DP-201 Mock Test Free – 50 Realistic Questions to Prepare with Confidence.
Getting ready for your DP-201 certification exam? Start your preparation the smart way with our DP-201 Mock Test Free – a carefully crafted set of 50 realistic, exam-style questions to help you practice effectively and boost your confidence.
Using a mock test free for DP-201 exam is one of the best ways to:
Familiarize yourself with the actual exam format and question style
Identify areas where you need more review
Strengthen your time management and test-taking strategy
Below, you will find 50 free questions from our DP-201 Mock Test Free resource. These questions are structured to reflect the real exam’s difficulty and content areas, helping you assess your readiness accurately.
You are designing an application that will have an Azure virtual machine. The virtual machine will access an Azure SQL database. The database will not be accessible from the Internet.
You need to recommend a solution to provide the required level of access to the database.
What should you include in the recommendation?
A. Deploy an On-premises data gateway.
B. Add a virtual network to the Azure SQL server that hosts the database.
C. Add an application gateway to the virtual network that contains the Azure virtual machine.
D. Add a virtual network gateway to the virtual network that contains the Azure virtual machine.
Suggested Answer: B
When you create an Azure virtual machine (VM), you must create a virtual network (VNet) or use an existing VNet. You also need to decide how your VMs are intended to be accessed on the VNet.
Incorrect Answers:
C: Azure Application Gateway is a web traffic load balancer that enables you to manage traffic to your web applications.
D: A VPN gateway is a specific type of virtual network gateway that is used to send encrypted traffic between an Azure virtual network and an on-premises location over the public Internet.
Reference: https://docs.microsoft.com/en-us/azure/virtual-machines/network-overview
You are developing an application that uses Azure Data Lake Storage Gen 2.
You need to recommend a solution to grant permissions to a specific application for a limited time period.
What should you include in the recommendation?
A. Azure Active Directory (Azure AD) identities
B. shared access signatures (SAS)
C. account keys
D. role assignments
Suggested Answer: B
A shared access signature (SAS) is a URI that grants restricted access rights to Azure Storage resources. You can provide a shared access signature to clients who should not be trusted with your storage account key but to whom you wish to delegate access to certain storage account resources. By distributing a shared access signature URI to these clients, you can grant them access to a resource for a specified period of time, with a specified set of permissions.
Reference: https://docs.microsoft.com/en-us/rest/api/storageservices/delegate-access-with-shared-access-signature
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are smaller than 250MB.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: B
Ensure that files stored are larger, not smaller than 250MB.
You can have a separate compaction job that combines these files into larger ones.
Note: The file POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure Synapse Analytics as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure Synapse Analytics and set retention to 10 days.
Does the solution meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you disable a hierarchical namespace, and you use RBAC (role-based access control).
Does this meet the goal?
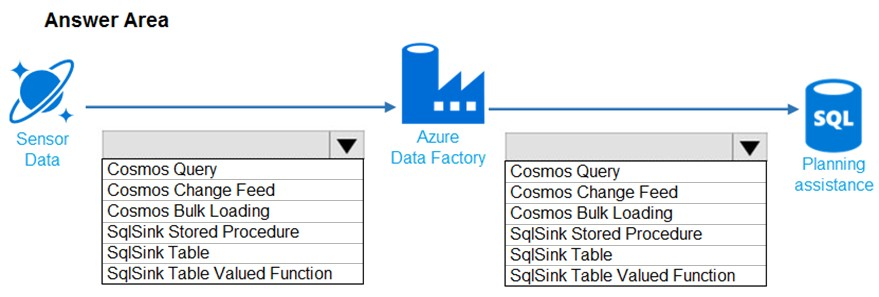
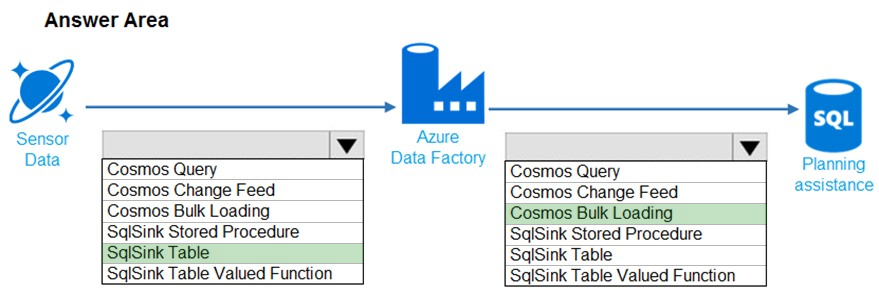
HOTSPOT -
You need to design the data loading pipeline for Planning Assistance.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: SqlSink Table –
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
Box 2: Cosmos Bulk Loading –
Use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
Scenario: Data from the Sensor Data collection will automatically be loaded into the Planning Assistance database once a week by using Azure Data Factory. You must be able to manually trigger the data load process.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
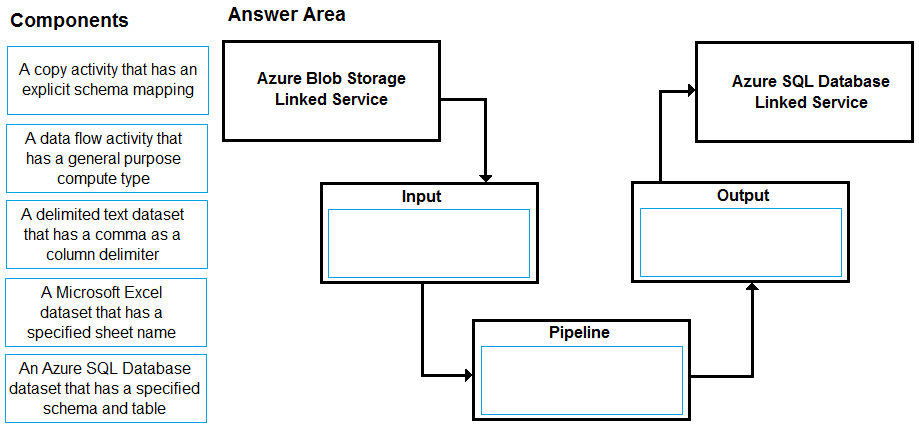
DRAG DROP -
You have a CSV file in Azure Blob storage. The file does NOT have a header row.
