

DP-203 Dump Free – 50 Practice Questions to Sharpen Your Exam Readiness.
Looking for a reliable way to prepare for your DP-203 certification? Our DP-203 Dump Free includes 50 exam-style practice questions designed to reflect real test scenarios—helping you study smarter and pass with confidence.
Using an DP-203 dump free set of questions can give you an edge in your exam prep by helping you:
- Understand the format and types of questions you’ll face
- Pinpoint weak areas and focus your study efforts
- Boost your confidence with realistic question practice
Below, you will find 50 free questions from our DP-203 Dump Free collection. These cover key topics and are structured to simulate the difficulty level of the real exam, making them a valuable tool for review or final prep.
You are designing a folder structure for the files in an Azure Data Lake Storage Gen2 account. The account has one container that contains three years of data. You need to recommend a folder structure that meets the following requirements: ✑ Supports partition elimination for queries by Azure Synapse Analytics serverless SQL pools ✑ Supports fast data retrieval for data from the current month ✑ Simplifies data security management by department Which folder structure should you recommend?
A. DepartmentDataSourceYYYYMMDataFile_YYYYMMDD.parquet
B. DataSourceDepartmentYYYYMMDataFile_YYYYMMDD.parquet
C. DDMMYYYYDepartmentDataSourceDataFile_DDMMYY.parquet
D. YYYYMMDDDepartmentDataSourceDataFile_YYYYMMDD.parquet
You are designing an Azure Databricks cluster that runs user-defined local processes. You need to recommend a cluster configuration that meets the following requirements: ✑ Minimize query latency. ✑ Maximize the number of users that can run queries on the cluster at the same time. ✑ Reduce overall costs without compromising other requirements. Which cluster type should you recommend?
A. Standard with Auto Termination
B. High Concurrency with Autoscaling
C. High Concurrency with Auto Termination
D. Standard with Autoscaling
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named clusterID. You monitor the Stream Analytics job and discover high latency. You need to reduce the latency. Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add a pass-through query.
B. Increase the number of streaming units.
C. Add a temporal analytic function.
D. Scale out the query by using PARTITION BY.
E. Convert the query to a reference query.
HOTSPOT - You have an Azure Synapse Analytics workspace that contains three pipelines and three triggers named Trigger1, Trigger2, and Trigger3. Trigger3 has the following definition.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You are designing a solution that will use tables in Delta Lake on Azure Databricks. You need to minimize how long it takes to perform the following: • Queries against non-partitioned tables • Joins on non-partitioned columns Which two options should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. the clone command
B. Z-Ordering
C. Apache Spark caching
D. dynamic file pruning (DFP)
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table. Which output mode should you use?
A. update
B. complete
C. append
You have an Azure Data Factory pipeline named pipeline1 that contains a data flow activity named activity1. You need to run pipeline1. Which runtime will be used to run activity1?
A. Azure Integration runtime
B. Self-hosted integration runtime
C. SSIS integration runtime
You configure monitoring for an Azure Synapse Analytics implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Storage Gen2 using an external table. Files with an invalid schema cause errors to occur. You need to monitor for an invalid schema error. For which error should you monitor?
A. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [com.microsoft.polybase.client.KerberosSecureLogin] occurred while accessing external file.’
B. Cannot execute the query “Remote Query” against OLE DB provider “SQLNCLI11” for linked server “(null)”. Query aborted- the maximum reject threshold (0 rows) was reached while reading from an external source: 1 rows rejected out of total 1 rows processed.
C. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [Unable to instantiate LoginClass] occurred while accessing external file.’
D. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [No FileSystem for scheme: wasbs] occurred while accessing external file.’
HOTSPOT - You have an Azure subscription that contains the Azure Synapse Analytics workspaces shown in the following table.Each workspace must read and write data to datalake1. Each workspace contains an unused Apache Spark pool. You plan to configure each Spark pool to share catalog objects that reference datalake1. For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL. ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL. ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R. The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a High Concurrency cluster for the jobs. Does this meet the goal?
A. Yes
B. No
You have an Azure Stream Analytics job named Job1. The metrics of Job1 from the last hour are shown in the following table.The late arrival tolerance for Job1 is set to five seconds. You need to optimize Job1. Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. Increase the number of SUs.
B. Parallelize the query.
C. Resolve errors in output processing.
D. Resolve errors in input processing.
You have a Log Analytics workspace named la1 and an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 sends logs to la1. You need to identify whether a recently executed query on Pool1 used the result set cache. What are two ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Review the sys.dm_pdw_sql_requests dynamic management view in Pool1.
