DP-201 Practice Test Free – 50 Real Exam Questions to Boost Your Confidence
Preparing for the DP-201 exam? Start with our DP-201 Practice Test Free – a set of 50 high-quality, exam-style questions crafted to help you assess your knowledge and improve your chances of passing on the first try.
Taking a DP-201 practice test free is one of the smartest ways to:
Get familiar with the real exam format and question types
Evaluate your strengths and spot knowledge gaps
Gain the confidence you need to succeed on exam day
Below, you will find 50 free DP-201 practice questions to help you prepare for the exam. These questions are designed to reflect the real exam structure and difficulty level. You can click on each Question to explore the details.
You need to recommend a storage solution to store flat files and columnar optimized files. The solution must meet the following requirements:
✑ Store standardized data that data scientists will explore in a curated folder.
✑ Ensure that applications cannot access the curated folder.
✑ Store staged data for import to applications in a raw folder.
✑ Provide data scientists with access to specific folders in the raw folder and all the content the curated folder.
Which storage solution should you recommend?
A. Azure Synapse Analytics
B. Azure Blob storage
C. Azure Data Lake Storage Gen2
D. Azure SQL Database
Suggested Answer: B
Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Incorrect Answers:
C: Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/data-storage
You are designing a solution for a company. The solution will use model training for objective classification.
You need to design the solution.
What should you recommend?
A. an Azure Cognitive Services application
B. a Spark Streaming job
C. interactive Spark queries
D. Power BI models
E. a Spark application that uses Spark MLib.
Suggested Answer: E
Spark in SQL Server big data cluster enables AI and machine learning.
You can use Apache Spark MLlib to create a machine learning application to do simple predictive analysis on an open dataset.
MLlib is a core Spark library that provides many utilities useful for machine learning tasks, including utilities that are suitable for:
✑ Classification
✑ Regression
✑ Clustering
✑ Topic modeling
✑ Singular value decomposition (SVD) and principal component analysis (PCA)
✑ Hypothesis testing and calculating sample statistics
Reference: https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-machine-learning-mllib-ipython
Which Azure service should you recommend for the analytical data store so that the business analysts and data scientists can execute ad hoc queries as quickly as possible?
A. Azure Data Lake Storage Gen2
B. Azure Cosmos DB
C. Azure Stream Analytics
D. Azure Synapse Analytics
Suggested Answer: A
There are several differences between a data lake and a data warehouse. Data structure, ideal users, processing methods, and the overall purpose of the data are the key differentiators.
<img src=”https://www.examtopics.com/assets/media/exam-media/03774/0004300001.png” alt=”Reference Image” />
Scenario: Litware employs business analysts who prefer to analyze data by using Microsoft Power BI, and data scientists who prefer analyzing data in Azure
Databricks notebooks.
Note: Azure Synapse Analytics formerly known as Azure SQL Data Warehouse.
Design Azure data storage solutions
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for
CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID.
Proposed Solution: Separate data into customer regions by using horizontal partitioning.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: B
We should use Horizontal Partitioning through Sharding, not divide through regions.
Note: Horizontal Partitioning – Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier. With this approach, the schema is identical on all participating databases. This approach is also called ג€shardingג€. Sharding can be performed and managed using (1) the elastic database tools libraries or
(2) self-sharding. An elastic query is used to query or compile reports across many shards.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
You plan to use Azure SQL Database to support a line of business app.
You need to identify sensitive data that is stored in the database and monitor access to the data.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Configure Data Discovery and Classification.
B. Implement Transparent Data Encryption (TDE).
C. Enable Auditing.
D. Run Vulnerability Assessment.
E. Use Advanced Threat Protection.
Suggested Answer: ACE
A: Data Discovery & Classification is built into Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics. It provides advanced capabilities for discovering, classifying, labeling, and reporting the sensitive data in your databases.
C: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field logs the sensitivity classifications (labels) of the data that was returned by a query.
E: Data Discovery & Classification is part of the Advanced Data Security offering, which is a unified package for advanced Azure SQL security capabilities. You can access and manage Data Discovery & Classification via the central SQL Advanced Data Security section of the Azure portal.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/data-discovery-and-classification-overview
A company stores sensitive information about customers and employees in Azure SQL Database.
You need to ensure that the sensitive data remains encrypted in transit and at rest.
What should you recommend?