You need to use Azure Data Factory to copy the file to an Azure SQL database. The solution must minimize how long it takes to copy the file.
How should you configure the copy process? To answer, drag the appropriate components to the correct locations. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
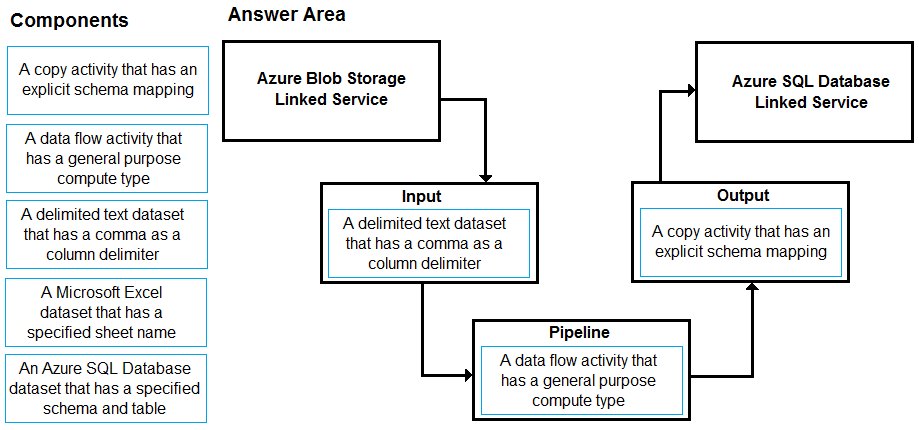
Suggested Answer:
Input: A delimited text dataset that has a comma a column delimiter columnDelimiter: The character(s) used to separate columns in a file.
The default value is comma ,. When the column delimiter is defined as empty string, which means no delimiter, the whole line is taken as a single column.
Pipeline: A data flow activity that has a general purpose compute type
When you’re transforming data in mapping data flows, you can read and write files from Azure Blob storage.
Output: A copy activity that has an explicit schema mapping
Use Copy Activity in Azure Data Factory to copy data from and to Azure SQL Database, and use Data Flow to transform data in Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/format-delimited-text https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-database
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure Synapse Analytics as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if corruption is detected.
Does the solution meet the goal?
A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream
Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU).
You need to optimize performance for the Azure Stream Analytics job.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Implement event ordering
B. Scale the SU count for the job up
C. Implement Azure Stream Analytics user-defined functions (UDF)
D. Scale the SU count for the job down
E. Implement query parallelization by partitioning the data output
F. Implement query parallelization by partitioning the data output
You are developing a solution that performs real-time analysis of IoT data in the cloud.
The solution must remain available during Azure service updates.
You need to recommend a solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Deploy an Azure Stream Analytics job to two separate regions that are not in a pair.
B. Deploy an Azure Stream Analytics job to each region in a paired region.
C. Monitor jobs in both regions for failure.
D. Monitor jobs in the primary region for failure.
E. Deploy an Azure Stream Analytics job to one region in a paired region.
Suggested Answer: BC
Stream Analytics guarantees jobs in paired regions are updated in separate batches. As a result there is a sufficient time gap between the updates to identify potential breaking bugs and remediate them.
Customers are advised to deploy identical jobs to both paired regions.
In addition to Stream Analytics internal monitoring capabilities, customers are also advised to monitor the jobs as if both are production jobs. If a break is identified to be a result of the Stream Analytics service update, escalate appropriately and fail over any downstream consumers to the healthy job output. Escalation to support will prevent the paired region from being affected by the new deployment and maintain the integrity of the paired jobs.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data directly to Power BI.
Does the solution meet the goal?
You need to recommend a solution for storing the image tagging data.
What should you recommend?
A. Azure File Storage
B. Azure Cosmos DB
C. Azure Blob Storage
D. Azure SQL Database
E. Azure Synapse Analytics
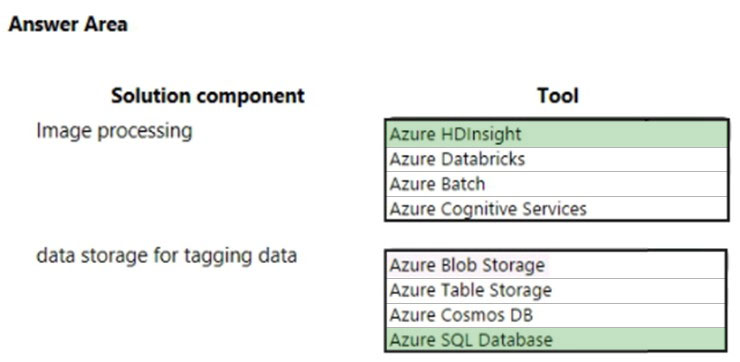
Suggested Answer: C
Image data must be stored in a single data store at minimum cost.
Note: Azure Blob storage is Microsoft’s object storage solution for the cloud. Blob storage is optimized for storing massive amounts of unstructured data.
Unstructured data is data that does not adhere to a particular data model or definition, such as text or binary data.