B. Review the sys.dm_pdw_exec_requests dynamic management view in Pool1.
C. Use the Monitor hub in Synapse Studio.
D. Review the AzureDiagnostics table in la1.
E. Review the sys.dm_pdw_request_steps dynamic management view in Pool1.
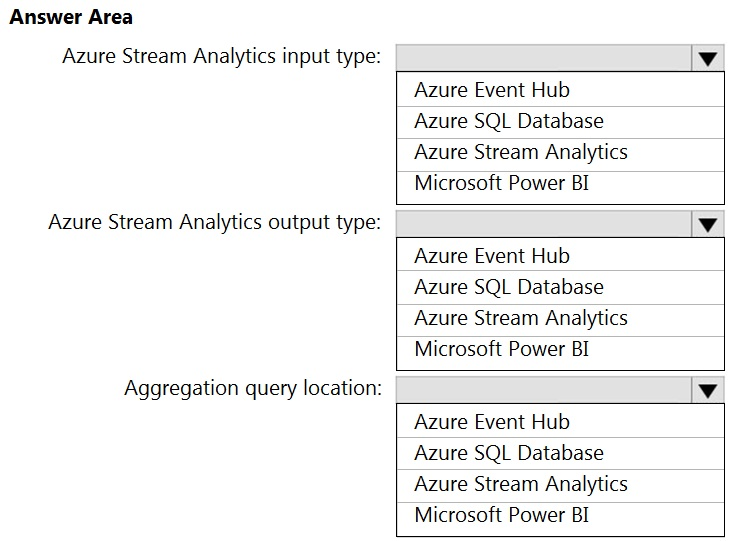
HOTSPOT - You are designing a near real-time dashboard solution that will visualize streaming data from remote sensors that connect to the internet. The streaming data must be aggregated to show the average value of each 10-second interval. The data will be discarded after being displayed in the dashboard. The solution will use Azure Stream Analytics and must meet the following requirements: ✑ Minimize latency from an Azure Event hub to the dashboard. ✑ Minimize the required storage. ✑ Minimize development effort. What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point Hot Area:

You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1. You need to determine the size of the transaction log file for each distribution of DW1. What should you do?
A. On DW1, execute a query against the sys.database_files dynamic management view.
B. From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
C. Execute a query against the logs of DW1 by using the Get-AzOperationalInsightsSearchResult PowerShell cmdlet.
D. On the master database, execute a query against the sys.dm_pdw_nodes_os_performance_counters dynamic management view.
You manage an enterprise data warehouse in Azure Synapse Analytics. Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries. You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
A. DWU percentage
B. Cache hit percentage
C. DWU limit
D. Data IO percentage
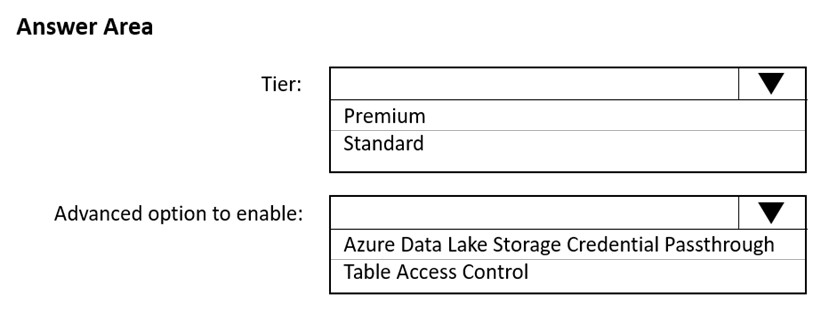
HOTSPOT - You need to implement an Azure Databricks cluster that automatically connects to Azure Data Lake Storage Gen2 by using Azure Active Directory (Azure AD) integration. How should you configure the new cluster? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

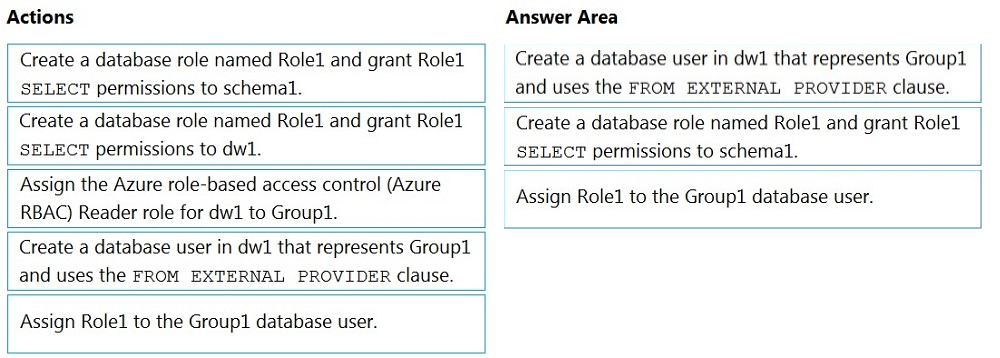
DRAG DROP - You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1. You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:

DRAG DROP - You have an Azure Synapse Analytics dedicated SQL pool. You need to create a copy of the data warehouse and make the copy available for 28 days. The solution must minimize costs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure data factory named ADF1. From Azure Data Factory Studio, you build a complex data pipeline in ADF1. You discover that the Save button is unavailable, and there are validation errors that prevent the pipeline from being published. You need to ensure that you can save the logic of the pipeline. Solution: You disable all the triggers for ADF1. Does this meet the goal?
