DP-201 Practice Exam Free – 50 Questions to Simulate the Real Exam
Are you getting ready for the DP-201 certification? Take your preparation to the next level with our DP-201 Practice Exam Free – a carefully designed set of 50 realistic exam-style questions to help you evaluate your knowledge and boost your confidence.
Using a DP-201 practice exam free is one of the best ways to:
Experience the format and difficulty of the real exam
Identify your strengths and focus on weak areas
Improve your test-taking speed and accuracy
Below, you will find 50 realistic DP-201 practice exam free questions covering key exam topics. Each question reflects the structure and challenge of the actual exam.
HOTSPOT -
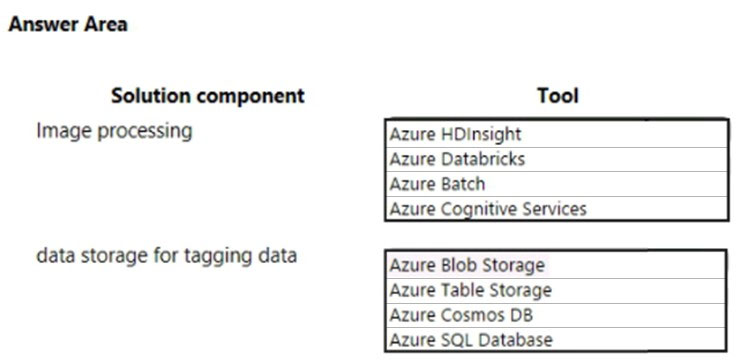
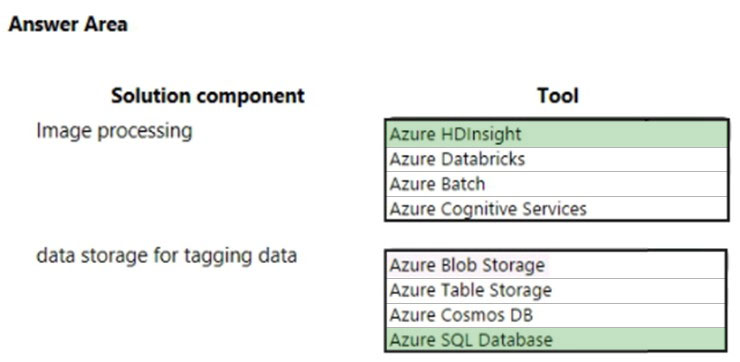
You need to design the image processing and storage solutions.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
From the scenario:
The company identifies the following business requirements:
✑ You must transfer all images and customer data to cloud storage and remove on-premises servers.
✑ You must develop an image object and color tagging solution.
The solution has the following technical requirements:
✑ Image data must be stored in a single data store at minimum cost.
✑ All data must be backed up in case disaster recovery is required.
All cloud data must be encrypted at rest and in transit. The solution must support:
✑ hyper-scale storage of images
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale
DRAG DROP -
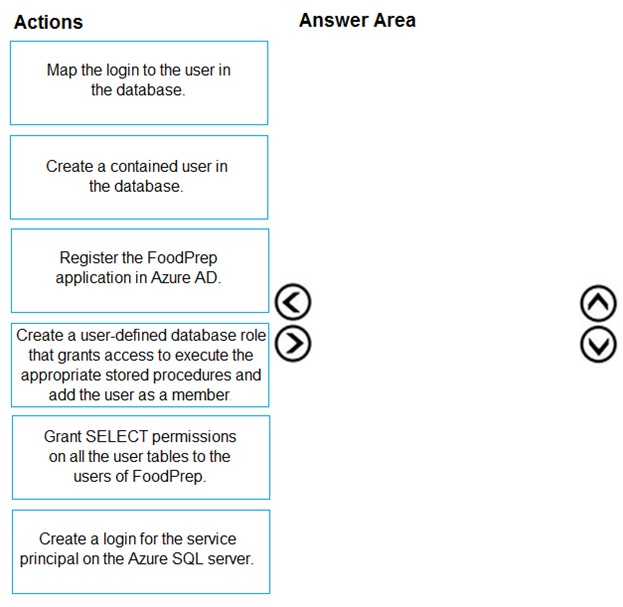
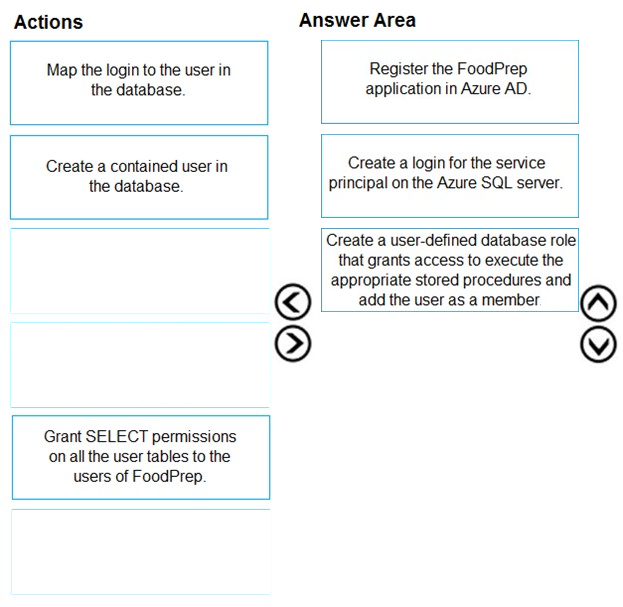
Which three actions should you perform in sequence to allow FoodPrep access to the analytical data store? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Scenario: Litware will build a custom application named FoodPrep to provide store employees with the calculation results of how many prepared food items to produce every four hours.
Step 1: Register the FoodPrep application in Azure AD
You create your Azure AD application and service principal.
Step 2: Create a login for the service principal on the Azure SQL Server
Step 3: Create a user-defined database role that grant access.
To access resources in your subscription, you must assign the application to a role.
You can then assign the required permissions to the service principal.
Reference: https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal
HOTSPOT -
You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytic in a star schema.
You plan to have a fact table for website visits. The table will be approximately 5 GB.
You need to recommend which distribution type and index type to use for the table. The solution must provide the fastest query performance.
What should you recommend? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT -
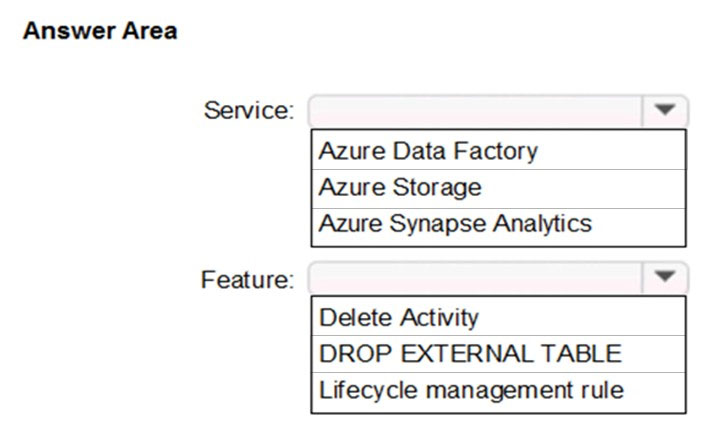
Which Azure service and feature should you recommend using to manage the transient data for Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Scenario: Stage inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
Service: Azure Data Factory –
Clean up files by built-in delete activity in Azure Data Factory (ADF).
ADF built-in delete activity, which can be part of your ETL workflow to deletes undesired files without writing code. You can use ADF to delete folder or files from
Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, File System, FTP Server, sFTP Server, and Amazon S3.
You can delete expired files only rather than deleting all the files in one folder. For example, you may want to only delete the files which were last modified more than 13 days ago.
Feature: Delete Activity –
Reference: https://azure.microsoft.com/sv-se/blog/clean-up-files-by-built-in-delete-activity-in-azure-data-factory/
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
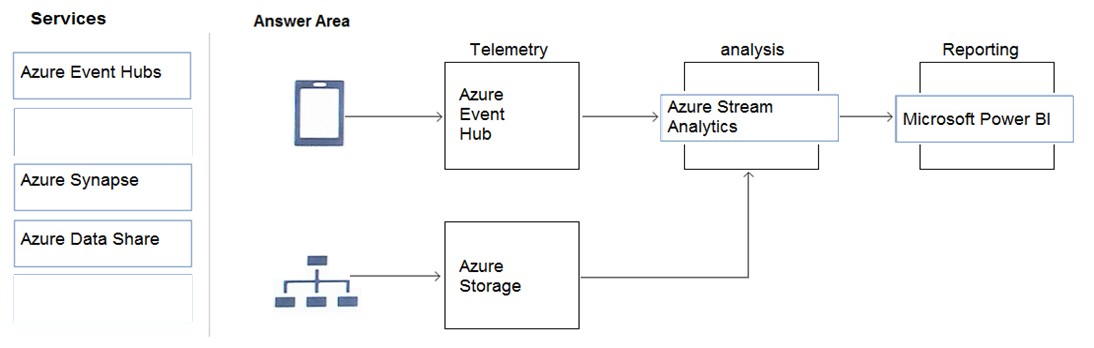
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data to an Azure SQL database. You consume the data in Power BI by using DirectQuery mode.
Does the solution meet the goal?
You need to recommend a security solution to grant anonymous users permission to access the blobs in a specific container only.
What should you include in the recommendation?
A. access keys for the storage account
B. shared access signatures (SAS)
C. Role assignments
D. the public access level for the container
Suggested Answer: D
You can enable anonymous, public read access to a container and its blobs in Azure Blob storage. By doing so, you can grant read-only access to these resources without sharing your account key, and without requiring a shared access signature (SAS).
Public read access is best for scenarios where you want certain blobs to always be available for anonymous read access.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-manage-access-to-resources
What should you do to improve high availability of the real-time data processing solution?
A. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
B. Deploy a High Concurrency Databricks cluster.
C. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
D. Set Data Lake Storage to use geo-redundant storage (GRS).
Suggested Answer: A
Guarantee Stream Analytics job reliability during service updates
Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
Design for high availability and disaster recovery
DRAG DROP -
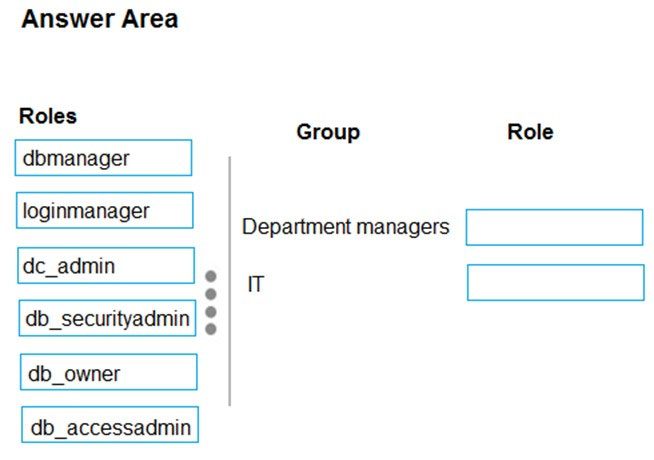
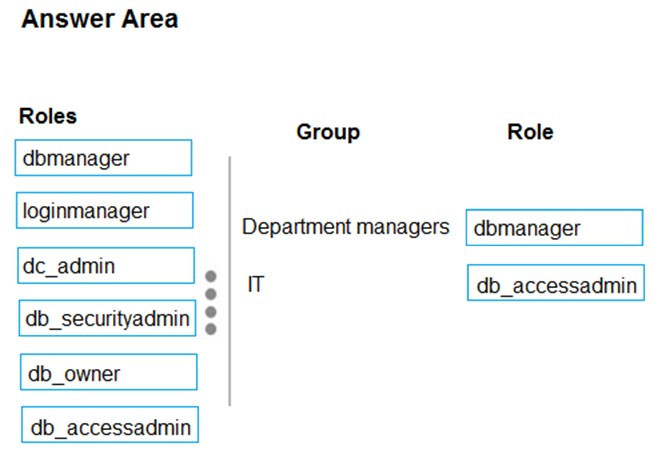
You are designing a data warehouse in Azure Synapse Analytics for a financial services company. Azure Active Directory will be used to authenticate the users.
You need to ensure that the following security requirements are met:
✑ Department managers must be able to create new database.
✑ The IT department must assign users to databases.
✑ Permissions granted must be minimized.
Which role memberships should you recommend? To answer, drag the appropriate roles to the correct groups. Each role may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: dbmanager –
Members of the dbmanager role can create new databases.
Box 2: db_accessadmin –
Members of the db_accessadmin fixed database role can add or remove access to the database for Windows logins, Windows groups, and SQL Server logins.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-manage-logins
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Data Factory instance using Azure PowerShell
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics cloud job using Azure PowerShell
D. Azure Data Factory instance using Microsoft Visual Studio
Suggested Answer: C
Stream Analytics is a cost-effective event processing engine that helps uncover real-time insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and powershell scripting that execute basic Stream Analytics tasks.
Note: Visual Studio 2019 and Visual Studio 2017 also support Stream Analytics Tools.
Reference: https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaming-analytics-data-production-and-workflow-services-to-azure/
You have an Azure subscription that contains an Azure virtual machine and an Azure Storage account. The virtual machine will access the storage account.
You are planning the security design for the storage account.
You need to ensure that only the virtual machine can access the storage account.
Which two actions should you include in the design? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Select Allow trusted Microsoft services to access this storage account.
B. Select Allow read access to storage logging from any network.
C. Enable a virtual network service endpoint.
D. Set the Allow access from setting to Selected networks.
Suggested Answer: AC
C: Virtual Network (VNet) service endpoint provides secure and direct connectivity to Azure services over an optimized route over the Azure backbone network.
Endpoints allow you to secure your critical Azure service resources to only your virtual networks. Service Endpoints enables private IP addresses in the VNet to reach the endpoint of an Azure service without needing a public IP address on the VNet.
A: You must have Allow trusted Microsoft services to access this storage account turned on under the Azure Storage account Firewalls and Virtual networks settings menu.
Incorrect Answers:
D: Virtual Network (VNet) service endpoint policies allow you to filter egress virtual network traffic to Azure Storage accounts over service endpoint, and allow data exfiltration to only specific Azure Storage accounts. Endpoint policies provide granular access control for virtual network traffic to Azure Storage when connecting over service endpoint.
Reference: https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-service-endpoints-overview
You are evaluating data storage solutions to support a new application.
You need to recommend a data storage solution that represents data by using nodes and relationships in graph structures.
Which data storage solution should you recommend?
HOTSPOT -
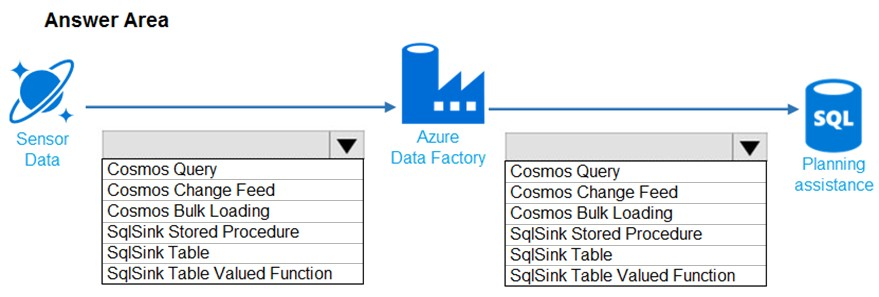
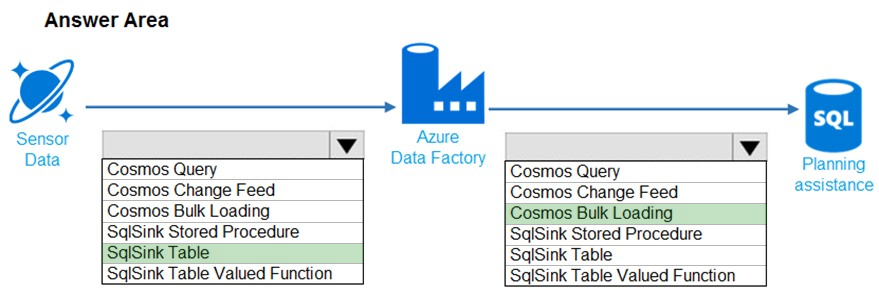
You need to design the data loading pipeline for Planning Assistance.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: SqlSink Table –
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
Box 2: Cosmos Bulk Loading –
Use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
Scenario: Data from the Sensor Data collection will automatically be loaded into the Planning Assistance database once a week by using Azure Data Factory. You must be able to manually trigger the data load process.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
You need to recommend an Azure Cosmos DB solution that meets the following requirements:
✑ All data that was NOT modified during the last 30 days must be purged automatically.
✑ The solution must NOT affect ongoing user requests.
What should you recommend using to purge the data?
A. an Azure Cosmos DB stored procedure executed by an Azure logic app
B. an Azure Cosmos DB REST API Delete Document operation called by an Azure function
C. Time To Live (TTL) setting in Azure Cosmos DB
D. an Azure Cosmos DB change feed queried by an Azure function
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Implement compaction jobs to combine small files into larger files.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
You are designing an Azure Databricks cluster that runs user-defined local processes.
You need to recommend a cluster configuration that meets the following requirements:
✑ Minimize query latency.
✑ Reduce overall costs without compromising other requirements.
✑ Maximize the number of users that can run queries on the cluster at the same time.
Which cluster type should you recommend?
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are larger than 250MB.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
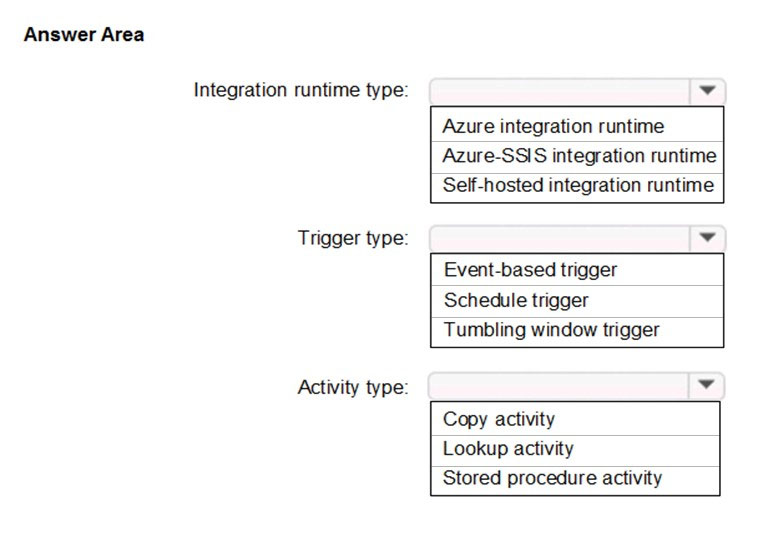
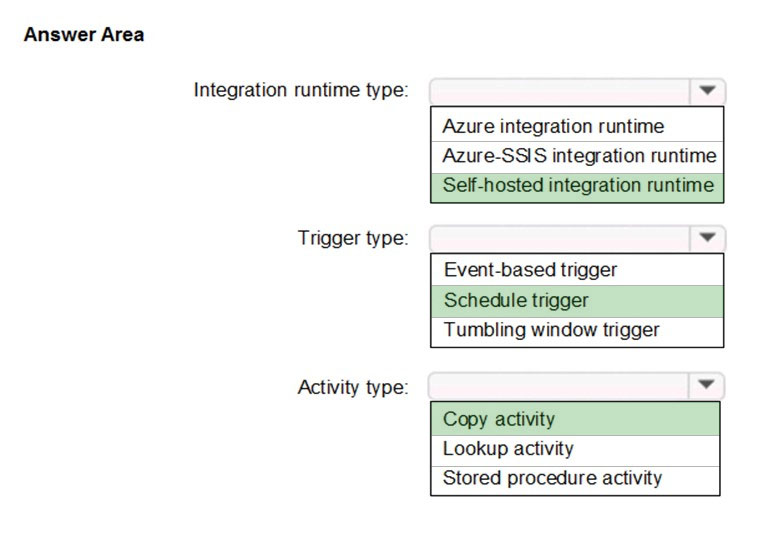
HOTSPOT -
Which Azure Data Factory components should you recommend using together to import the customer data from Salesforce to Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of nunning copy activity between a cloud data stores and a data store in private network.
Box 2: Schedule trigger –
Schedule every 8 hours –
Box 3: Copy activity –
Scenario:
✑ Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
✑ Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
HOTSPOT -
You manage an on-premises server named Server1 that has a database named Database1. The company purchases a new application that can access data from
Azure SQL Database.
You recommend a solution to migrate Database1 to an Azure SQL Database instance.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
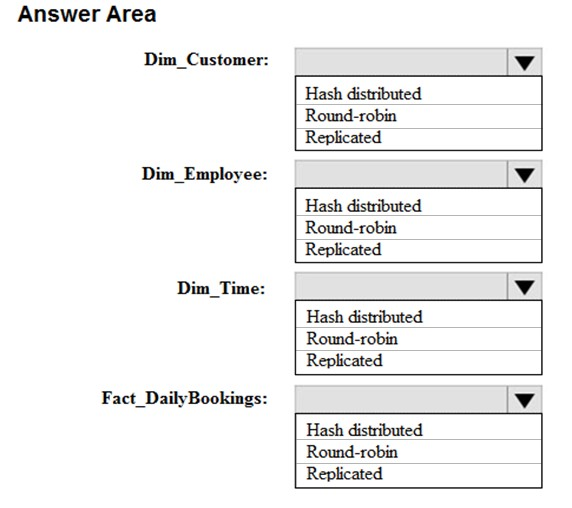
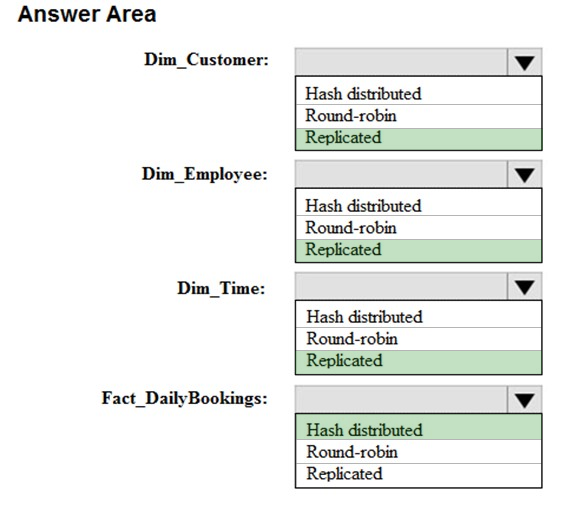
HOTSPOT -
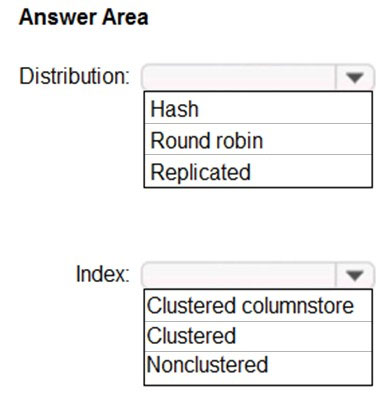
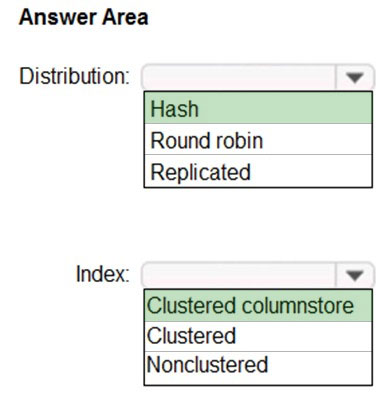
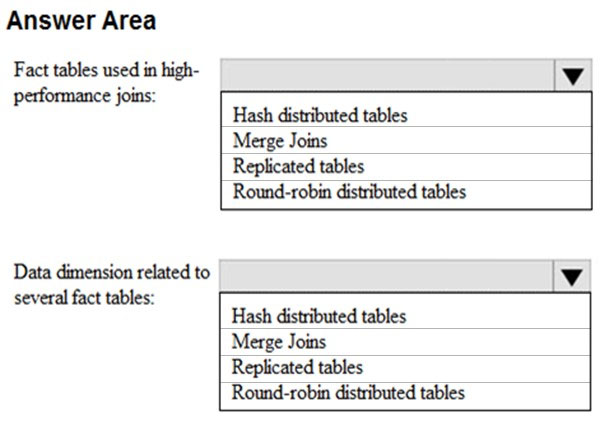
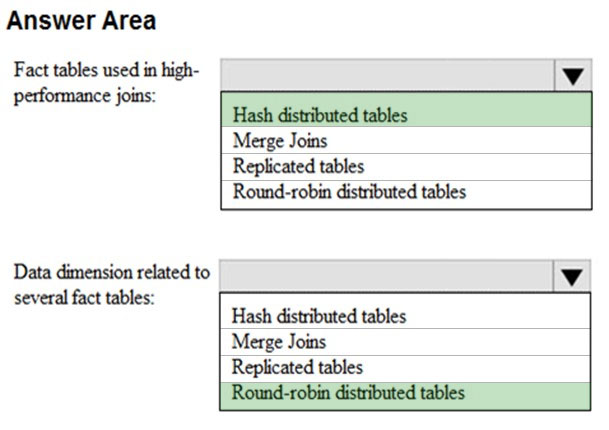
You have a data model that you plan to implement in a data warehouse in Azure Synapse Analytics as shown in the following exhibit.
All the dimension tables will be less than 2 GB after compression, and the fact table will be approximately 6 TB.
Which type of table should you use for each table? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Data Factory instance using Azure Portal
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics cloud job using Azure Portal
D. Azure Data Factory instance using Azure Portal
Suggested Answer: C
The Stream Analytics query language allows to perform CEP (Complex Event Processing) by offering a wide array of functions for analyzing streaming data. This query language supports simple data manipulation, aggregation and analytics functions, geospatial functions, pattern matching and anomaly detection. You can edit queries in the portal or using our development tools, and test them using sample data that is extracted from a live stream.
Note: Stream Analytics is a cost-effective event processing engine that helps uncover real-time insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and powershell scripting that execute basic Stream Analytics tasks.
Reference: https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaming-analytics-data-production-and-workflow-services-to-azure/ https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-introduction
DRAG DROP -
Your company has a custom human resources (HR) app named App1 that is deployed to mobile devices.
You are designing a solution that will use real-time metrics to indicate how employees use App1. The solution must meet the following requirements:
✑ Use hierarchy data exported monthly from the company's HR enterprise application.
✑ Process approximately 1 GB of telemetry data per day.
✑ Minimize costs.
You need to recommend which Azure services to use to meet the requirements.
Which two services should you recommend? To answer, drag the appropriate services to the correct targets. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
HOTSPOT -
You are designing a solution to store flat files.
You need to recommend a storage solution that meets the following requirements:
✑ Supports automatically moving files that have a modified date that is older than one year to an archive in the data store
✑ Minimizes costs
A higher latency is acceptable for the archived files.
Which storage location and archiving method should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Storage location: Azure Blob Storage
Archiving method: A lifecycle management policy
Azure Blob storage lifecycle management offers a rich, rule-based policy for GPv2 and Blob storage accounts. Use the policy to transition your data to the appropriate access tiers or expire at the end of the data’s lifecycle.
The lifecycle management policy lets you:
✑ Transition blobs to a cooler storage tier (hot to cool, hot to archive, or cool to archive) to optimize for performance and cost
✑ Delete blobs at the end of their lifecycles
✑ Define rules to be run once per day at the storage account level
Apply rules to containers or a subset of blobs
Reference: alt=”Reference Image” />
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-lifecycle-management-concepts
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you enable a hierarchical namespace, and you use access control lists (ACLs).
Does this meet the goal?
You need to recommend a solution to quickly identify all the columns in Health Review that contain sensitive health data.
What should you include in the recommendation?
You need to design a backup solution for the processed customer data.
What should you include in the design?
A. AzCopy
B. AdlCopy
C. Geo-Redundancy
D. Geo-Replication
Suggested Answer: C
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9’s) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
DRAG DROP -
You need to design the image processing solution to meet the optimization requirements for image tag data.
What should you configure? To answer, drag the appropriate setting to the correct drop targets.
Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Tagging data must be uploaded to the cloud from the New York office location.
Tagging data must be replicated to regions that are geographically close to company office locations.
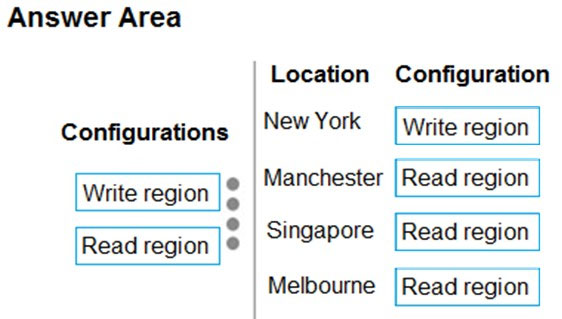
You design data engineering solutions for a company that has locations around the world. You plan to deploy a large set of data to Azure Cosmos DB.
The data must be accessible from all company locations.
You need to recommend a strategy for deploying the data that minimizes latency for data read operations and minimizes costs.
What should you recommend?
A. Use a single Azure Cosmos DB account. Enable multi-region writes.
B. Use a single Azure Cosmos DB account Configure data replication.
C. Use multiple Azure Cosmos DB accounts. For each account, configure the location to the closest Azure datacenter.
D. Use a single Azure Cosmos DB account. Enable geo-redundancy.
E. Use multiple Azure Cosmos DB accounts. Enable multi-region writes.
Suggested Answer: A
With Azure Cosmos DB, you can add or remove the regions associated with your account at any time.
Multi-region accounts configured with multiple-write regions will be highly available for both writes and reads. Regional failovers are instantaneous and don’t require any changes from the application.
Reference: alt=”Reference Image” />
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/high-availability
HOTSPOT -
You are planning the deployment of two separate Azure Cosmos DB databases named db1 and db2.
You need to recommend a deployment strategy that meets the following requirements:
✑ Costs for both databases must be minimized.
✑ Db1 must meet an availability SLA of 99.99% for both reads and writes.
✑ Db2 must meet an availability SLA of 99.99% for writes and 99.999% for reads.
Which deployment strategy should you recommend for each database? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You need to design the disaster recovery solution for customer sales data analytics.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provision multiple Azure Databricks workspaces in separate Azure regions.
B. Migrate users, notebooks, and cluster configurations from one workspace to another in the same region.
C. Use zone redundant storage.
D. Migrate users, notebooks, and cluster configurations from one region to another.
E. Use Geo-redundant storage.
F. Provision a second Azure Databricks workspace in the same region.
Suggested Answer: ADE
Scenario: The analytics solution for customer sales data must be available during a regional outage.
To create your own regional disaster recovery topology for databricks, follow these requirements:
1. Provision multiple Azure Databricks workspaces in separate Azure regions
2. Use Geo-redundant storage.
3. Once the secondary region is created, you must migrate the users, user folders, notebooks, cluster configuration, jobs configuration, libraries, storage, init scripts, and reconfigure access control.
Note: Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9’s) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
Design for high availability and disaster recovery
You are designing an Azure Synapse solution that will provide a query interface for the data stored in an Azure Storage account. The storage account is only accessible from a virtual network.
You need to recommend an authentication mechanism to ensure that the solution can access the source data.
What should you recommend?
A. a shared key
B. an Azure Active Directory (Azure AD) service principal
You need to recommend a solution for storing the image tagging data.
What should you recommend?
A. Azure File Storage
B. Azure Cosmos DB
C. Azure Blob Storage
D. Azure SQL Database
E. Azure Synapse Analytics
Suggested Answer: C
Image data must be stored in a single data store at minimum cost.
Note: Azure Blob storage is Microsoft’s object storage solution for the cloud. Blob storage is optimized for storing massive amounts of unstructured data.
Unstructured data is data that does not adhere to a particular data model or definition, such as text or binary data.
Blob storage is designed for:
✑ Serving images or documents directly to a browser.
✑ Storing files for distributed access.
✑ Streaming video and audio.
✑ Writing to log files.
✑ Storing data for backup and restore, disaster recovery, and archiving.
✑ Storing data for analysis by an on-premises or Azure-hosted service.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
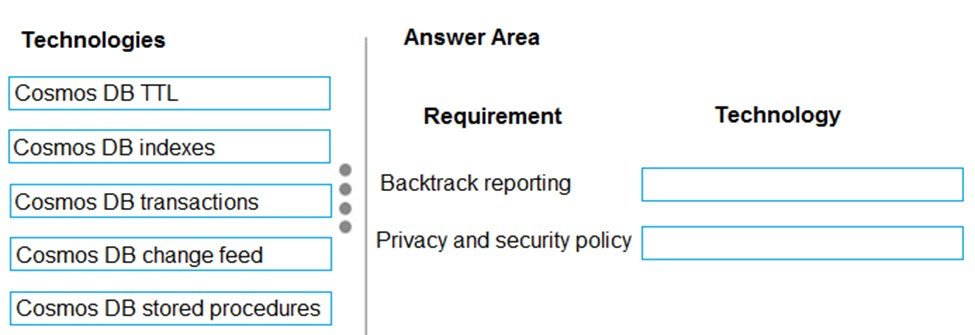
DRAG DROP -
You need to ensure that performance requirements for Backtrack reports are met.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: Cosmos DB indexes –
The report for Backtrack must execute as quickly as possible.
You can override the default indexing policy on an Azure Cosmos container, this could be useful if you want to tune the indexing precision to improve the query performance or to reduce the consumed storage.
Box 2: Cosmos DB TTL –
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection. Users must be able to filter vehicle data in the following ways:
✑ vehicles on a specific road
✑ vehicles driving above the speed limit
Note: With Time to Live or TTL, Azure Cosmos DB provides the ability to delete items automatically from a container after a certain time period. By default, you can set time to live at the container level and override the value on a per-item basis. After you set the TTL at a container or at an item level, Azure Cosmos DB will automatically remove these items after the time period, since the time they were last modified.
Incorrect Answers:
Cosmos DB stored procedures: Stored procedures are best suited for operations that are write heavy. When deciding where to use stored procedures, optimize around encapsulating the maximum amount of writes possible. Generally speaking, stored procedures are not the most efficient means for doing large numbers of read operations so using stored procedures to batch large numbers of reads to return to the client will not yield the desired benefit.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/index-policy https://docs.microsoft.com/en-us/azure/cosmos-db/time-to-live
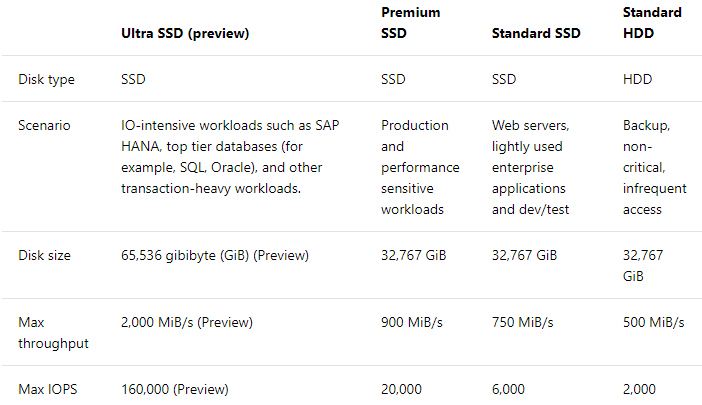
You need to design a solution to meet the SQL Server storage requirements for CONT_SQL3.
Which type of disk should you recommend?
A. Standard SSD Managed Disk
B. Premium SSD Managed Disk
C. Ultra SSD Managed Disk
Suggested Answer: C
CONT_SQL3 requires an initial scale of 35000 IOPS.
Ultra SSD Managed Disk Offerings
The following table provides a comparison of ultra solid-state-drives (SSD) (preview), premium SSD, standard SSD, and standard hard disk drives (HDD) for managed disks to help you decide what to use.
Reference: alt=”Reference Image” />
The following table provides a comparison of ultra solid-state-drives (SSD) (preview), premium SSD, standard SSD, and standard hard disk drives (HDD) for managed disks to help you decide what to use.
<img src=”https://www.examtopics.com/assets/media/exam-media/03774/0002200001.png” alt=”Reference Image” />
Reference: https://docs.microsoft.com/en-us/azure/virtual-machines/windows/disks-types
You need to recommend an Azure SQL Database pricing tier for Planning Assistance.
Which pricing tier should you recommend?
A. Business critical Azure SQL Database single database
B. General purpose Azure SQL Database Managed Instance
C. Business critical Azure SQL Database Managed Instance
D. General purpose Azure SQL Database single database
Suggested Answer: B
Azure resource costs must be minimized where possible.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
The SLA for Planning Assistance is 70 percent, and multiday outages are permitted.
You are designing a storage solution to store CSV files.
You need to grant a data scientist access to read all the files in a single container of an Azure Storage account. The solution must use the principle of least privilege and provide the highest level of security.
What are two possible ways to achieve the goal? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provide an access key.
B. Assign the Storage Blob Data Reader role at the container level.
C. Assign the Reader role to the storage account.
D. Provide an account shared access signature (SAS).
E. Provide a user delegation shared access signature (SAS).
Suggested Answer: BE
B: When an Azure role is assigned to an Azure AD security principal, Azure grants access to those resources for that security principal. Access can be scoped to the level of the subscription, the resource group, the storage account, or an individual container or queue.
The built-in Data Reader roles provide read permissions for the data in a container or queue.
Note: Permissions are scoped to the specified resource.
For example, if you assign the Storage Blob Data Reader role to user Mary at the level of a container named sample-container, then Mary is granted read access to all of the blobs in that container.
E: A user delegation SAS is secured with Azure Active Directory (Azure AD) credentials and also by the permissions specified for the SAS. A user delegation SAS applies to Blob storage only.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-auth-aad-rbac-portal https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview
You need to recommend a storage solution for a sales system that will receive thousands of small files per minute. The files will be in JSON, text, and CSV formats. The files will be processed and transformed before they are loaded into a data warehouse in Azure Synapse Analytics. The files must be stored and secured in folders.
Which storage solution should you recommend?
A. Azure Data Lake Storage Gen2
B. Azure Cosmos DB
C. Azure SQL Database
D. Azure Blob storage
Suggested Answer: A
Azure provides several solutions for working with CSV and JSON files, depending on your needs. The primary landing place for these files is either Azure Storage or Azure Data Lake Store.1
Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Incorrect Answers:
D: Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/scenarios/csv-and-json
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server.
You need to set up the database as a subscriber.
What should you recommend?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure Synapse Analytics as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if corruption is detected.
Does the solution meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you enable a hierarchical namespace, and you use RBAC.
Does this meet the goal?
You are designing an anomaly detection solution for streaming data from an Azure IoT hub. The solution must meet the following requirements:
✑ Send the output to Azure Synapse.
✑ Identify spikes and dips in time series data.
✑ Minimize development and configuration effort
Which should you include in the solution?
DRAG DROP -
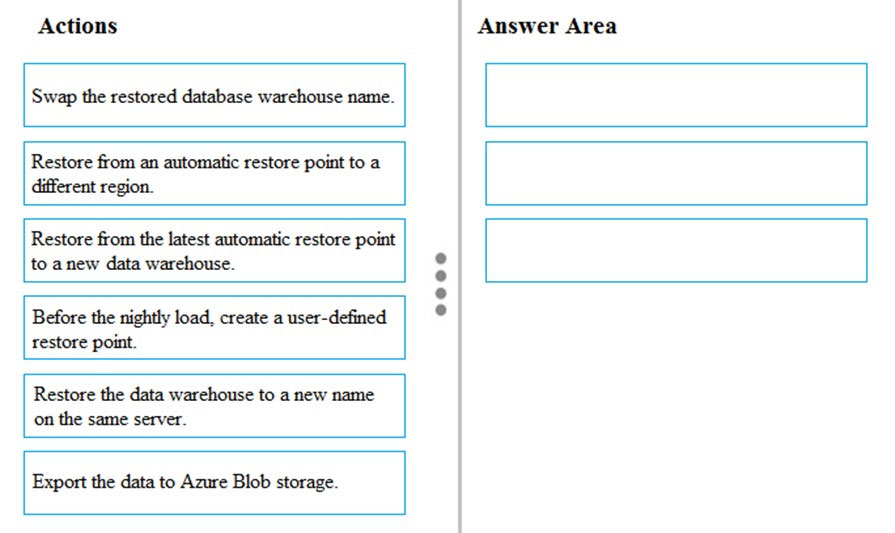
You discover that the highest chance of corruption or bad data occurs during nightly inventory loads.
You need to ensure that you can quickly restore the data to its state before the nightly load and avoid missing any streaming data.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Scenario: Daily inventory data comes from a Microsoft SQL server located on a private network.
Step 1: Before the nightly load, create a user-defined restore point
SQL Data Warehouse performs a geo-backup once per day to a paired data center. The RPO for a geo-restore is 24 hours. If you require a shorter RPO for geo- backups, you can create a user-defined restore point and restore from the newly created restore point to a new data warehouse in a different region.
Step 2: Restore the data warehouse to a new name on the same server.
Step 3: Swap the restored database warehouse name.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
You need to recommend an Azure SQL Database service tier.
What should you recommend?
A. Business Critical
B. General Purpose
C. Premium
D. Standard
E. Basic
Suggested Answer: C
The data engineers must set the SQL Data Warehouse compute resources to consume 300 DWUs.
Note: There are three architectural models that are used in Azure SQL Database:
✑ General Purpose/Standard
✑ Business Critical/Premium
✑ Hyperscale
Incorrect Answers:
A: Business Critical service tier is designed for the applications that require low-latency responses from the underlying SSD storage (1-2 ms in average), fast recovery if the underlying infrastructure fails, or need to off-load reports, analytics, and read-only queries to the free of charge readable secondary replica of the primary database.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-business-critical
HOTSPOT -
You need to design the storage for the Health Insights data platform.
Which types of tables should you include in the design? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Hash-distributed tables –
The new Health Insights application must be built on a massively parallel processing (MPP) architecture that will support the high performance of joins on large fact tables.
Hash-distributed tables improve query performance on large fact tables.
Box 2: Round-robin distributed tables
A round-robin distributed table distributes table rows evenly across all distributions. The assignment of rows to distributions is random.
Scenario:
ADatum identifies the following requirements for the Health Insights application:
✑ The new Health Insights application must be built on a massively parallel processing (MPP) architecture that will support the high performance of joins on large fact tables.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
You have an Azure Storage account.
You plan to copy one million image files to the storage account.
You plan to share the files with an external partner organization. The partner organization will analyze the files during the next year.
You need to recommend an external access solution for the storage account. The solution must meet the following requirements:
✑ Ensure that only the partner organization can access the storage account.
Ensure that access of the partner organization is removed automatically after 365 days.
What should you include in the recommendation?
A. shared keys
B. Azure Blob storage lifecycle management policies
C. Azure policies
D. shared access signature (SAS)
Suggested Answer: D
A shared access signature (SAS) is a URI that grants restricted access rights to Azure Storage resources. You can provide a shared access signature to clients who should not be trusted with your storage account key but to whom you wish to delegate access to certain storage account resources. By distributing a shared access signature URI to these clients, you can grant them access to a resource for a specified period of time, with a specified set of permissions.
Reference: https://docs.microsoft.com/en-us/rest/api/storageservices/delegate-access-with-shared-access-signature
You have an Azure Data Lake Storage Gen2 account named adls2 that is protected by a virtual network.
You are designing a SQL pool in Azure Synapse that will use adls2 as a source.
What should you use to authenticate to adls2?
DRAG DROP -
You need to design the encryption strategy for the tagging data and customer data.
What should you recommend? To answer, drag the appropriate setting to the correct drop targets. Each source may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
You are developing a solution that performs real-time analysis of IoT data in the cloud.
The solution must remain available during Azure service updates.
You need to recommend a solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Deploy an Azure Stream Analytics job to two separate regions that are not in a pair.
B. Deploy an Azure Stream Analytics job to each region in a paired region.
C. Monitor jobs in both regions for failure.
D. Monitor jobs in the primary region for failure.
E. Deploy an Azure Stream Analytics job to one region in a paired region.
Suggested Answer: BC
Stream Analytics guarantees jobs in paired regions are updated in separate batches. As a result there is a sufficient time gap between the updates to identify potential breaking bugs and remediate them.
Customers are advised to deploy identical jobs to both paired regions.
In addition to Stream Analytics internal monitoring capabilities, customers are also advised to monitor the jobs as if both are production jobs. If a break is identified to be a result of the Stream Analytics service update, escalate appropriately and fail over any downstream consumers to the healthy job output. Escalation to support will prevent the paired region from being affected by the new deployment and maintain the integrity of the paired jobs.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
You have an Azure Data Lake Storage account that has a virtual network service endpoint configured.
You plan to use Azure Data Factory to extract data from the Data Lake Storage account. The data will then be loaded to a data warehouse in Azure Synapse
Analytics by using PolyBase.
Which authentication method should you use to access Data Lake Storage?
You have a large amount of sensor data stored in an Azure Data Lake Storage Gen2 account. The files are in the Parquet file format.
New sensor data will be published to Azure Event Hubs.
You need to recommend a solution to add the new sensor data to the existing sensor data in real-time. The solution must support the interactive querying of the entire dataset.
Which type of server should you include in the recommendation?
A. Azure SQL Database
B. Azure Cosmos DB
C. Azure Stream Analytics
D. Azure Databricks
Suggested Answer: C
Azure Stream Analytics is a fully managed PaaS offering that enables real-time analytics and complex event processing on fast moving data streams.
By outputting data in parquet format into a blob store or a data lake, you can take advantage of Azure Stream Analytics to power large scale streaming extract, transfer, and load (ETL), to run batch processing, to train machine learning algorithms, or to run interactive queries on your historical data.
Reference: https://azure.microsoft.com/en-us/blog/new-capabilities-in-stream-analytics-reduce-development-time-for-big-data-apps/
Free Access Full DP-201 Practice Exam Free
Looking for additional practice? Click here to access a full set of DP-201 practice exam free questions and continue building your skills across all exam domains.
Our question sets are updated regularly to ensure they stay aligned with the latest exam objectives—so be sure to visit often!





All the dimension tables will be less than 2 GB after compression, and the fact table will be approximately 6 TB. Which type of table should you use for each table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
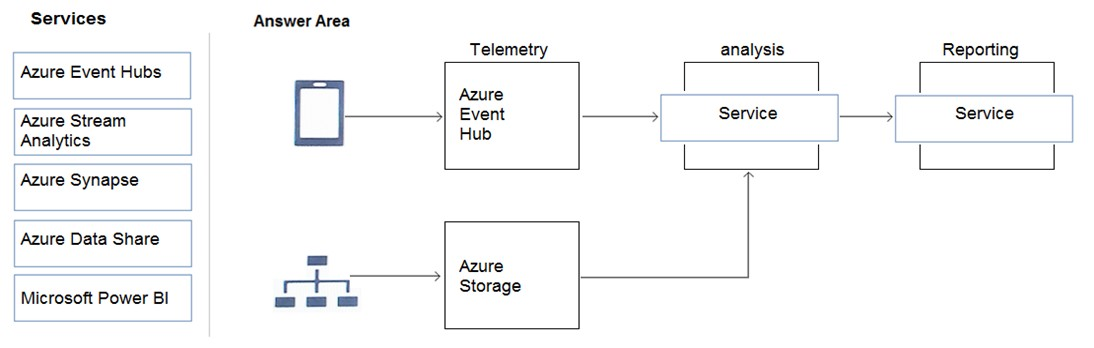











What should you include in the recommendation?