Blob storage is designed for:
✑ Serving images or documents directly to a browser.
✑ Storing files for distributed access.
✑ Streaming video and audio.
✑ Writing to log files.
✑ Storing data for backup and restore, disaster recovery, and archiving.
✑ Storing data for analysis by an on-premises or Azure-hosted service.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data to an Azure SQL database. You consume the data in Power BI by using DirectQuery mode.
Does the solution meet the goal?
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of the 250 web servers generates approximately
10megabytes (MB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Combine the daily log files for all servers into one file
B. Increase the value of the mapreduce.map.memory parameter
C. Move the log files into folders so that each day’s logs are in their own folder
D. Increase the number of worker nodes
E. Increase the value of the hive.tez.container.size parameter
Suggested Answer: AC
A: Typically, analytics engines such as HDInsight and Azure Data Lake Analytics has a per-five overhead. If you store your data as many small files, this can negatively affect performance. In general, organize your data into larger sized files for better performance (256MB to 100GB in size). Some engines and applications might have trouble efficiently processing files that are greater than 100GB in size.
C: For Hive workloads, partition pruning of time-series data can help some queries read only a subset of the data which improves performance.
Those pipelines that ingest time-series data, often place their files with a very structured naming for files and folders. Below is a very common example we see for data is structured by date:
DataSetYYYYMMDDdatafile_YYYY_MM_DD.tsv
Notice that the datetime information appears both as folders and in the filename.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
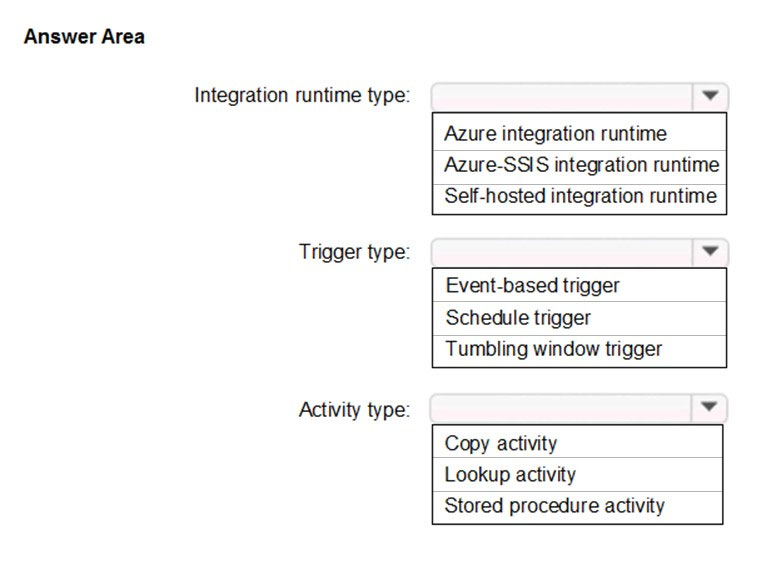
HOTSPOT -
Which Azure Data Factory components should you recommend using together to import the daily inventory data from SQL to Azure Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
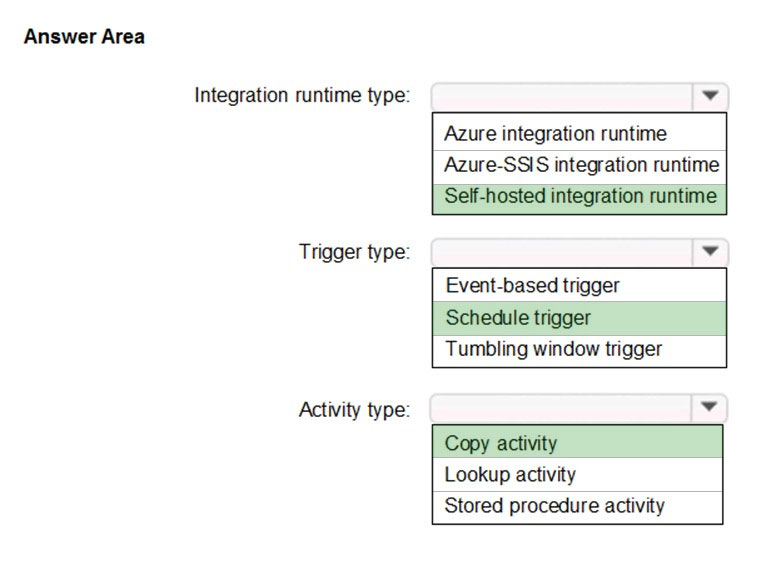
Suggested Answer:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of nunning copy activity between a cloud data stores and a data store in private network.
Scenario: Daily inventory data comes from a Microsoft SQL server located on a private network.
Box 2: Schedule trigger –
Daily schedule –
Box 3: Copy activity –
Scenario:
Stage inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data
Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
A company is designing a solution that uses Azure Databricks.
The solution must be resilient to regional Azure datacenter outages.
You need to recommend the redundancy type for the solution.
What should you recommend?
You need to design the storage for the visual monitoring system.
Which storage solution should you recommend?
A. Azure Blob storage
B. Azure Table storage
C. Azure SQL database
D. Azure Cosmos DB
Suggested Answer: A
Azure Blobs: A massively scalable object store for text and binary data.
Azure Cognitive Search supports fuzzy search. You can use Azure Cognitive Search to index blobs.
Scenario:
✑ The visual monitoring system is a network of approximately 1,000 cameras placed near highways that capture images of vehicle traffic every 2 seconds. The cameras record high resolution images. Each image is approximately 3 MB in size.
✑ The solution must allow for searches of vehicle images by license plate to support law enforcement investigations. Searches must be able to be performed using a query language and must support fuzzy searches to compensate for license plate detection errors.
Incorrect Answers:
B: Azure Tables: A NoSQL store for schemaless storage of structured data.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/search/search-howto-indexing-azure-blob-storage#how-azure-cognitive-search-indexes-blobs
You are designing an audit strategy for an Azure SQL Database environment.
You need to recommend a solution to provide real-time notifications for potential security breaches. The solution must minimize development effort.
Which destination should you include in the recommendation?
A. Azure Blob storage
B. Azure Synapse Analytics
C. Azure Event Hubs
D. Azure Log Analytics
Suggested Answer: D
Auditing for Azure SQL Database and SQL Data Warehouse tracks database events and writes them to an audit log in your Azure storage account, Log Analytics workspace or Event Hubs.
Alerts in Azure Monitor can identify important information in your Log Analytics repository. They are created by alert rules that automatically run log searches at regular intervals, and if results of the log search match particular criteria, then an alert record is created and it can be configured to perform an automated response.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auditing https://docs.microsoft.com/en-us/azure/azure-monitor/learn/tutorial-response
HOTSPOT -
You need to design the authentication and authorization methods for sensors.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
Sensors must have permission only to add items to the SensorData collection
Box 1: Resource Token –
Resource tokens provide access to the application resources within a Cosmos DB database.
Enable clients to read, write, and delete resources in the Cosmos DB account according to the permissions they’ve been granted.
Box 2: Cosmos DB user –
You can use a resource token (by creating Cosmos DB users and permissions) when you want to provide access to resources in your Cosmos DB account to a client that cannot be trusted with the master key.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/secure-access-to-data
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script.
Does this meet the goal?
A. Yes
B. No
Suggested Answer: A
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed.
Reference: https://docs.microsoft.com/en-US/azure/data-factory/transform-data
You need to recommend a security solution for containers in Azure Blob storage. The solution must ensure that only read permissions are granted to a specific user for a specific container.
What should you include in the recommendation?
A. shared access signatures (SAS)
B. an RBAC role in Azure Active Directory (Azure AD)
C. public read access for blobs only
D. access keys
Suggested Answer: A
You can delegate access to read, write, and delete operations on blob containers, tables, queues, and file shares that are not permitted with a service SAS.
Note: A shared access signature (SAS) provides secure delegated access to resources in your storage account without compromising the security of your data.
With a SAS, you have granular control over how a client can access your data. You can control what resources the client may access, what permissions they have on those resources, and how long the SAS is valid, among other parameters.
Incorrect Answers:
C: You can enable anonymous, public read access to a container and its blobs in Azure Blob storage. By doing so, you can grant read-only access to these resources without sharing your account key, and without requiring a shared access signature (SAS).
Public read access is best for scenarios where you want certain blobs to always be available for anonymous read access.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview
HOTSPOT -
You are planning the deployment of two separate Azure Cosmos DB databases named db1 and db2.
You need to recommend a deployment strategy that meets the following requirements:
✑ Costs for both databases must be minimized.
✑ Db1 must meet an availability SLA of 99.99% for both reads and writes.
✑ Db2 must meet an availability SLA of 99.99% for writes and 99.999% for reads.
Which deployment strategy should you recommend for each database? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT -
You manage an on-premises server named Server1 that has a database named Database1. The company purchases a new application that can access data from
Azure SQL Database.
You recommend a solution to migrate Database1 to an Azure SQL Database instance.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
HOTSPOT -
The following code segment is used to create an Azure Databricks cluster.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Yes –
Box 2: No –
autotermination_minutes: Automatically terminates the cluster after it is inactive for this time in minutes. If not set, this cluster will not be automatically terminated.
If specified, the threshold must be between 10 and 10000 minutes. You can also set this value to 0 to explicitly disable automatic termination.
Box 3: Yes –
References: https://docs.databricks.com/dev-tools/api/latest/clusters.html
HOTSPOT -
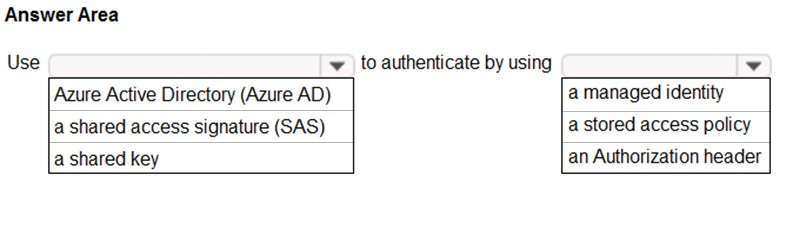
You have an Azure subscription that contains an Azure Data Lake Storage account. The storage account contains a data lake named DataLake1.
You plan to use an Azure data factory to ingest data from a folder in DataLake1, transform the data, and land the data in another folder.
You need to ensure that the data factory can read and write data from any folder in the DataLake1 file system. The solution must meet the following requirements:
✑ Minimize the risk of unauthorized user access.
✑ Use the principle of least privilege.
✑ Minimize maintenance effort.
How should you configure access to the storage account for the data factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area:
Suggested Answer:
Box 1: Azure Active Directory (Azure AD)
On Azure, managed identities eliminate the need for developers having to manage credentials by providing an identity for the Azure resource in Azure AD and using it to obtain Azure Active Directory (Azure AD) tokens.
Box 2: a managed identity –
A data factory can be associated with a managed identity for Azure resources, which represents this specific data factory. You can directly use this managed identity for Data Lake Storage Gen2 authentication, similar to using your own service principal. It allows this designated factory to access and copy data to or from your Data Lake Storage Gen2.
Note: The Azure Data Lake Storage Gen2 connector supports the following authentication types.