HOTSPOT -
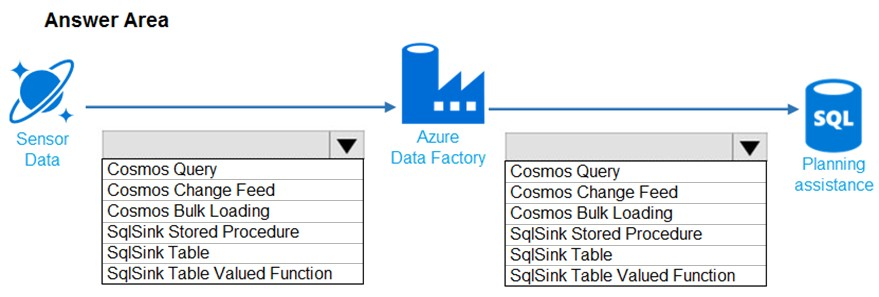
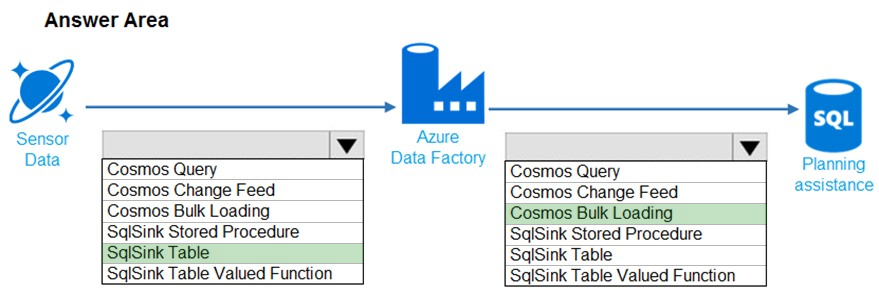
You need to design the data loading pipeline for Planning Assistance.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: SqlSink Table –
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
Box 2: Cosmos Bulk Loading –
Use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
Scenario: Data from the Sensor Data collection will automatically be loaded into the Planning Assistance database once a week by using Azure Data Factory. You must be able to manually trigger the data load process.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination.
You need to ensure that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs.
What should you do?
A. Clone the cluster after it is terminated.
B. Terminate the cluster manually when processing completes.
C. Create an Azure runbook that starts the cluster every 90 days.
You have an on-premises MySQL database that is 800 GB in size.
You need to migrate a MySQL database to Azure Database for MySQL. You must minimize service interruption to live sites or applications that use the database.
What should you recommend?
A. Azure Database Migration Service
B. Dump and restore
C. Import and export
D. MySQL Workbench
Suggested Answer: A
You can perform MySQL migrations to Azure Database for MySQL with minimal downtime by using the newly introduced continuous sync capability for the Azure
Database Migration Service (DMS). This functionality limits the amount of downtime that is incurred by the application.
Reference: https://docs.microsoft.com/en-us/azure/mysql/howto-migrate-online
What should you recommend as a batch processing solution for Health Interface?
A. Azure CycleCloud
B. Azure Stream Analytics
C. Azure Data Factory
D. Azure Databricks
Suggested Answer: B
Scenario: ADatum identifies the following requirements for the Health Interface application:
Support a more scalable batch processing solution in Azure.
Reduce the amount of time it takes to add data from new hospitals to Health Interface.
Data Factory integrates with the Azure Cosmos DB bulk executor library to provide the best performance when you write to Azure Cosmos DB.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you disable a hierarchical namespace, and you use RBAC (role-based access control).
Does this meet the goal?
HOTSPOT -
You have an Azure subscription that contains an Azure Data Lake Storage account. The storage account contains a data lake named DataLake1.
You plan to use an Azure data factory to ingest data from a folder in DataLake1, transform the data, and land the data in another folder.
You need to ensure that the data factory can read and write data from any folder in the DataLake1 file system. The solution must meet the following requirements:
✑ Minimize the risk of unauthorized user access.
✑ Use the principle of least privilege.
✑ Minimize maintenance effort.
How should you configure access to the storage account for the data factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area:
Suggested Answer:
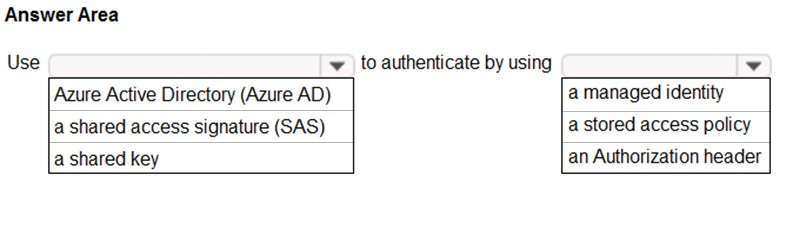
Box 1: Azure Active Directory (Azure AD)
On Azure, managed identities eliminate the need for developers having to manage credentials by providing an identity for the Azure resource in Azure AD and using it to obtain Azure Active Directory (Azure AD) tokens.
Box 2: a managed identity –
A data factory can be associated with a managed identity for Azure resources, which represents this specific data factory. You can directly use this managed identity for Data Lake Storage Gen2 authentication, similar to using your own service principal. It allows this designated factory to access and copy data to or from your Data Lake Storage Gen2.
Note: The Azure Data Lake Storage Gen2 connector supports the following authentication types.
✑ Account key authentication
✑ Service principal authentication
✑ Managed identities for Azure resources authentication
Reference: https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script.