A. Yes
B. No
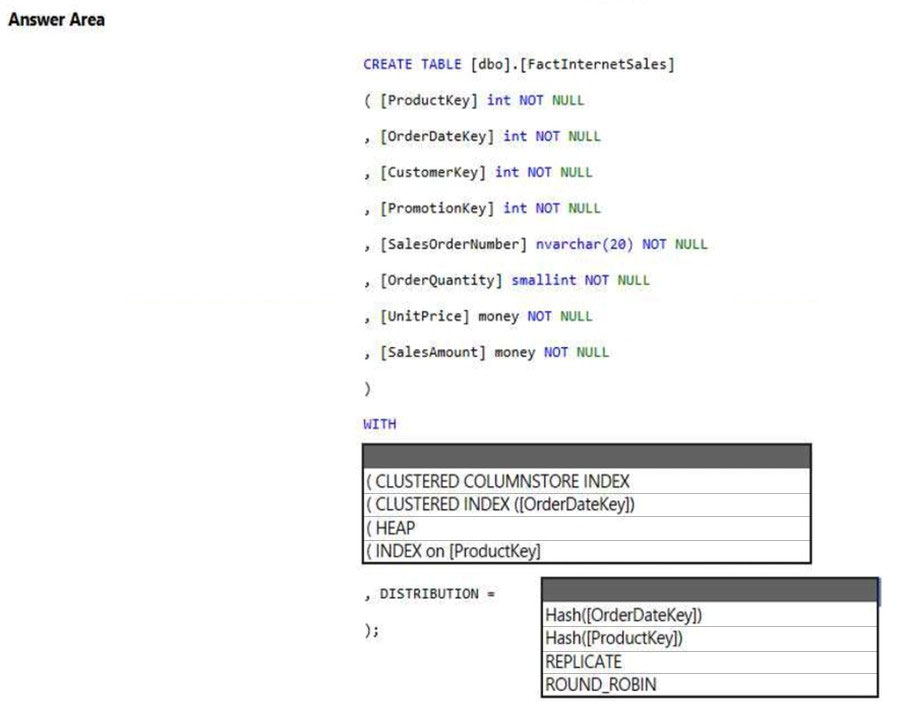
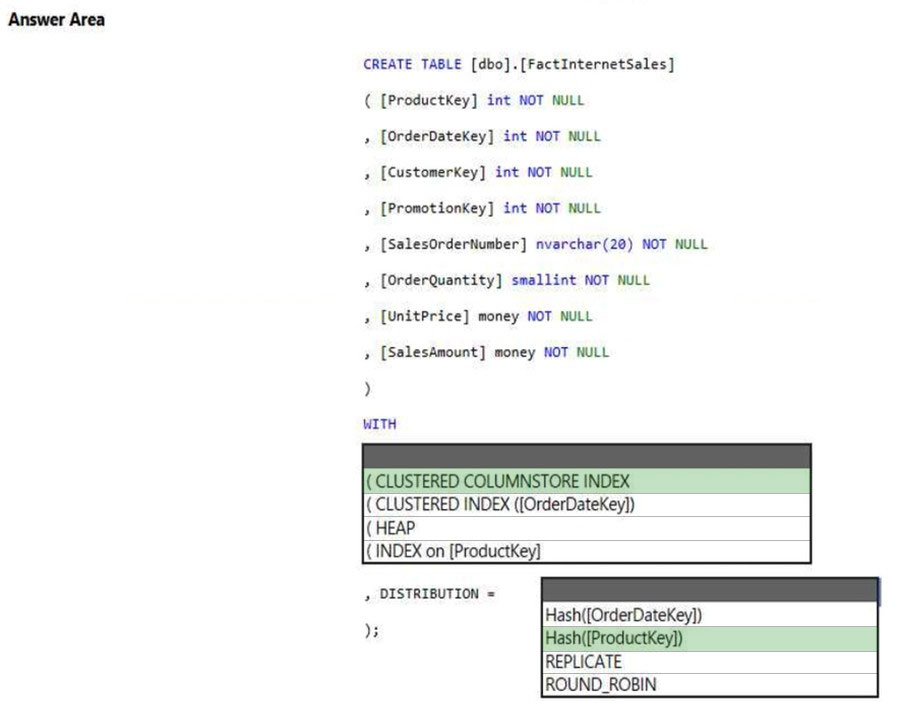
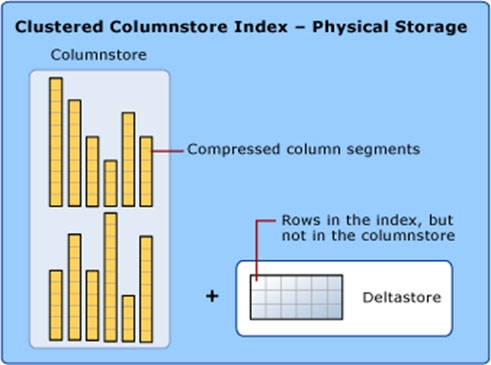
HOTSPOT - You have an Azure Synapse Analytics dedicated SQL pool. You need to create a table named FactInternetSales that will be a large fact table in a dimensional model. FactInternetSales will contain 100 million rows and two columns named SalesAmount and OrderQuantity. Queries executed on FactInternetSales will aggregate the values in SalesAmount and OrderQuantity from the last year for a specific product. The solution must minimize the data size and query execution time. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have two fact tables named Flight and Weather. Queries targeting the tables will be based on the join between the following columns.You need to recommend a solution that maximizes query performance. What should you include in the recommendation?
A. In the tables use a hash distribution of ArrivalDateTime and ReportDateTime.
B. In the tables use a hash distribution of ArrivalAirportID and AirportID.
C. In each table, create an IDENTITY column.