✑ Account key authentication
✑ Service principal authentication
✑ Managed identities for Azure resources authentication
Reference: https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
HOTSPOT -
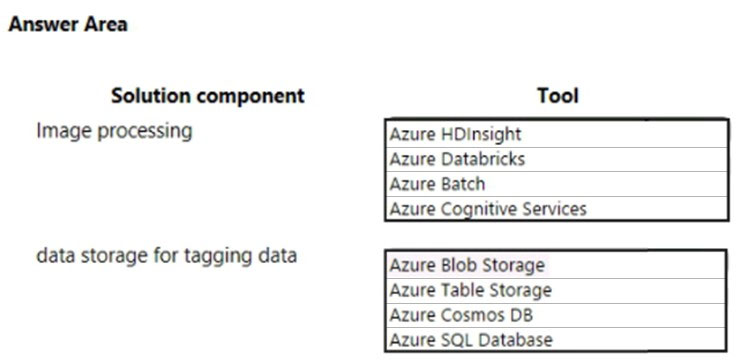
You need to design the image processing and storage solutions.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
From the scenario:
The company identifies the following business requirements:
✑ You must transfer all images and customer data to cloud storage and remove on-premises servers.
✑ You must develop an image object and color tagging solution.
The solution has the following technical requirements:
✑ Image data must be stored in a single data store at minimum cost.
✑ All data must be backed up in case disaster recovery is required.
All cloud data must be encrypted at rest and in transit. The solution must support:
✑ hyper-scale storage of images
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale
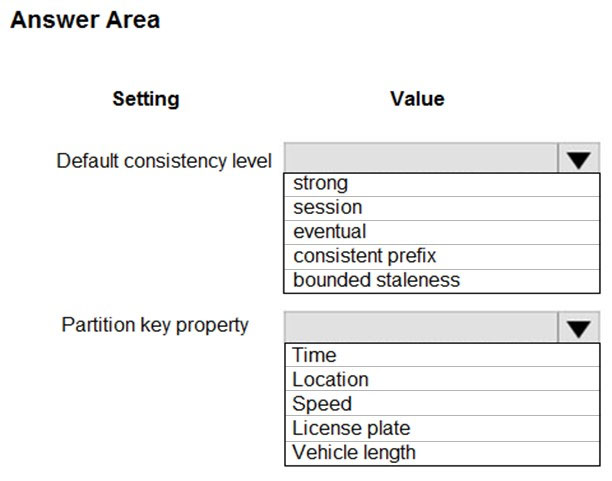
HOTSPOT -
You need to design the SensorData collection.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Eventual –
Traffic data insertion rate must be maximized.
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
Box 2: License plate –
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
HOTSPOT -
You design data engineering solutions for a company.
You must integrate on-premises SQL Server data into an Azure solution that performs Extract-Transform-Load (ETL) operations have the following requirements:
✑ Develop a pipeline that can integrate data and run notebooks.
✑ Develop notebooks to transform the data.
✑ Load the data into a massively parallel processing database for later analysis.
You need to recommend a solution.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into department folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you enable a hierarchical namespace, and you use access control lists (ACLs).
Does this meet the goal?
You need to design the unauthorized data usage detection system.
What Azure service should you include in the design?
A. Azure Analysis Services
B. Azure Synapse Analytics
C. Azure Databricks
D. Azure Data Factory
Suggested Answer: B
SQL Database and SQL Data Warehouse
SQL threat detection identifies anomalous activities indicating unusual and potentially harmful attempts to access or exploit databases.
Advanced Threat Protection for Azure SQL Database and SQL Data Warehouse detects anomalous activities indicating unusual and potentially harmful attempts to access or exploit databases.
Scenario:
Requirements. Security –
The solution must meet the following security requirements:
✑ Unauthorized usage of data must be detected in real time. Unauthorized usage is determined by looking for unusual usage patterns.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-threat-detection-overview
HOTSPOT -
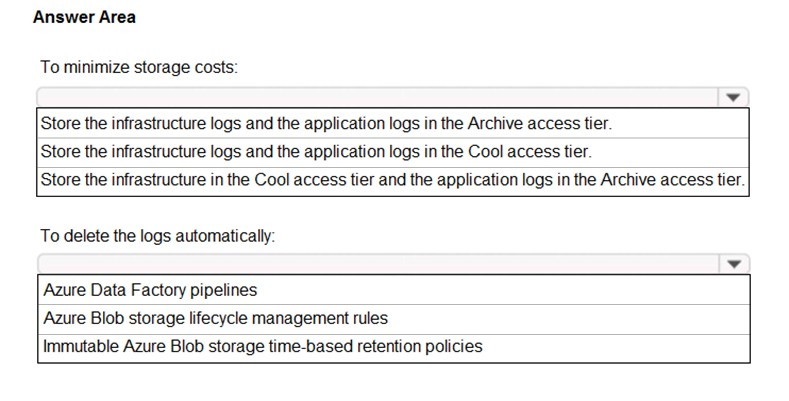
You have an Azure Data Lake Storage Gen2 account named account1 that stores logs as shown in the following table.
You do not expect that the logs will be accessed during the retention periods.
You need to recommend a solution for account1 that meets the following requirements:
✑ Automatically deletes the logs at the end of each retention period
✑ Minimizes storage costs
What should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
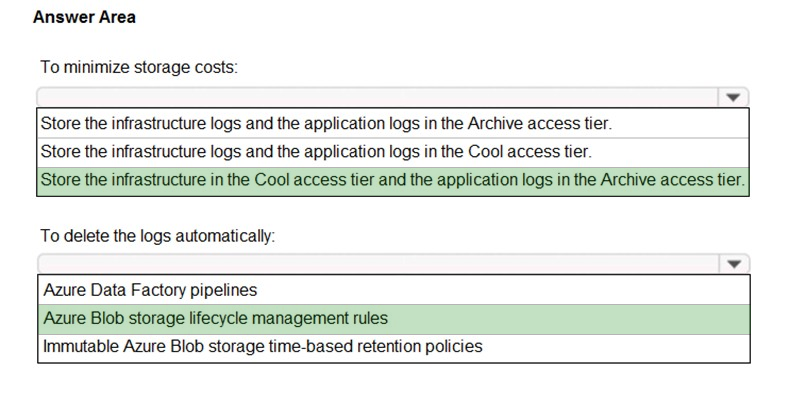
Suggested Answer:
Box 1: Store the infrastructure in the Cool access tier and the application logs in the Archive access tier.
Cool – Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.
Box 2: Azure Blob storage lifecycle management rules
Blob storage lifecycle management offers a rich, rule-based policy that you can use to transition your data to the best access tier and to expire data at the end of its lifecycle.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
You are designing a real-time stream solution based on Azure Functions. The solution will process data uploaded to Azure Blob Storage.
The solution requirements are as follows:
✑ Support up to 1 million blobs.
✑ Scaling must occur automatically.
✑ Costs must be minimized.
What should you recommend?
A. Deploy the Azure Function in an App Service plan and use a Blob trigger.
B. Deploy the Azure Function in a Consumption plan and use an Event Grid trigger.
C. Deploy the Azure Function in a Consumption plan and use a Blob trigger.
D. Deploy the Azure Function in an App Service plan and use an Event Grid trigger.
Suggested Answer: C
Create a function, with the help of a blob trigger template, which is triggered when files are uploaded to or updated in Azure Blob storage.
You use a consumption plan, which is a hosting plan that defines how resources are allocated to your function app. In the default Consumption Plan, resources are added dynamically as required by your functions. In this serverless hosting, you only pay for the time your functions run. When you run in an App Service plan, you must manage the scaling of your function app.
Reference: https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-storage-blob-triggered-function
What should you do to improve high availability of the real-time data processing solution?
A. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
B. Deploy a High Concurrency Databricks cluster.
C. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
D. Set Data Lake Storage to use geo-redundant storage (GRS).
Suggested Answer: A
Guarantee Stream Analytics job reliability during service updates
Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
Design for high availability and disaster recovery
You design data engineering solutions for a company that has locations around the world. You plan to deploy a large set of data to Azure Cosmos DB.
The data must be accessible from all company locations.
You need to recommend a strategy for deploying the data that minimizes latency for data read operations and minimizes costs.
What should you recommend?
A. Use a single Azure Cosmos DB account. Enable multi-region writes.
B. Use a single Azure Cosmos DB account Configure data replication.
C. Use multiple Azure Cosmos DB accounts. For each account, configure the location to the closest Azure datacenter.
D. Use a single Azure Cosmos DB account. Enable geo-redundancy.
E. Use multiple Azure Cosmos DB accounts. Enable multi-region writes.
Suggested Answer: A
With Azure Cosmos DB, you can add or remove the regions associated with your account at any time.
Multi-region accounts configured with multiple-write regions will be highly available for both writes and reads. Regional failovers are instantaneous and don’t require any changes from the application.
Reference: alt=”Reference Image” />
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/high-availability
You have an Azure Data Lake Storage Gen2 account named adls2 that is protected by a virtual network.
You are designing a SQL pool in Azure Synapse that will use adls2 as a source.
What should you use to authenticate to adls2?
You store data in a data warehouse in Azure Synapse Analytics.
You need to design a solution to ensure that the data warehouse and the most current data is available within one hour of a datacenter failure.
Which three actions should you include in the design? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Each day, restore the data warehouse from a geo-redundant backup to an available Azure region.
B. If a failure occurs, update the connection strings to point to the recovered data warehouse.
C. If a failure occurs, modify the Azure Firewall rules of the data warehouse.
D. Each day, create Azure Firewall rules that allow access to the restored data warehouse.
E. Each day, restore the data warehouse from a user-defined restore point to an available Azure region.
Suggested Answer: BDE
E: You can create a user-defined restore point and restore from the newly created restore point to a new data warehouse in a different region.
Note: A data warehouse snapshot creates a restore point you can leverage to recover or copy your data warehouse to a previous state.
A data warehouse restore is a new data warehouse that is created from a restore point of an existing or deleted data warehouse. On average within the same region, restore rates typically take around 20 minutes.
Incorrect Answers:
A: SQL Data Warehouse performs a geo-backup once per day to a paired data center. The RPO for a geo-restore is 24 hours. You can restore the geo-backup to a server in any other region where SQL Data Warehouse is supported. A geo-backup ensures you can restore data warehouse in case you cannot access the restore points in your primary region.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
You have a line-of-business (LOB) app that reads files from and writes files to Azure Blob storage in an Azure Storage account.
You need to recommend changes to the storage account to meet the following requirements:
Provide the highest possible availability.
Minimize potential data loss.
Which three changes should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. From the app, query the LastSyncTime of the storage account.
B. From the storage account, enable soft deletes.
C. From the storage account, enable read-access geo-redundancy storage (RA-GRS).
D. From the app, add retry logic to the storage account interactions.
E. From the storage account, enable a time-based retention policy.
Suggested Answer: BCE
Soft delete protects blob data from being accidentally or erroneously modified or deleted. When soft delete is enabled for a storage account, blobs, blob versions
(preview), and snapshots in that storage account may be recovered after they are deleted, within a retention period that you specify.
Geo-redundant storage (with GRS or GZRS) replicates your data to another physical location in the secondary region to protect against regional outages.
However, that data is available to be read only if the customer or Microsoft initiates a failover from the primary to secondary region. When you enable read access to the secondary region, your data is available to be read if the primary region becomes unavailable. For read access to the secondary region, enable read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-GZRS).
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/soft-delete-overview https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy#read-access-to-data-in-the-secondary-region
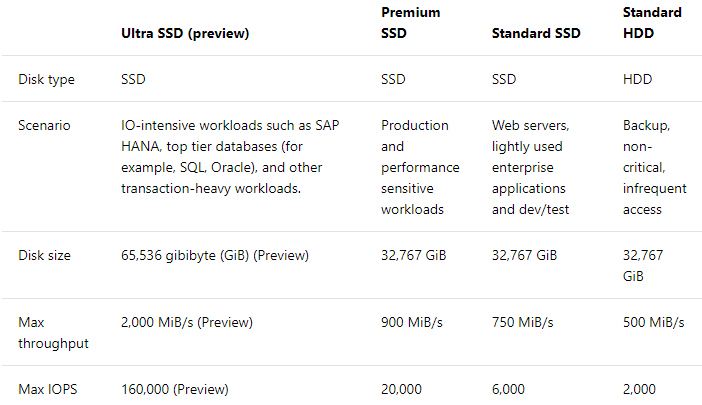
You need to design a solution to meet the SQL Server storage requirements for CONT_SQL3.
Which type of disk should you recommend?
A. Standard SSD Managed Disk
B. Premium SSD Managed Disk
C. Ultra SSD Managed Disk
Suggested Answer: C
CONT_SQL3 requires an initial scale of 35000 IOPS.
Ultra SSD Managed Disk Offerings
The following table provides a comparison of ultra solid-state-drives (SSD) (preview), premium SSD, standard SSD, and standard hard disk drives (HDD) for managed disks to help you decide what to use.
Reference: alt=”Reference Image” />
The following table provides a comparison of ultra solid-state-drives (SSD) (preview), premium SSD, standard SSD, and standard hard disk drives (HDD) for managed disks to help you decide what to use.
<img src=”https://www.examtopics.com/assets/media/exam-media/03774/0002200001.png” alt=”Reference Image” />
Reference: https://docs.microsoft.com/en-us/azure/virtual-machines/windows/disks-types
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are larger than 250MB.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
You are designing a storage solution to store CSV files.
You need to grant a data scientist access to read all the files in a single container of an Azure Storage account. The solution must use the principle of least privilege and provide the highest level of security.
What are two possible ways to achieve the goal? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provide an access key.
B. Assign the Storage Blob Data Reader role at the container level.
C. Assign the Reader role to the storage account.
D. Provide an account shared access signature (SAS).
E. Provide a user delegation shared access signature (SAS).
Suggested Answer: BE
B: When an Azure role is assigned to an Azure AD security principal, Azure grants access to those resources for that security principal. Access can be scoped to the level of the subscription, the resource group, the storage account, or an individual container or queue.
The built-in Data Reader roles provide read permissions for the data in a container or queue.
Note: Permissions are scoped to the specified resource.
For example, if you assign the Storage Blob Data Reader role to user Mary at the level of a container named sample-container, then Mary is granted read access to all of the blobs in that container.
E: A user delegation SAS is secured with Azure Active Directory (Azure AD) credentials and also by the permissions specified for the SAS. A user delegation SAS applies to Blob storage only.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-auth-aad-rbac-portal https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview
You manage a solution that uses Azure HDInsight clusters.
You need to implement a solution to monitor cluster performance and status.
Which technology should you use?
A. Azure HDInsight.NET SDK
B. Azure HDInsight REST API
C. Ambari REST API
D. Azure Log Analytics
E. Ambari Web UI
Suggested Answer: E
Ambari is the recommended tool for monitoring utilization across the whole cluster. The Ambari dashboard shows easily glanceable widgets that display metrics such as CPU, network, YARN memory, and HDFS disk usage. The specific metrics shown depend on cluster type. The “Hosts” tab shows metrics for individual nodes so you can ensure the load on your cluster is evenly distributed. The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Reference: https://azure.microsoft.com/en-us/blog/monitoring-on-hdinsight-part-1-an-overview/ https://ambari.apache.org/
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database that has columns. The columns contain sensitive Personally Identifiable Information (PII) data.
You need to design a solution that tracks and stores all the queries executed against the PII data. You must be able to review the data in Azure Monitor, and the data must be available for at least 45 days.
Solution: You execute a daily stored procedure that retrieves queries from Query Store, looks up the column classifications, and stores the results in a new table in the database.
Does this meet the goal?
You need to design the storage for the telemetry capture system.
What storage solution should you use in the design?
A. Azure Synapse Analytics
B. Azure Databricks
C. Azure Cosmos DB
Suggested Answer: C
Azure Cosmos DB is a globally distributed database service. You can associate any number of Azure regions with your Azure Cosmos account and your data is automatically and transparently replicated.
Scenario:
Telemetry Capture –
The telemetry capture system records each time a vehicle passes in front of a sensor. The sensors run on a custom embedded operating system and record the following telemetry data:
✑ Time
✑ Location in latitude and longitude
✑ Speed in kilometers per hour (kmph)
✑ Length of vehicle in meters
You must write all telemetry data to the closest Azure region. The sensors used for the telemetry capture system have a small amount of memory available and so must write data as quickly as possible to avoid losing telemetry data.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/high-availability
You are designing a serving layer for data. The design must meet the following requirements:
✑ Authenticate users by using Azure Active Directory (Azure AD).
✑ Serve as a hot path for data.
✑ Support query scale out.
✑ Support SQL queries.
What should you include in the design?
A. Azure Data Lake Storage
B. Azure Cosmos DB
C. Azure Blob storage
D. Azure Synapse Analytics
Suggested Answer: B
Do you need serving storage that can serve as a hot path for your data? If yes, narrow your options to those that are optimized for a speed serving layer. This would be Cosmos DB among the options given in this question.
Note: Analytical data stores that support querying of both hot-path and cold-path data are collectively referred to as the serving layer, or data serving storage.
There are several options for data serving storage in Azure, depending on your needs:
✑ Azure Synapse Analytics
✑ Azure Cosmos DB
✑ Azure Data Explorer
Azure SQL Database –
✑ SQL Server in Azure VM
✑ HBase/Phoenix on HDInsight
✑ Hive LLAP on HDInsight
✑ Azure Analysis Services
Incorrect Answers:
A, C: Azure Data Lake Storage & Azure Blob storage are not data serving storage in Azure.
Reference: alt=”Reference Image” />
✑ SQL Server in Azure VM
✑ HBase/Phoenix on HDInsight
✑ Hive LLAP on HDInsight
✑ Azure Analysis Services
Incorrect Answers:
A, C: Azure Data Lake Storage & Azure Blob storage are not data serving storage in Azure.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/analytical-data-stores
You are designing the security for an Azure SQL database.
You have an Azure Active Directory (Azure AD) group named Group1.
You need to recommend a solution to provide Group1 with read access to the database only.
What should you include in the recommendation?
A. a contained database user
B. a SQL login
C. an RBAC role
D. a shared access signature (SAS)
Suggested Answer: A
Create a User for a security group
A best practice for managing your database is to use Windows security groups to manage user access. That way you can simply manage the customer at the
Security Group level in Active Directory granting appropriate permissions. To add a security group to SQL Data Warehouse, you use the Display Name of the security group as the principal in the CREATE USER statement.
CREATE USER [] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA = [<schema>];
In our AD instance, we have a security group called Sales Team with an alias of
salesteam@company.com
. To add this security group to SQL Data Warehouse you simply run the following statement:
CREATE USER [Sales Team] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA = [sales];
Reference: https://blogs.msdn.microsoft.com/sqldw/2017/07/28/adding-ad-users-and-security-groups-to-azure-sql-data-warehouse/
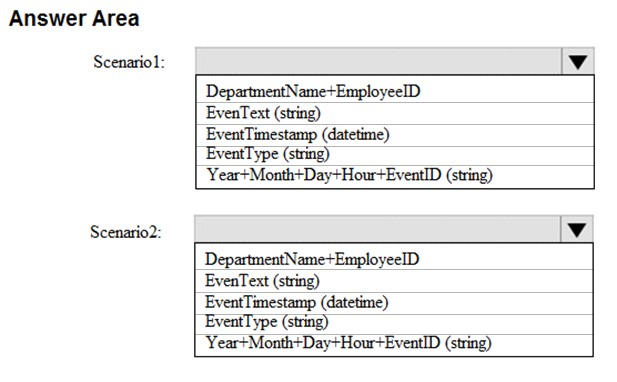
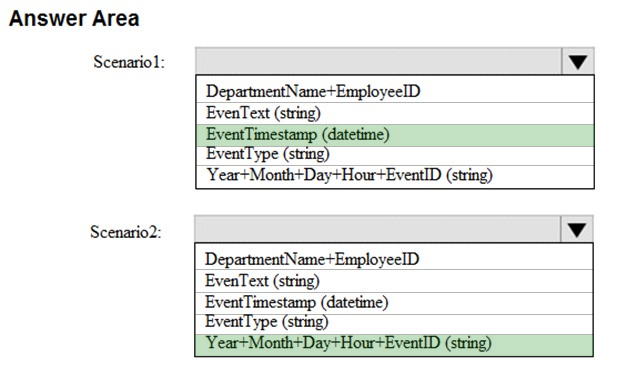
HOTSPOT -
You are designing a solution that will use Azure Table storage. The solution will log records in the following entity.
You are evaluating which partition key to use based on the following two scenarios:
✑ Scenario1: Minimize hotspots under heavy write workloads.
✑ Scenario2: Ensure that date lookups are as efficient as possible for read workloads.
Which partition key should you use for each scenario? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery.
You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements:
✑ Data must be analyzed in real-time.
✑ Data queries must be deployed using continuous integration.
✑ Data must be visualized by using charts and graphs.
✑ Data must be available for ETL operations in the future.
✑ The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Use Azure Analysis Services to query the data. Output query results to Power BI.
B. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
C. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Data Factory to deploy the Azure Stream Analytics application.
D. Develop an application that sends the IoT data to an Azure Event Hub.
E. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Pipelines to deploy the Azure Stream Analytics application.
F. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Suggested Answer: BCD
Access Full DP-201 Mock Test Free
Want a full-length mock test experience? Click here to unlock the complete DP-201 Mock Test Free set and get access to hundreds of additional practice questions covering all key topics.
We regularly update our question sets to stay aligned with the latest exam objectives—so check back often for fresh content!
Start practicing with our DP-201 mock test free today—and take a major step toward exam success!









For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:






You do not expect that the logs will be accessed during the retention periods. You need to recommend a solution for account1 that meets the following requirements: ✑ Automatically deletes the logs at the end of each retention period ✑ Minimizes storage costs What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:



You are evaluating which partition key to use based on the following two scenarios: ✑ Scenario1: Minimize hotspots under heavy write workloads. ✑ Scenario2: Ensure that date lookups are as efficient as possible for read workloads. Which partition key should you use for each scenario? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: