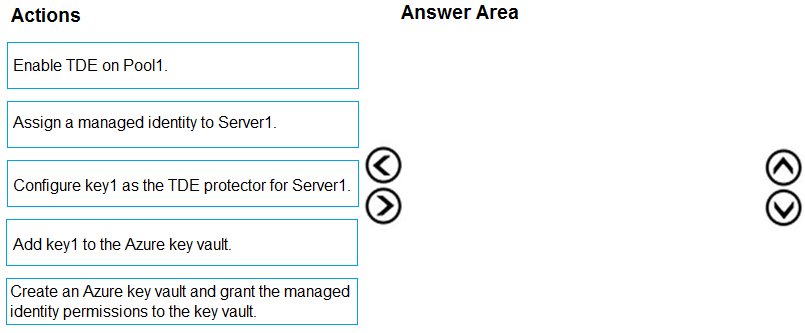
DRAG DROP - You have an Azure Synapse Analytics SQL pool named Pool1 on a logical Microsoft SQL server named Server1. You need to implement Transparent Data Encryption (TDE) on Pool1 by using a custom key named key1. Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

DRAG DROP - You are designing an Azure Data Lake Storage Gen2 structure for telemetry data from 25 million devices distributed across seven key geographical regions. Each minute, the devices will send a JSON payload of metrics to Azure Event Hubs. You need to recommend a folder structure for the data. The solution must meet the following requirements: ✑ Data engineers from each region must be able to build their own pipelines for the data of their respective region only. ✑ The data must be processed at least once every 15 minutes for inclusion in Azure Synapse Analytics serverless SQL pools. How should you recommend completing the structure? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


You have an Azure Synapse Analytics dedicated SQL pool named SQL1 and a user named User1. You need to ensure that User1 can view requests associated with SQL1 by querying the sys.dm_pdw_exec_requests dynamic management view. The solution must follow the principle of least privilege. Which permission should you grant to User1?
A. VIEW DATABASE STATE
B. SHOWPLAN
C. CONTROL SERVER
D. VIEW ANY DATABASE
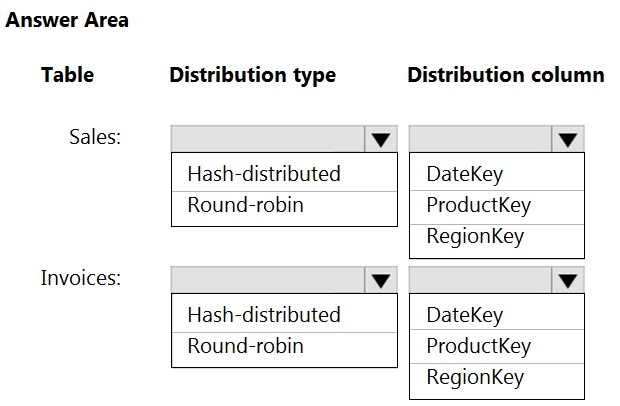
HOTSPOT - You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.Queries that use the data warehouse take a long time to complete. You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point Hot Area:

Access Full DP-203 Exam Prep Free
Want to go beyond these 50 questions? Click here to unlock a full set of DP-203 exam prep free questions covering every domain tested on the exam.
We continuously update our content to ensure you have the most current and effective prep materials.
Good luck with your DP-203 certification journey!