D. In each table, create a column as a composite of the other two columns in the table.
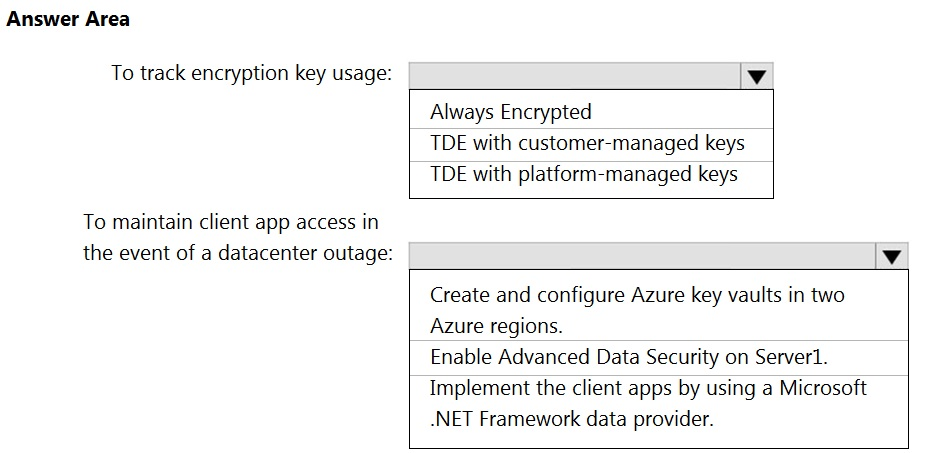
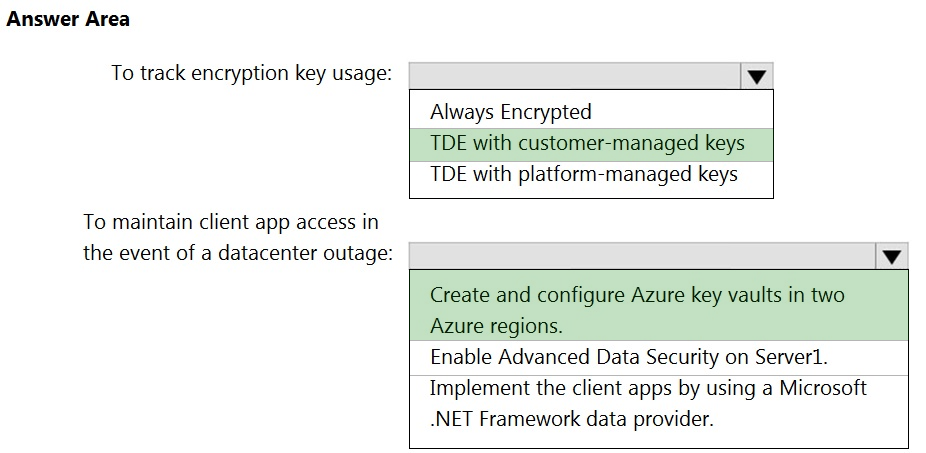
HOTSPOT - You have an Azure subscription that contains a logical Microsoft SQL server named Server1. Server1 hosts an Azure Synapse Analytics SQL dedicated pool named Pool1. You need to recommend a Transparent Data Encryption (TDE) solution for Server1. The solution must meet the following requirements: ✑ Track the usage of encryption keys. Maintain the access of client apps to Pool1 in the event of an Azure datacenter outage that affects the availability of the encryption keys.What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have an Azure Synapse Analytics dedicated SQL pool. You need to create a fact table named Table1 that will store sales data from the last three years. The solution must be optimized for the following query operations: • Show order counts by week. • Calculate sales totals by region. • Calculate sales totals by product. • Find all the orders from a given month. Which data should you use to partition Table1?
A. product
B. month
C. week
D. region
DRAG DROP - You have an Azure subscription. You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model. Pool1 will contain the following tables.You need to design the table storage for pool1. The solution must meet the following requirements: ✑ Maximize the performance of data loading operations to Staging.WebSessions. ✑ Minimize query times for reporting queries against the dimensional model. Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


You develop data engineering solutions for a company. A project requires the deployment of data to Azure Data Lake Storage. You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create security groups in Azure Active Directory (Azure AD) and add project members.
B. Configure end-user authentication for the Azure Data Lake Storage account.
C. Assign Azure AD security groups to Azure Data Lake Storage.
D. Configure Service-to-service authentication for the Azure Data Lake Storage account.
E. Configure access control lists (ACL) for the Azure Data Lake Storage account.
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.FactPurchase will have 1 million rows of data added daily and will contain three years of data. Transact-SQL queries similar to the following query will be executed daily. SELECT - SupplierKey, StockItemKey, COUNT(*) FROM FactPurchase - WHERE DateKey >= 20210101 - AND DateKey <= 20210131 - GROUP By SupplierKey, StockItemKey Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on DateKey
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination. You need to ensure that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs. What should you do?
A. Pin the cluster.
B. Create an Azure runbook that starts the cluster every 90 days.
C. Terminate the cluster manually when processing completes.
D. Clone the cluster after it is terminated.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Data Lake Storage account that contains a staging zone. You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics. Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse. Does this meet the goal?
A. Yes
B. No
You are planning a streaming data solution that will use Azure Databricks. The solution will stream sales transaction data from an online store. The solution has the following specifications: The output data will contain items purchased, quantity, line total sales amount, and line total tax amount.✑ Line total sales amount and line total tax amount will be aggregated in Databricks. ✑ Sales transactions will never be updated. Instead, new rows will be added to adjust a sale. You need to recommend an output mode for the dataset that will be processed by using Structured Streaming. The solution must minimize duplicate data. What should you recommend?
A. Update
B. Complete
C. Append
You have an Azure Synapse Analytics workspace. You plan to deploy a lake database by using a database template in Azure Synapse. Which two elements are included in the template? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. relationships
B. data formats
C. linked services
D. table permissions
E. table definitions
You are creating an Azure Data Factory pipeline. You need to add an activity to the pipeline. The activity must execute a Transact-SQL stored procedure that has the following characteristics: • Returns the number of sales invoices for a current date • Does NOT require input parameters Which type on activity should you use?
A. Stored Procedure
B. Get Metadata
C. Append Variable
D. Lookup
DRAG DROP - You have an Azure Data Lake Storage account named account1. You use an Azure Synapse Analytics serverless SQL pool to access sales data stored in account1. You need to create a bar chart that displays sales by product. The solution must minimize development effort. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Contacts. Contacts contains a column named Phone. You need to ensure that users in a specific role only see the last four digits of a phone number when querying the Phone column. What should you include in the solution?
A. table partitions
B. a default value
C. row-level security (RLS)
D. column encryption
E. dynamic data masking
You have an Azure Synapse Analytics dedicated SQL pool named SQL1 and a user named User1. You need to ensure that User1 can view requests associated with SQL1 by querying the sys.dm_pdw_exec_requests dynamic management view. The solution must follow the principle of least privilege. Which permission should you grant to User1?
A. VIEW DATABASE STATE
B. SHOWPLAN
C. CONTROL SERVER
D. VIEW ANY DATABASE
HOTSPOT - You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns: ✑ ProductID ✑ ItemPrice ✑ LineTotal ✑ Quantity ✑ StoreID ✑ Minute ✑ Month ✑ Hour Year -✑ Day You need to store the data to support hourly incremental load pipelines that will vary for each Store ID. The solution must minimize storage costs. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have an on-premises Linux server that contains a database named DB1. You have an Azure subscription that contains an Azure data factory named ADF1 and an Azure Data Lake Storage account named ADLS1. You need to create a pipeline in ADF1 that will copy data from DB1 to ADLS1. Which type of integration runtime should you use to read the data from DB1?
A. self-hosted integration runtime
B. Azure integration runtime
C. Azure-SQL Server Integration Services (SSIS)
You manage an enterprise data warehouse in Azure Synapse Analytics. Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries. You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
A. DWU limit
B. Cache hit percentage
C. Local tempdb percentage
D. Data IO percentage
HOTSPOT - You have an Azure Blob storage account that contains a folder. The folder contains 120,000 files. Each file contains 62 columns. Each day, 1,500 new files are added to the folder. You plan to incrementally load five data columns from each new file into an Azure Synapse Analytics workspace. You need to minimize how long it takes to perform the incremental loads. What should you use to store the files and in which format? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have a SQL pool in Azure Synapse. A user reports that queries against the pool take longer than expected to complete. You determine that the issue relates to queried columnstore segments. You need to add monitoring to the underlying storage to help diagnose the issue. Which two metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Snapshot Storage Size
B. Cache used percentage
C. DWU Limit
D. Cache hit percentage
You have an Azure subscription that contains an Azure Data Lake Storage Gen2 account named account1 and an Azure Synapse Analytics workspace named workspace1. You need to create an external table in a serverless SQL pool in workspace1. The external table will reference CSV files stored in account1. The solution must maximize performance. How should you configure the external table?
A. Use a native external table and authenticate by using a shared access signature (SAS).
B. Use a native external table and authenticate by using a storage account key.
C. Use an Apache Hadoop external table and authenticate by using a shared access signature (SAS).
D. Use an Apache Hadoop external table and authenticate by using a service principal in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra.
You have an Azure subscription that is linked to a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant that contains a security group named Group1. The subscription contains an Azure Data Lake Storage account named myaccount1. The myaccount1 account contains two containers named container1 and container2. You need to grant Group1 read access to container1. The solution must use the principle of least privilege. Which role should you assign to Group1?
A. Storage Table Data Reader for myaccount1
B. Storage Blob Data Reader for container1
C. Storage Blob Data Reader for myaccount1
D. Storage Table Data Reader for container1
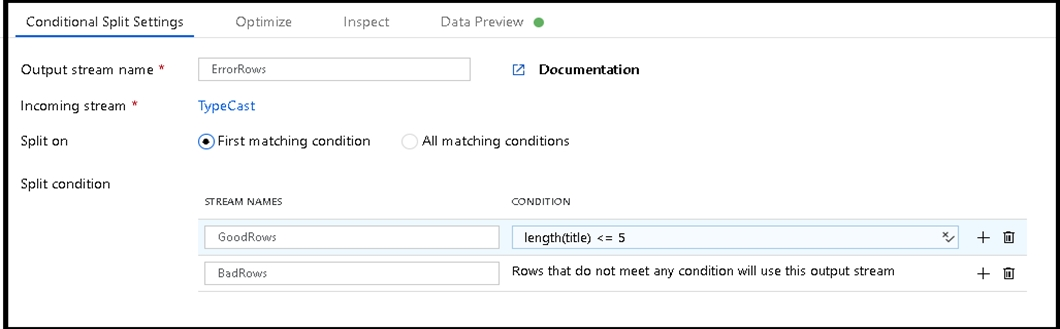
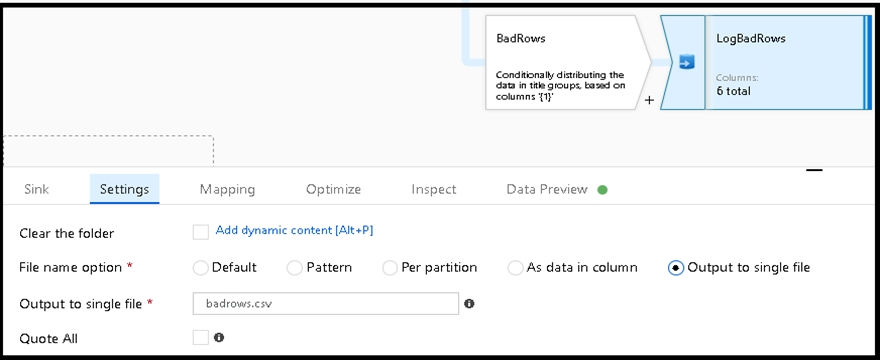
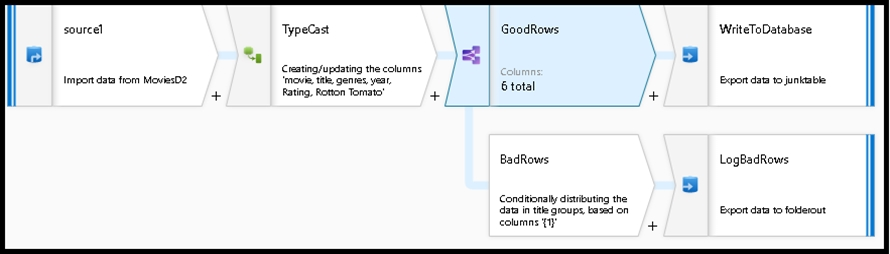
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three columns named username, comment, and date. The data flow already contains the following: ✑ A source transformation. ✑ A Derived Column transformation to set the appropriate types of data. ✑ A sink transformation to land the data in the pool. You need to ensure that the data flow meets the following requirements: ✑ All valid rows must be written to the destination table. ✑ Truncation errors in the comment column must be avoided proactively. ✑ Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob storage. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. To the data flow, add a sink transformation to write the rows to a file in blob storage.
B. To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
C. To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
D. Add a select transformation to select only the rows that will cause truncation errors.
You have an Azure Data Factory pipeline named Pipeline1. Pipeline1 contains a copy activity that sends data to an Azure Data Lake Storage Gen2 account. Pipeline1 is executed by a schedule trigger. You change the copy activity sink to a new storage account and merge the changes into the collaboration branch. After Pipeline1 executes, you discover that data is NOT copied to the new storage account. You need to ensure that the data is copied to the new storage account. What should you do?
A. Publish from the collaboration branch.
B. Create a pull request.
C. Modify the schedule trigger.
D. Configure the change feed of the new storage account.
You have an Azure subscription that contains an Azure Synapse Analytics workspace and a user named User1. You need to ensure that User1 can review the Azure Synapse Analytics database templates from the gallery. The solution must follow the principle of least privilege. Which role should you assign to User1?
A. Storage Blob Data Contributor.
B. Synapse Administrator
C. Synapse Contributor
D. Synapse User
You are designing a highly available Azure Data Lake Storage solution that will include geo-zone-redundant storage (GZRS). You need to monitor for replication delays that can affect the recovery point objective (RPO). What should you include in the monitoring solution?
A. 5xx: Server Error errors
B. Average Success E2E Latency
C. availability
D. Last Sync Time
You use Azure Stream Analytics to receive data from Azure Event Hubs and to output the data to an Azure Blob Storage account. You need to output the count of records received from the last five minutes every minute. Which windowing function should you use?
A. Session
B. Tumbling
C. Sliding
D. Hopping
You create an Azure Databricks cluster and specify an additional library to install. When you attempt to load the library to a notebook, the library in not found. You need to identify the cause of the issue. What should you review?
A. notebook logs
B. cluster event logs
C. global init scripts logs
D. workspace logs
DRAG DROP - You are designing an Azure Data Lake Storage Gen2 structure for telemetry data from 25 million devices distributed across seven key geographical regions. Each minute, the devices will send a JSON payload of metrics to Azure Event Hubs. You need to recommend a folder structure for the data. The solution must meet the following requirements: ✑ Data engineers from each region must be able to build their own pipelines for the data of their respective region only. ✑ The data must be processed at least once every 15 minutes for inclusion in Azure Synapse Analytics serverless SQL pools. How should you recommend completing the structure? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


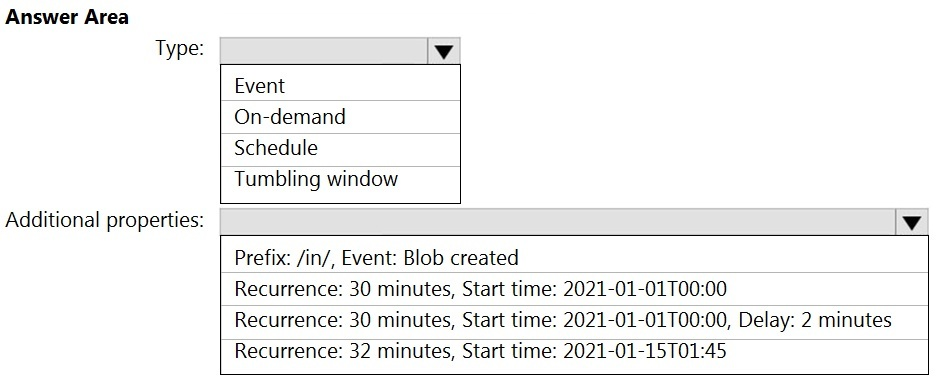
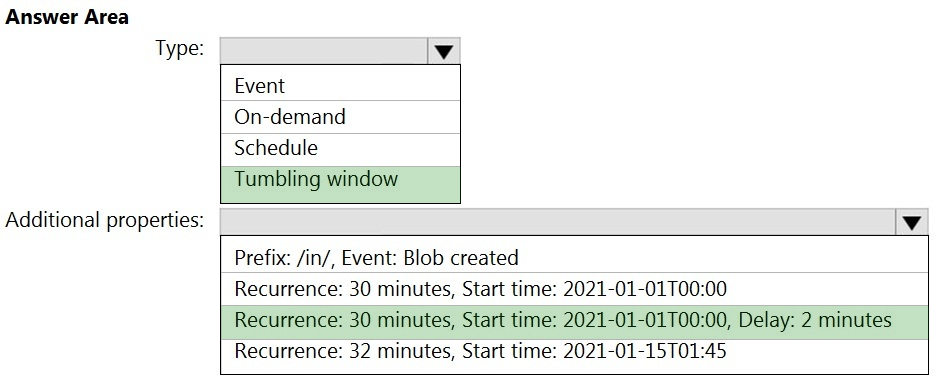
HOTSPOT -
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database in an Azure Synapse Analytics dedicated
SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
✑ Existing data must be loaded.
✑ Data must be loaded every 30 minutes.
✑ Late-arriving data of up to two minutes must be included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
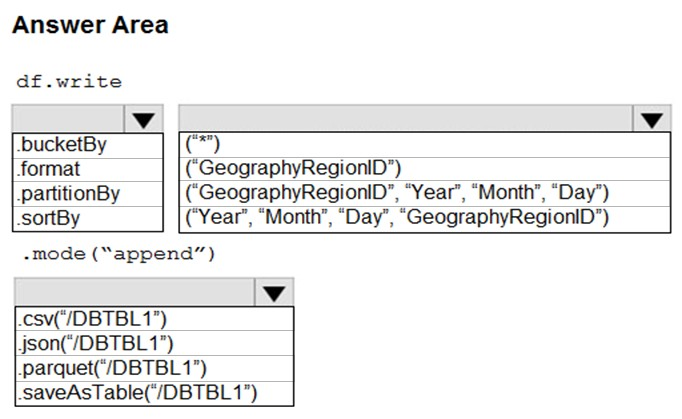
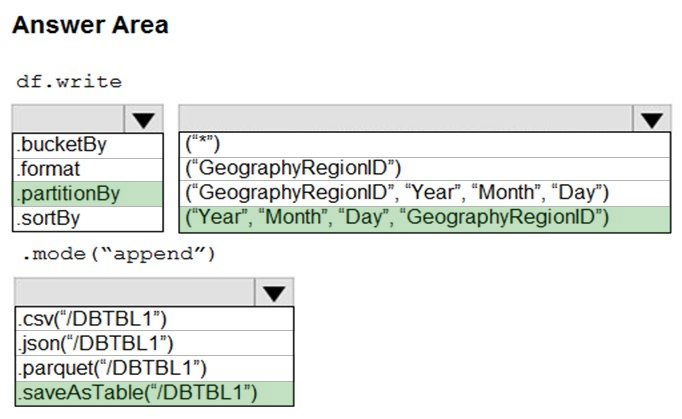
HOTSPOT - You develop a dataset named DBTBL1 by using Azure Databricks. DBTBL1 contains the following columns: ✑ SensorTypeID ✑ GeographyRegionID ✑ Year ✑ Month ✑ Day ✑ Hour ✑ Minute ✑ Temperature ✑ WindSpeed ✑ Other You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Access Full DP-203 Dump Free
Looking for even more practice questions? Click here to access the complete DP-203 Dump Free collection, offering hundreds of questions across all exam objectives.
We regularly update our content to ensure accuracy and relevance—so be sure to check back for new material.
Begin your certification journey today with our DP-203 dump free questions — and get one step closer to exam success!