Does this meet the goal?
A. Yes
B. No
Suggested Answer: A
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed.
Reference: https://docs.microsoft.com/en-US/azure/data-factory/transform-data
DRAG DROP -
You are designing a real-time processing solution for maintenance work requests that are received via email. The solution will perform the following actions:
✑ Store all email messages in an archive.
✑ Access weather forecast data by using the Python SDK for Azure Open Datasets.
✑ Identify high priority requests that will be affected by poor weather conditions and store the requests in an Azure SQL database.
The solution must minimize costs.
How should you complete the solution? To answer, drag the appropriate services to the correct locations. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
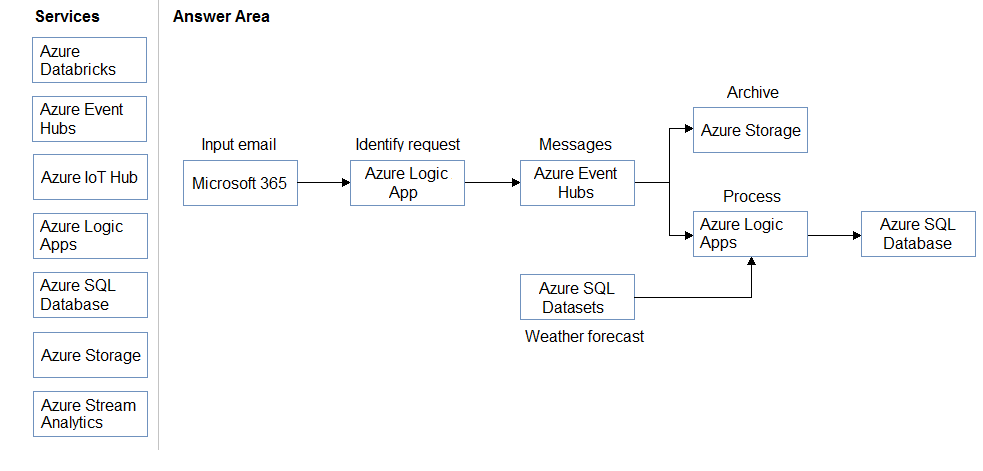
Box 1: Azure Storage –
Azure Event Hubs enables you to automatically capture the streaming data in Event Hubs in an Azure Blob storage or Azure Data Lake Storage Gen 1 or Gen 2 account of your choice, with the added flexibility of specifying a time or size interval. Setting up Capture is fast, there are no administrative costs to run it, and it scales automatically with Event Hubs throughput units. Event Hubs Capture is the easiest way to load streaming data into Azure, and enables you to focus on data processing rather than on data capture.
Box 2: Azure Logic Apps –
You can monitor and manage events sent to Azure Event Hubs from inside a logic app with the Azure Event Hubs connector. That way, you can create logic apps that automate tasks and workflows for checking, sending, and receiving events from your Event Hub.
Reference: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-capture-overview https://docs.microsoft.com/en-us/azure/connectors/connectors-create-api-azure-event-hubs
You are designing a log storage solution that will use Azure Blob storage containers.
CSV log files will be generated by a multi-tenant application. The log files will be generated for each customer at five-minute intervals. There will be more than
5,000 customers. Typically, the customers will query data generated on the day the data was created.
You need to recommend a naming convention for the virtual directories and files. The solution must minimize the time it takes for the customers to query the log files.
What naming convention should you recommend?
A. {year}/{month}/{day}/{hour}/{minute}/{CustomerID}.csv
B. {year}/{month}/{day}/{CustomerID}/{hour}/{minute}.csv
C. {minute}/{hour}/{day}/{month}/{year}/{CustomeriD}.csv
D. {CustomerID}/{year}/{month}/{day}/{hour}/{minute}.csv
Inventory levels must be calculated by subtracting the current day's sales from the previous day's final inventory.
Which two options provide Litware with the ability to quickly calculate the current inventory levels by store and product? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Consume the output of the event hub by using Azure Stream Analytics and aggregate the data by store and product. Output the resulting data directly to Azure Synapse Analytics. Use Transact-SQL to calculate the inventory levels.
B. Output Event Hubs Avro files to Azure Blob storage. Use Transact-SQL to calculate the inventory levels by using PolyBase in Azure Synapse Analytics.
C. Consume the output of the event hub by using Databricks. Use Databricks to calculate the inventory levels and output the data to Azure Synapse Analytics.
D. Consume the output of the event hub by using Azure Stream Analytics and aggregate the data by store and product. Output the resulting data into Databricks. Calculate the inventory levels in Databricks and output the data to Azure Blob storage.
E. Output Event Hubs Avro files to Azure Blob storage. Trigger an Azure Data Factory copy activity to run every 10 minutes to load the data into Azure Synapse Analytics. Use Transact-SQL to aggregate the data by store and product.
Suggested Answer: AE
A: Azure Stream Analytics is a fully managed service providing low-latency, highly available, scalable complex event processing over streaming data in the cloud.
You can use your Azure Synapse Analytics (SQL Data warehouse) database as an output sink for your Stream Analytics jobs.
E: Event Hubs Capture is the easiest way to get data into Azure. Using Azure Data Lake, Azure Data Factory, and Azure HDInsight, you can perform batch processing and other analytics using familiar tools and platforms of your choosing, at any scale you need.
Note: Event Hubs Capture creates files in Avro format.
Captured data is written in Apache Avro format: a compact, fast, binary format that provides rich data structures with inline schema. This format is widely used in the Hadoop ecosystem, Stream Analytics, and Azure Data Factory.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure.
Reference: https://docs.microsoft.com/bs-latn-ba/azure/sql-data-warehouse/sql-data-warehouse-integrate-azure-stream-analytics https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-capture-overview
You are designing an anomaly detection solution for streaming data from an Azure IoT hub. The solution must meet the following requirements:
✑ Send the output to Azure Synapse.
✑ Identify spikes and dips in time series data.
✑ Minimize development and configuration effort
Which should you include in the solution?
You need to design the disaster recovery solution for customer sales data analytics.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provision multiple Azure Databricks workspaces in separate Azure regions.
B. Migrate users, notebooks, and cluster configurations from one workspace to another in the same region.
C. Use zone redundant storage.
D. Migrate users, notebooks, and cluster configurations from one region to another.
E. Use Geo-redundant storage.
F. Provision a second Azure Databricks workspace in the same region.
Suggested Answer: ADE
Scenario: The analytics solution for customer sales data must be available during a regional outage.
To create your own regional disaster recovery topology for databricks, follow these requirements:
1. Provision multiple Azure Databricks workspaces in separate Azure regions
2. Use Geo-redundant storage.
3. Once the secondary region is created, you must migrate the users, user folders, notebooks, cluster configuration, jobs configuration, libraries, storage, init scripts, and reconfigure access control.
Note: Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9’s) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
Design for high availability and disaster recovery
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Analysis Services using Azure Portal
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics Edge application using Microsoft Visual Studio
D. Azure Data Factory instance using Microsoft Visual Studio
You are designing an enterprise data warehouse in Azure Synapse Analytics that will contain a table named Customers. Customers will contain credit card information.
You need to recommend a solution to provide salespeople with the ability to view all the entries in Customers. The solution must prevent all the salespeople from viewing or inferring the credit card information.
What should you include in the recommendation?
A. row-level security
B. data masking
C. column-level security
D. Always Encrypted
Suggested Answer: B
SQL Database dynamic data masking limits sensitive data exposure by masking it to non-privileged users.
The Credit card masking method exposes the last four digits of the designated fields and adds a constant string as a prefix in the form of a credit card.
Example: XXXX-XXXX-XXXX-1234 –
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-dynamic-data-masking-get-started
HOTSPOT -
The following code segment is used to create an Azure Databricks cluster.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Yes –
Box 2: No –
autotermination_minutes: Automatically terminates the cluster after it is inactive for this time in minutes. If not set, this cluster will not be automatically terminated.
If specified, the threshold must be between 10 and 10000 minutes. You can also set this value to 0 to explicitly disable automatic termination.
Box 3: Yes –
References: https://docs.databricks.com/dev-tools/api/latest/clusters.html
HOTSPOT -
You have an Azure Data Lake Storage Gen2 account named account1 that stores logs as shown in the following table.
You do not expect that the logs will be accessed during the retention periods.
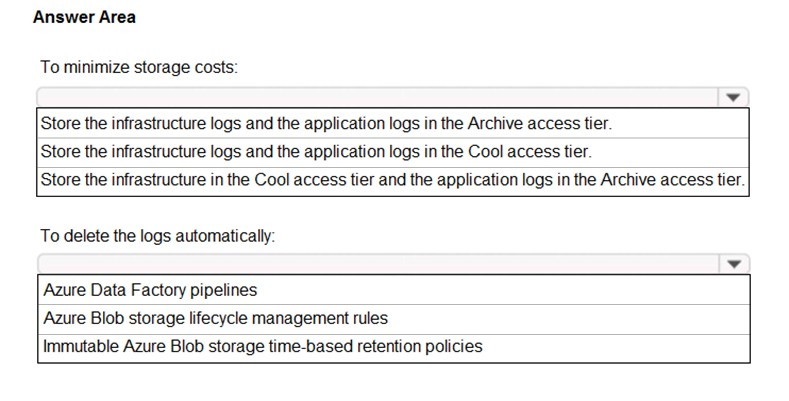
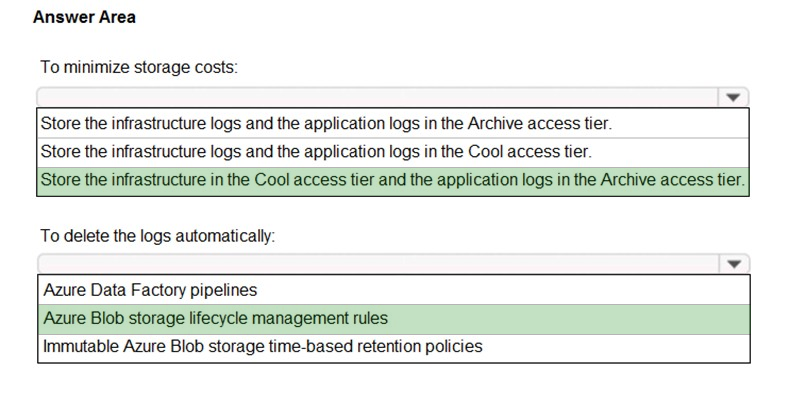
You need to recommend a solution for account1 that meets the following requirements:
✑ Automatically deletes the logs at the end of each retention period
✑ Minimizes storage costs
What should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Store the infrastructure in the Cool access tier and the application logs in the Archive access tier.
Cool – Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.
Box 2: Azure Blob storage lifecycle management rules
Blob storage lifecycle management offers a rich, rule-based policy that you can use to transition your data to the best access tier and to expire data at the end of its lifecycle.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
You need to optimize storage for CONT_SQL3.
What should you recommend?
A. AlwaysOn
B. Transactional processing
C. General
D. Data warehousing
Suggested Answer: B
CONT_SQL3 with the SQL Server role, 100 GB database size, Hyper-VM to be migrated to Azure VM.
The storage should be configured to optimized storage for database OLTP workloads.
Azure SQL Database provides three basic in-memory based capabilities (built into the underlying database engine) that can contribute in a meaningful way to performance improvements:
In-Memory Online Transactional Processing (OLTP)
Clustered columnstore indexes intended primarily for Online Analytical Processing (OLAP) workloads
Nonclustered columnstore indexes geared towards Hybrid Transactional/Analytical Processing (HTAP) workloads
Reference: https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sql-database.html
HOTSPOT -
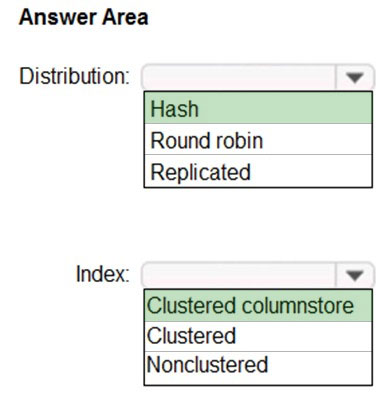
You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytic in a star schema.
You plan to have a fact table for website visits. The table will be approximately 5 GB.
You need to recommend which distribution type and index type to use for the table. The solution must provide the fastest query performance.
What should you recommend? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.
Hot Area:
You need to recommend a storage solution for a sales system that will receive thousands of small files per minute. The files will be in JSON, text, and CSV formats. The files will be processed and transformed before they are loaded into a data warehouse in Azure Synapse Analytics. The files must be stored and secured in folders.
Which storage solution should you recommend?
A. Azure Data Lake Storage Gen2
B. Azure Cosmos DB
C. Azure SQL Database
D. Azure Blob storage
Suggested Answer: A
Azure provides several solutions for working with CSV and JSON files, depending on your needs. The primary landing place for these files is either Azure Storage or Azure Data Lake Store.1
Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Incorrect Answers:
D: Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/scenarios/csv-and-json
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Implement compaction jobs to combine small files into larger files.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data to an Azure SQL database. You consume the data in Power BI by using DirectQuery mode.
Does the solution meet the goal?
You are planning a solution to aggregate streaming data that originates in Apache Kafka and is output to Azure Data Lake Storage Gen2. The developers who will implement the stream processing solution use Java.
Which service should you recommend using to process the streaming data?
HOTSPOT -
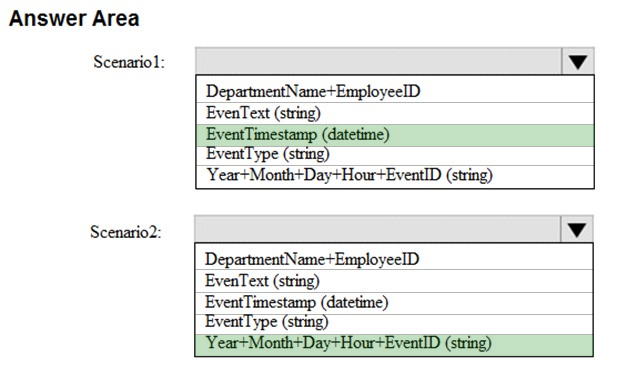
You are designing a solution that will use Azure Table storage. The solution will log records in the following entity.
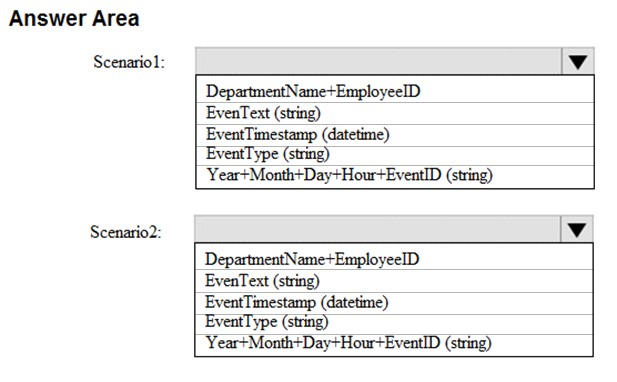
You are evaluating which partition key to use based on the following two scenarios:
✑ Scenario1: Minimize hotspots under heavy write workloads.
✑ Scenario2: Ensure that date lookups are as efficient as possible for read workloads.
Which partition key should you use for each scenario? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you disable a hierarchical namespace, and you use access control lists (ACLs).
Does this meet the goal?
A company is designing a solution that uses Azure Databricks.
The solution must be resilient to regional Azure datacenter outages.
You need to recommend the redundancy type for the solution.
What should you recommend?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you enable a hierarchical namespace, and you use RBAC.
Does this meet the goal?
You need to design the storage for the telemetry capture system.
What storage solution should you use in the design?
A. Azure Synapse Analytics
B. Azure Databricks
C. Azure Cosmos DB
Suggested Answer: C
Azure Cosmos DB is a globally distributed database service. You can associate any number of Azure regions with your Azure Cosmos account and your data is automatically and transparently replicated.
Scenario:
Telemetry Capture –
The telemetry capture system records each time a vehicle passes in front of a sensor. The sensors run on a custom embedded operating system and record the following telemetry data:
✑ Time
✑ Location in latitude and longitude
✑ Speed in kilometers per hour (kmph)
✑ Length of vehicle in meters
You must write all telemetry data to the closest Azure region. The sensors used for the telemetry capture system have a small amount of memory available and so must write data as quickly as possible to avoid losing telemetry data.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/high-availability
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure Synapse Analytics as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if corruption is detected.
Does the solution meet the goal?
You need to recommend a solution that meets the data platform requirements of Health Interface. The solution must minimize redevelopment efforts for the application.
What should you include in the recommendation?
A. Azure Synapse Analytics
B. Azure SQL Database
C. Azure Cosmos DB that uses the SQL API
D. Azure Cosmos DB that uses the Table API
Suggested Answer: C
Scenario: ADatum identifies the following requirements for the Health Interface application:
✑ Reduce the amount of development effort to rewrite existing SQL queries.
✑ Upgrade to a data storage solution that will provide flexible schemas and increased throughput for writing data. Data must be regionally located close to each hospital, and reads must display be the most recent committed version of an item.
✑ Reduce the amount of time it takes to add data from new hospitals to Health Interface.
✑ Support a more scalable batch processing solution in Azure.
You need to design a telemetry data solution that supports the analysis of log files in real time.
Which two Azure services should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Azure Databricks
B. Azure Data Factory
C. Azure Event Hubs
D. Azure Data Lake Storage Gen2
Suggested Answer: AC
You connect a data ingestion system with Azure Databricks to stream data into an Apache Spark cluster in near real-time. You set up data ingestion system using
Azure Event Hubs and then connect it to Azure Databricks to process the messages coming through.
Note: Azure Event Hubs is a highly scalable data streaming platform and event ingestion service, capable of receiving and processing millions of events per second. Event Hubs can process and store events, data, or telemetry produced by distributed software and devices. Data sent to an event hub can be transformed and stored using any real-time analytics provider or batching/storage adapters.
Reference: https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs
You need to design the unauthorized data usage detection system.
What Azure service should you include in the design?
A. Azure Analysis Services
B. Azure Synapse Analytics
C. Azure Databricks
D. Azure Data Factory
Suggested Answer: B
SQL Database and SQL Data Warehouse
SQL threat detection identifies anomalous activities indicating unusual and potentially harmful attempts to access or exploit databases.
Advanced Threat Protection for Azure SQL Database and SQL Data Warehouse detects anomalous activities indicating unusual and potentially harmful attempts to access or exploit databases.
Scenario:
Requirements. Security –
The solution must meet the following security requirements:
✑ Unauthorized usage of data must be detected in real time. Unauthorized usage is determined by looking for unusual usage patterns.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-threat-detection-overview
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server.
You need to set up the database as a subscriber.
What should you recommend?
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier. Workspace1 contains an all-purpose cluster named cluster1.
You need to reduce the time it takes for cluster1 to start and scale up. The solution must minimize costs.
What should you do first?
A. Upgrade workspace1 to the Premium pricing tier.
B. Create a pool in workspace1.
C. Configure a global init script for workspace1.
D. Create a cluster policy in workspace1.
Suggested Answer: B
Databricks Pools increase the productivity of both Data Engineers and Data Analysts. With Pools, Databricks customers eliminate slow cluster start and auto- scaling times. Data Engineers can reduce the time it takes to run short jobs in their data pipeline, thereby providing better SLAs to their downstream teams.
Reference: https://databricks.com/blog/2019/11/11/databricks-pools-speed-up-data-pipelines.html
You are designing an Azure Databricks interactive cluster.
You need to ensure that the cluster meets the following requirements:
✑ Enable auto-termination
✑ Retain cluster configuration indefinitely after cluster termination.
What should you recommend?
A. Start the cluster after it is terminated.
B. Pin the cluster
C. Clone the cluster after it is terminated.
D. Terminate the cluster manually at process completion.
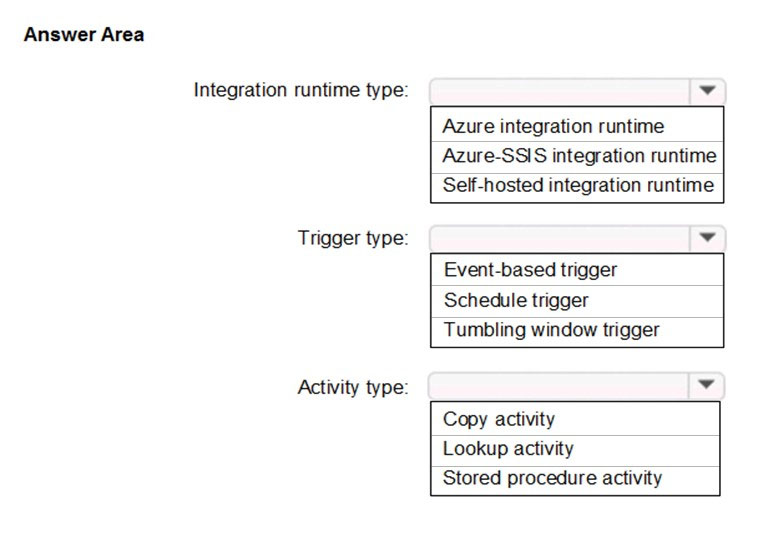
HOTSPOT -
Which Azure Data Factory components should you recommend using together to import the customer data from Salesforce to Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
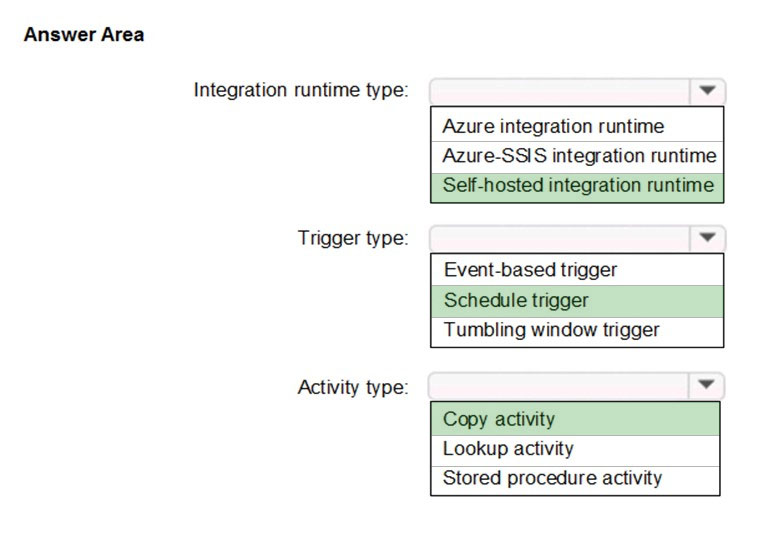
Suggested Answer:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of nunning copy activity between a cloud data stores and a data store in private network.
Box 2: Schedule trigger –
Schedule every 8 hours –
Box 3: Copy activity –
Scenario:
✑ Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
✑ Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data directly to Power BI.
Does the solution meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for
CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID.
Proposed Solution: Separate data into shards by using horizontal partitioning.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Horizontal Partitioning – Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier. With this approach, the schema is identical on all participating databases. This approach is also called ג€shardingג€. Sharding can be performed and managed using (1) the elastic database tools libraries or (2) self- sharding. An elastic query is used to query or compile reports across many shards.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
You are planning a solution that combines log data from multiple systems. The log data will be downloaded from an API and stored in a data store.
You plan to keep a copy of the raw data as well as some transformed versions of the data. You expect that there will be at least 2 TB of log files. The data will be used by data scientists and applications.
You need to recommend a solution to store the data in Azure. The solution must minimize costs.
What storage solution should you recommend?
A. Azure Data Lake Storage Gen2
B. Azure Synapse Analytics
C. Azure SQL Database
D. Azure Cosmos DB
Suggested Answer: A
To land the data in Azure storage, you can move it to Azure Blob storage or Azure Data Lake Store Gen2. In either location, the data should be stored in text files.
PolyBase and the COPY statement can load from either location.
Incorrect Answers:
B: Azure Synapse Analytics, uses distributed query processing architecture that takes advantage of the scalability and flexibility of compute and storage resources. Use Azure Synapse Analytics transform and move the data.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-elt-data-loading
You plan to use an enterprise data warehouse in Azure Synapse Analytics to store the customer data.
You need to recommend a disaster recovery solution for the data warehouse.
What should you include in the recommendation?
You work for a finance company.
You need to design a business network analysis solution that meets the following requirements:
✑ Analyzes the flow of transactions between the Azure environments of the company's various partner organizations
✑ Supports Gremlin (graph) queries
What should you include in the solution?
A. Azure Cosmos DB
B. Azure Synapse
C. Azure Analysis Services
D. Azure Data Lake Storage Gen2
Suggested Answer: A
Gremlin is one of the most popular query languages for exploring and analyzing data modeled as property graphs. There are many graph-database vendors out there that support Gremlin as their query language, in particular Azure Cosmos DB which is one of the world’s first self-managed, geo-distributed, multi-master capable graph databases.
Azure Synapse Link for Azure Cosmos DB is a cloud native hybrid transactional and analytical processing (HTAP) capability that enables you to run near real-time analytics over operational data. Synapse Link creates a tight seamless integration between Azure Cosmos DB and Azure Synapse Analytics.
Reference: https://jayanta-mondal.medium.com/analyzing-and-improving-the-performance-azure-cosmos-db-gremlin-queries-7f68bbbac2c https://docs.microsoft.com/en-us/azure/cosmos-db/synapse-link-use-cases
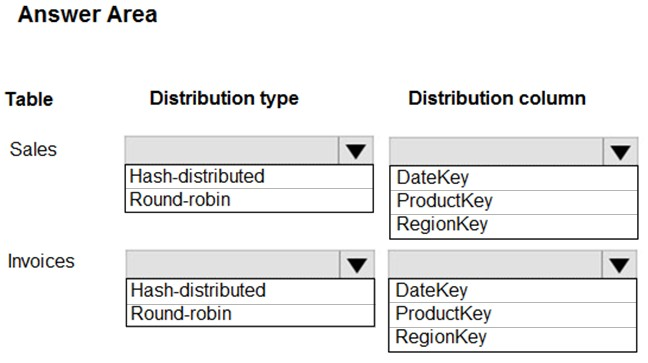
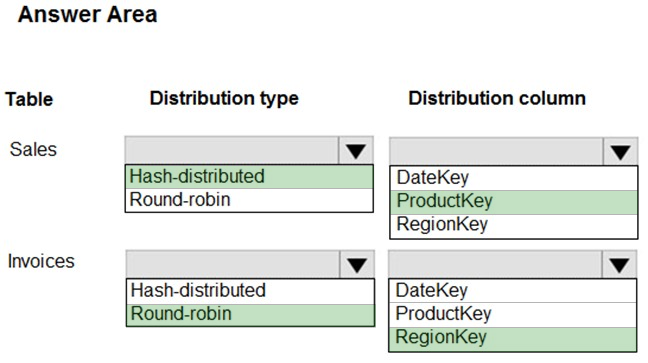
HOTSPOT -
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DataKey, ProductKey, RegionKey.
There are 120 unique product keys and 65 unique region keys.
Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Hash-distributed –
Box 2: ProductKey –
ProductKey is used extensively in joins.
Hash-distributed tables improve query performance on large fact tables.
Box 3: Round-robin –
Box 4: RegionKey –
Round-robin tables are useful for improving loading speed.
Consider using the round-robin distribution for your table in the following scenarios:
✑ When getting started as a simple starting point since it is the default
✑ If there is no obvious joining key
✑ If there is not good candidate column for hash distributing the table
✑ If the table does not share a common join key with other tables
✑ If the join is less significant than other joins in the query
✑ When the table is a temporary staging table
Note: A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are distributed with a hash or round-robin algorithm.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
Free Access Full DP-201 Practice Test Free Questions
If you’re looking for more DP-201 practice test free questions, click here to access the full DP-201 practice test.
We regularly update this page with new practice questions, so be sure to check back frequently.



For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


You do not expect that the logs will be accessed during the retention periods. You need to recommend a solution for account1 that meets the following requirements: ✑ Automatically deletes the logs at the end of each retention period ✑ Minimizes storage costs What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are evaluating which partition key to use based on the following two scenarios: ✑ Scenario1: Minimize hotspots under heavy write workloads. ✑ Scenario2: Ensure that date lookups are as efficient as possible for read workloads. Which partition key should you use for each scenario? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Queries that use the data warehouse take a long time to complete. You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: