

DP-200 Practice Test Free – 50 Real Exam Questions to Boost Your Confidence
Preparing for the DP-200 exam? Start with our DP-200 Practice Test Free – a set of 50 high-quality, exam-style questions crafted to help you assess your knowledge and improve your chances of passing on the first try.
Taking a DP-200 practice test free is one of the smartest ways to:
- Get familiar with the real exam format and question types
- Evaluate your strengths and spot knowledge gaps
- Gain the confidence you need to succeed on exam day
Below, you will find 50 free DP-200 practice questions to help you prepare for the exam. These questions are designed to reflect the real exam structure and difficulty level. You can click on each Question to explore the details.
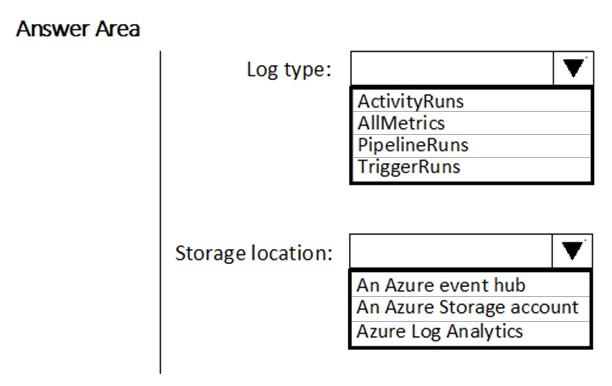
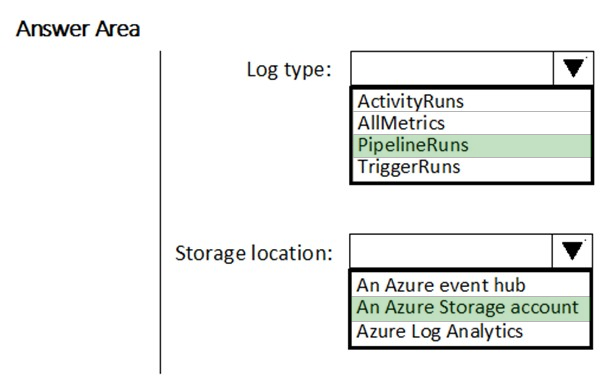
HOTSPOT - You have a new Azure Data Factory environment. You need to periodically analyze pipeline executions from the last 60 days to identify trends in execution durations. The solution must use Azure Log Analytics to query the data and create charts. Which diagnostic settings should you configure in Data Factory? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
HOTSPOT - Your company uses Azure SQL Database and Azure Blob storage. All data at rest must be encrypted by using the company's own key. The solution must minimize administrative effort and the impact to applications which use the database. You need to configure security. What should you implement? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository. You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You have a self-hosted integration runtime in Azure Data Factory. The current status of the integration runtime has the following configurations: ✑ Status: Running ✑ Type: Self-Hosted ✑ Version: 4.4.7292.1 ✑ Running / Registered Node(s): 1/1 ✑ High Availability Enabled: False ✑ Linked Count: 0 ✑ Queue Length: 0 ✑ Average Queue Duration: 0.00s The integration runtime has the following node details: ✑ Name: X-M ✑ Status: Running ✑ Version: 4.4.7292.1 ✑ Available Memory: 7697MB ✑ CPU Utilization: 6% ✑ Network (In/Out): 1.21KBps/0.83KBps ✑ Concurrent Jobs (Running/Limit): 2/14 ✑ Role: Dispatcher/Worker ✑ Credential Status: In Sync Use the drop-down menus to select the answer choice that completes each statement based on the information presented. NOTE: Each correct selection is worth one point. Hot Area:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB. You plan to copy the data from the storage account to an Azure SQL data warehouse. You need to prepare the files to ensure that the data copies quickly. Solution: You modify the files to ensure that each row is more than 1 MB. Does this meet the goal?
A. Yes
B. No
Your company manages a payroll application for its customers worldwide. The application uses an Azure SQL database named DB1. The database contains a table named Employee and an identity column named EmployeeId. A customer requests the EmployeeId be treated as sensitive data. Whenever a user queries EmployeeId, you need to return a random value between 1 and 10 instead of the EmployeeId value. Which masking format should you use?
A. string
B. number
C. default
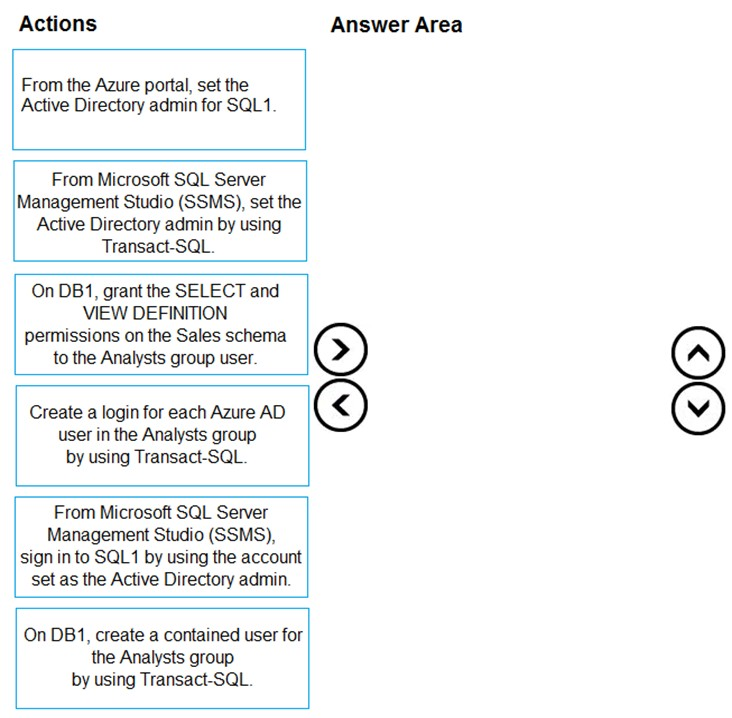
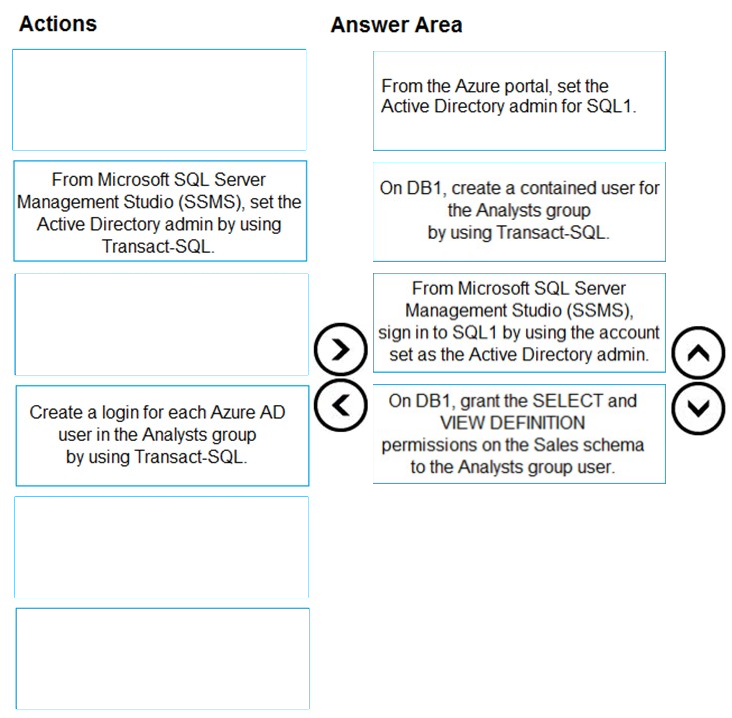
DRAG DROP - You deploy an Azure SQL database named DB1 to an Azure SQL server named SQL1. Currently, only the server admin has access to DB1. An Azure Active Directory (Azure AD) group named Analysts contains all the users who must have access to DB1. You have the following data security requirements: ✑ The Analysts group must have read-only access to all the views and tables in the Sales schema of DB1. ✑ A manager will decide who can access DB1. The manager will not interact directly with DB1. ✑ Users must not have to manage a separate password solely to access DB1. Which four actions should you perform in sequence to meet the data security requirements? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
SIMULATION - Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10543936 -Your company's security policy states that administrators must be able to review a list of the failed logins to an Azure SQL database named db1 during the previous 30 days. You need to modify your Azure environment to meet the security policy requirements. To complete this task, sign in to the Azure portal.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
A. Yes
B. No
You have an alert on a SQL pool in Azure Synapse that uses the signal logic shown in the exhibit.On the same day, failures occur at the following times: ✑ 08:01 ✑ 08:03 ✑ 08:04 ✑ 08:06 ✑ 08:11 ✑ 08:16 ✑ 08:19 The evaluation period starts on the hour. At which times will alert notifications be sent?
A. 08:15 only
B. 08:10, 08:15, and 08:20
C. 08:05 and 08:10 only
D. 08:10 only
E. 08:05 only
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account. Does the solution meet the goal?
A. Yes
B. No
You configure monitoring for an Azure Synapse Analytics implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Storage Gen 2 using an external table. Files with an invalid schema cause errors to occur. You need to monitor for an invalid schema error. For which error should you monitor?
A. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [com.microsoft.polybase.client.KerberosSecureLogin] occurred while accessing external file.’
B. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [No FileSystem for scheme: wasbs] occurred while accessing external file.’
C. Cannot execute the query “Remote Query” against OLE DB provider “SQLNCLI11” for linked server “(null)”, Query aborted- the maximum reject threshold (0 rows) was reached while reading from an external source: 1 rows rejected out of total 1 rows processed.
D. EXTERNAL TABLE access failed due to internal error: ‘Java exception raised on call to HdfsBridge_Connect: Error [Unable to instantiate LoginClass] occurred while accessing external file.’
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You apply an expired tag to the blobs in the storage account. Does this meet the goal?
A. Yes
B. No
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You need to replicate db1 to a new Azure SQL server named REPL10277521 in the Central Canada region. To complete this task, sign in to the Azure portal. NOTE: This task might take several minutes to complete. You can perform other tasks while the task completes or ends this section of the exam. To complete this task, sign in to the Azure portal.
You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU% Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Watermark Delay
B. Late Input Events
C. Out of order Events
D. Backlogged Input Events
E. Function Events
DRAG DROP - You need to provision the polling data storage account. How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


You have an Azure subscription that contains an Azure Data Factory version 2 (V2) data factory named df1. Df1 contains a linked service. You have an Azure Key vault named vault1 that contains an encryption key named key1. You need to encrypt df1 by using key1. What should you do first?
A. Disable purge protection on vault1.
B. Create a self-hosted integration runtime.
C. Disable soft delete on vault1.
D. Remove the linked service from df1.
Your company uses several Azure HDInsight clusters. The data engineering team reports several errors with some applications using these clusters. You need to recommend a solution to review the health of the clusters. What should you include in your recommendation?
A. Azure Automation
B. Log Analytics
C. Application Insights
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table. Which output mode should you use?
A. complete
B. update
C. append
You plan to monitor the performance of Azure Blob storage by using Azure Monitor. You need to be notified when there is a change in the average time it takes for a storage service or API operation type to process requests. For which two metrics should you set up alerts? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. SuccessE2ELatency
B. SuccessServerLatency
C. UsedCapacity
D. Egress
E. Ingress
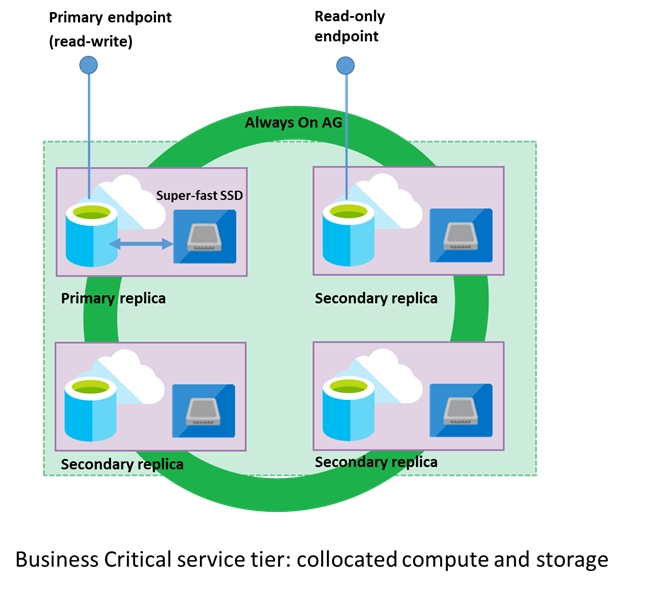
A company plans to use Azure SQL Database to support a mission-critical application. The application must be highly available without performance degradation during maintenance windows. You need to implement the solution. Which three technologies should you implement? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Premium service tier
B. Virtual machine Scale Sets
C. Basic service tier
D. SQL Data Sync
E. Always On availability groups
F. Zone-redundant configuration
HOTSPOT - You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct selection is worth one point. Hot Area:


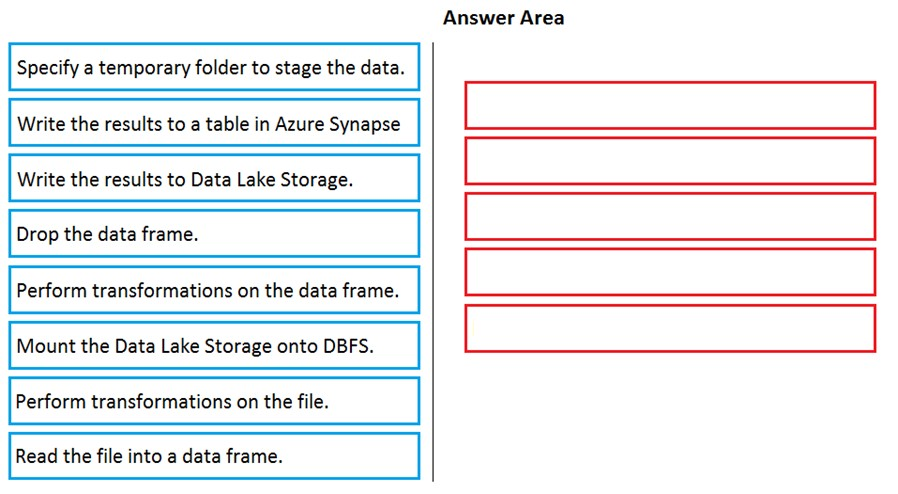
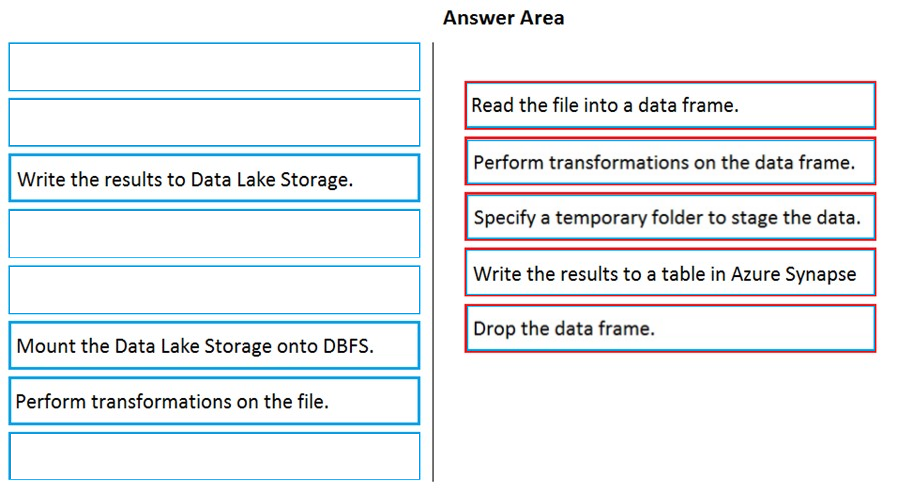
DRAG DROP - You have an Azure Data Lake Storage Gen2 account that contains JSON files for customers. The files contain two attributes named FirstName and LastName. You need to copy the data from the JSON files to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values. You create the following components: ✑ A destination table in Azure Synapse ✑ An Azure Blob storage container ✑ A service principal Which five actions should you perform in sequence next in a Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB. You plan to copy the data from the storage account to an enterprise data warehouse in Azure Synapse Analytics. You need to prepare the files to ensure that the data copies quickly. Solution: You modify the files to ensure that each row is less than 1 MB. Does this meet the goal?
A. Yes
B. No
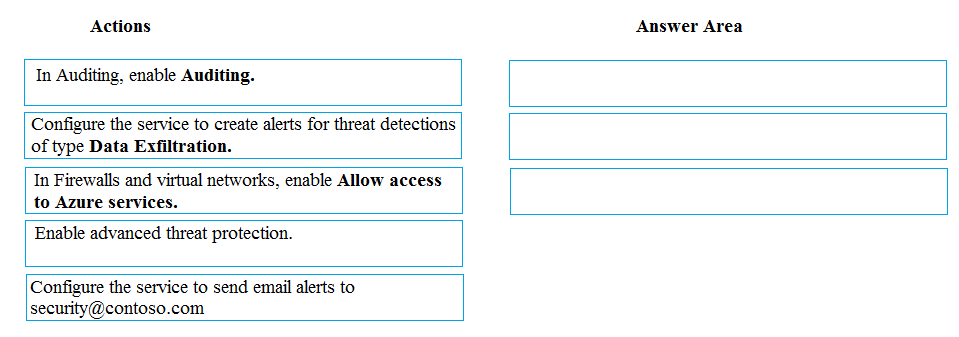
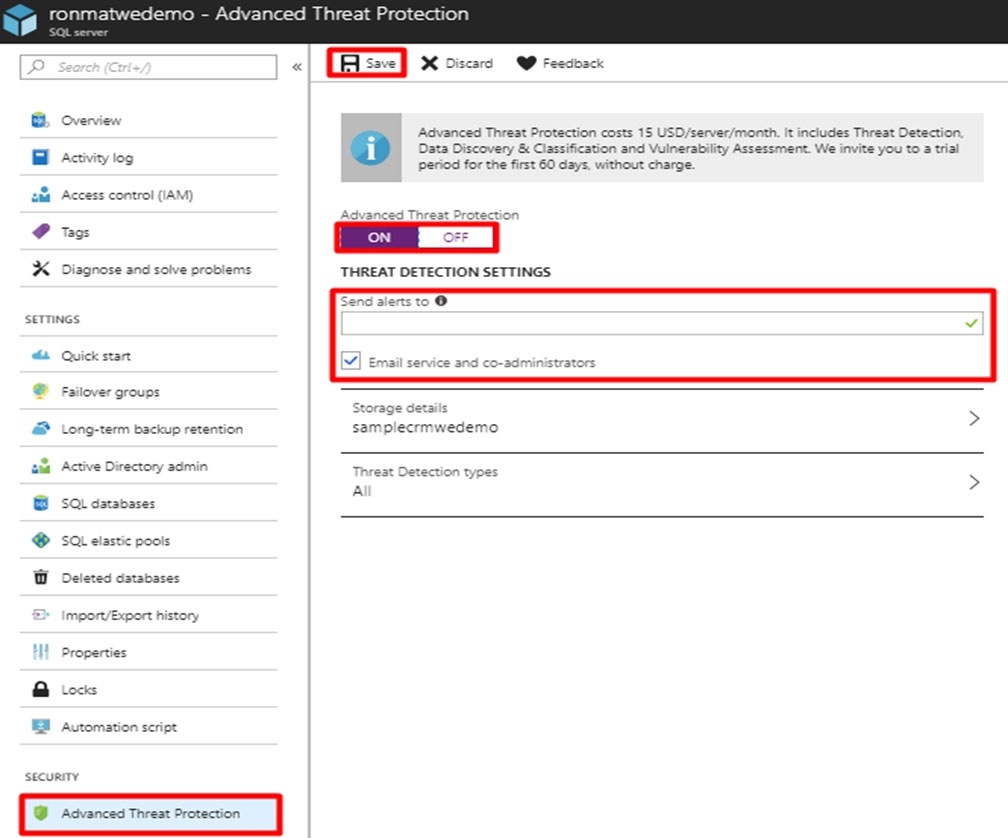
DRAG DROP - A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations. You must monitor data usage, and data copied from the system to prevent data leakage. You need to configure Azure SQL Database to email a specific user when data leakage occurs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

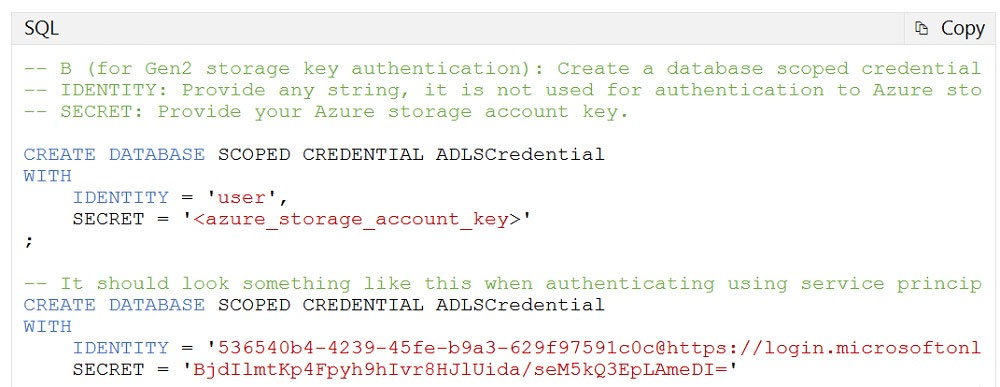
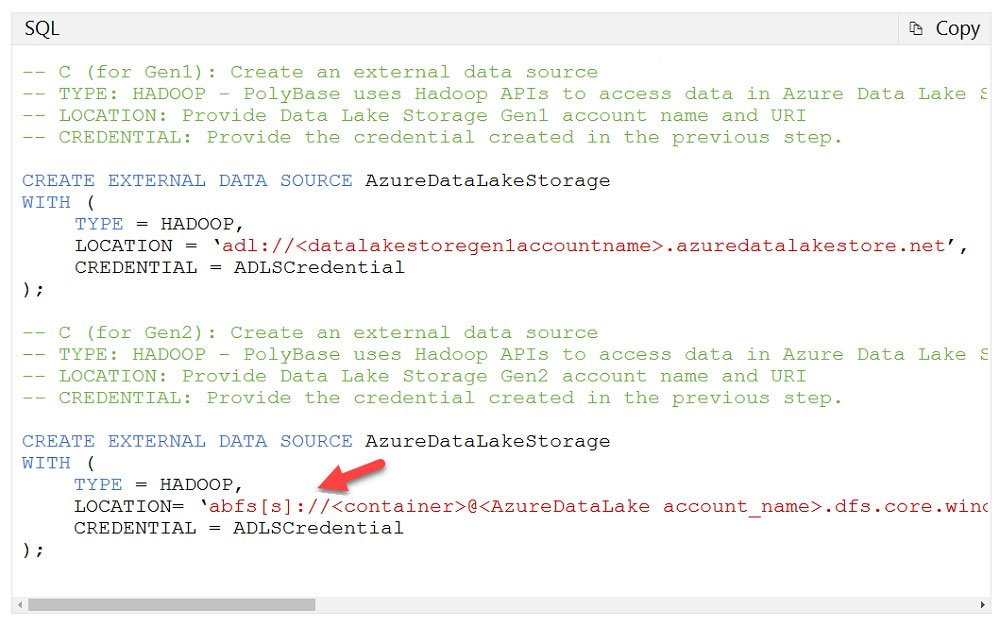
You have an Azure Data Lake Storage Gen2 account. You have a number of CSV files loaded in the account. Each file has a header row. After the header row is a property that is formatted by carriage return (/r) and line feed (/n). You need to load the files daily as a batch into Azure SQL Data warehouse using Polybase. You have to skip the header row when the files are imported. Which of the following actions would you take to implement this requirement? (Choose three.)
A. Create an external data source and ensure to use the abfs location
B. Create an external data source and ensure to use the Hadoop location
C. Create an external file format and set the First_row option
D. Create a database scoped credential that uses OAuth2 token and a key
E. Use the CREATE EXTERNAL TABLE AS SELECT and create a view that removes the empty row
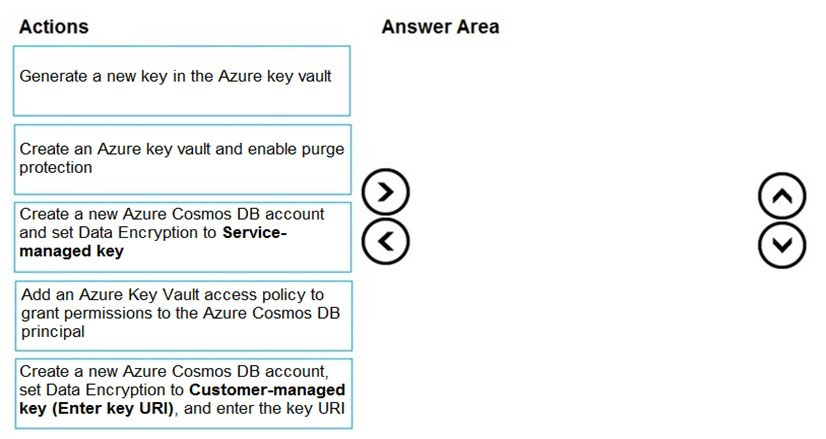
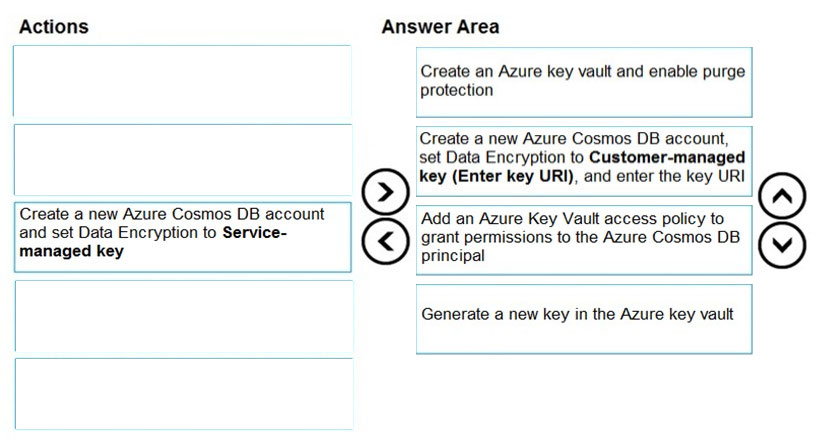
DRAG DROP - You need to create an Azure Cosmos DB account that will use encryption keys managed by your organization. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You schedule an Azure Data Factory pipeline. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You create a lookup collection that uses ProductName as a partition key and OrderId as a value. Does this meet the goal?
A. Yes
B. No
You have an Azure Blob storage account. Developers report that an HTTP 403 (Forbidden) error is generated when a client application attempts to access the storage account. You cannot see the error messages in Azure Monitor. What is a possible cause of the error?
A. The client application is using an expired shared access signature (SAS) when it sends a storage request.
B. The client application deleted, and then immediately recreated a blob container that has the same name.
C. The client application attempted to use a shared access signature (SAS) that did not have the necessary permissions.
D. The client application attempted to use a blob that does not exist in the storage service.
You have to create a new single database instance of Microsoft Azure SQL database. You must ensure that client connections are accepted via a workstation. The workstation will use SQL Server Management Studio to connect to the database instance. Which of the following Powershell commands would you execute to create and configure the database? (Choose three.)
A. New-AzureRmSqlElasticPool
B. New-AzureRmSqlServerFirewallRule
C. New-AzureRmSqlServer
D. New-AzureRmSqlServerVirtualNetworkRule
E. New-AzureRmSqlDatabase

HOTSPOT - You have an Azure subscription that contains the following resources: ✑ An Azure Active Directory (Azure AD) tenant that contains a security group named Group1 ✑ An Azure Synapse Analytics SQL pool named Pool1 You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. Hot Area:


You need to set up Azure Data Factory pipelines to meet data movement requirements. Which integration runtime should you use?
A. self-hosted integration runtime
B. Azure-SSIS Integration Runtime
C. .NET Common Language Runtime (CLR)
D. Azure integration runtime

Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Use Azure Data Factory to convert the parquet files to CSV files 2. Create an external data source pointing to the Azure storage account 3. Create an external file format and external table using the external data source 4. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You apply an Azure policy that tags the storage account. Does this meet the goal?
A. Yes
B. No
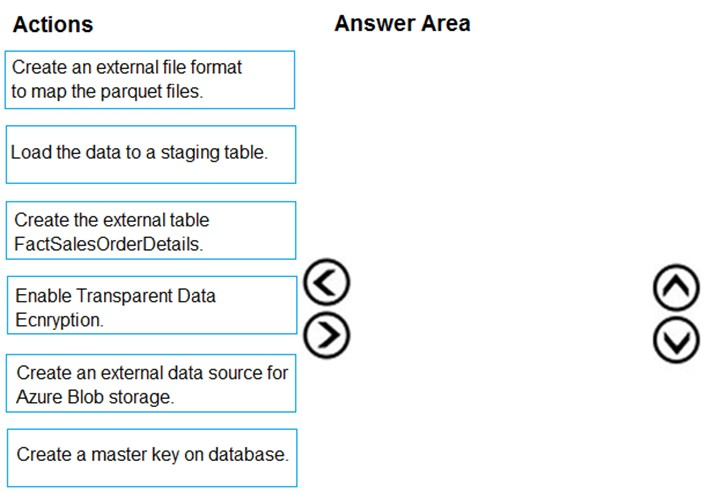
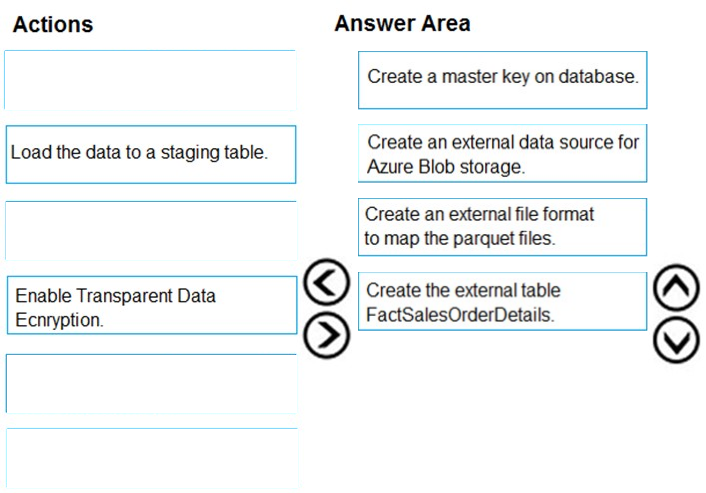
DRAG DROP - You are creating a managed data warehouse solution on Microsoft Azure. You must use PolyBase to retrieve data from Azure Blob storage that resides in parquet format and load the data into a large table called FactSalesOrderDetails. You need to configure Azure Synapse Analytics to receive the data. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year. You need to implement the Azure SQL Database elastic pool to minimize cost. Which option or options should you configure?
A. Number of transactions only
B. eDTUs per database only
C. Number of databases only
D. CPU usage only
E. eDTUs and max data size
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You schedule an Azure Data Factory pipeline with a delete activity. Does this meet the goal?
A. Yes
B. No
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure storage account 2. Create a workload group using the Azure storage account name as the pool name 3. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data. Which input type should you use for the reference data?
A. Azure Cosmos DB
B. Azure Event Hubs
C. Azure Blob storage
D. Azure IoT Hub
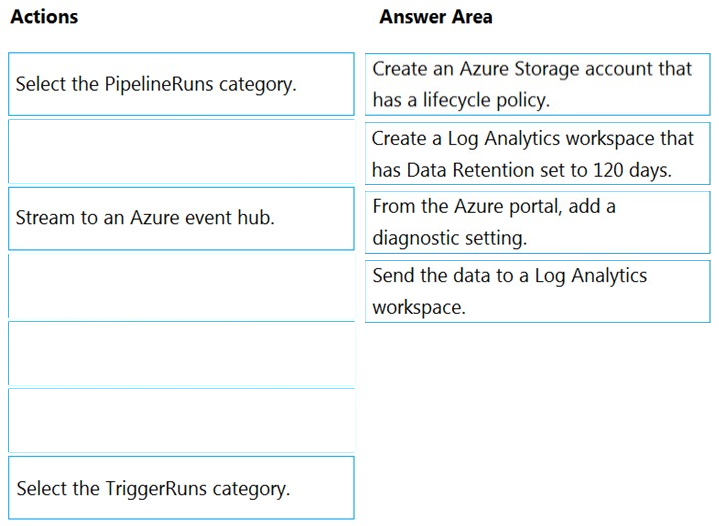
DRAG DROP - You have an Azure data factory. You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:

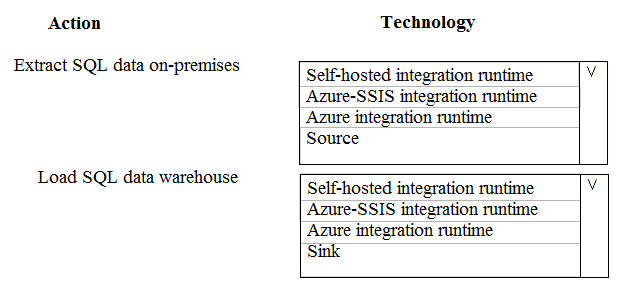
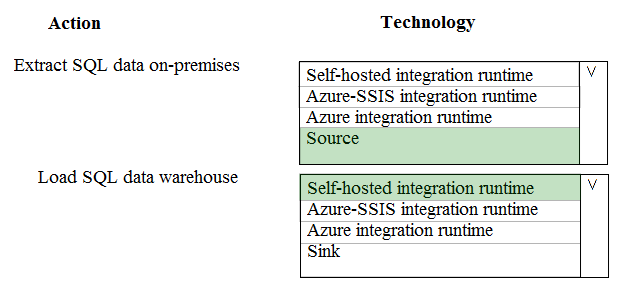
HOTSPOT - A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse. The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort. You need to create the pipeline system. Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
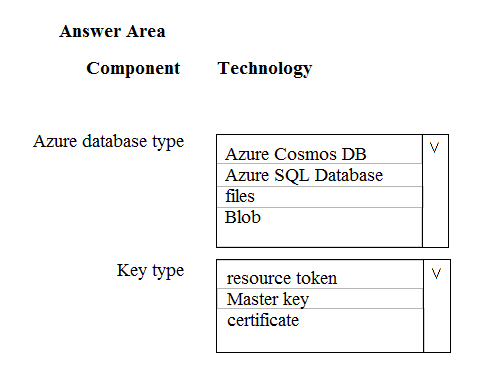
HOTSPOT - You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:Which database and authorization types are used? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases at multiple locations. The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid single points of failure during connection and transfer to the cloud. The solution must also minimize latency. You need to secure the transfer of data between on-premises databases and Microsoft Azure. What should you do?
A. Install a standalone on-premises Azure data gateway at each location
B. Install an on-premises data gateway in personal mode at each location
C. Install an Azure on-premises data gateway at the primary location
D. Install an Azure on-premises data gateway as a cluster at each location
HOTSPOT - You have a SQL pool in Azure Synapse. You plan to load data from Azure Blob storage to a staging table. Approximately 1 million rows of data will be loaded daily. The table will be truncated before each daily load. You need to create the staging table. The solution must minimize how long it takes to load the data to the staging table. How should you configure the table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


SIMULATION - Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10543936 -You need to create an Azure Storage account named account10543936. The solution must meet the following requirements: ✑ Minimize storage costs. ✑ Ensure that account10543936 can store many image files. Ensure that account10543936 can quickly retrieve stored image files.
To complete this task, sign in to the Azure portal.
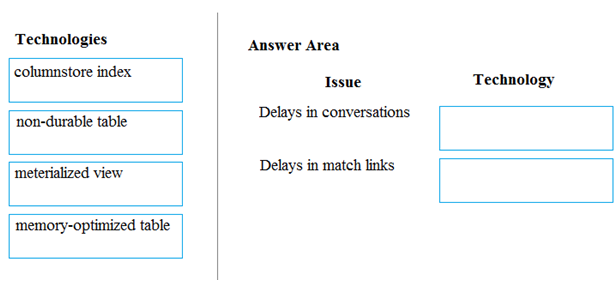
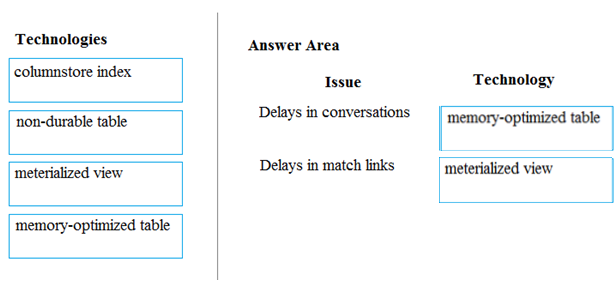
DRAG DROP - A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets. When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation. Customers report the following issues: ✑ Delays occur during live conversations ✑ A delay occurs before matching links appear after code snippets are added to conversations You need to resolve the performance issues. Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address. You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes. You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention. Solution: You implement a Stream Analytics job that has one streaming input, one reference input, two queries, and four outputs. Does this meet the goal?
A. Yes
B. No
A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU). You need to optimize performance for the Azure Stream Analytics job. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Implement event ordering
B. Scale the SU count for the job up
C. Implement Azure Stream Analytics user-defined functions (UDF)
D. Scale the SU count for the job down
E. Implement query parallelization by partitioning the data output
F. Implement query parallelization by partitioning the data input
You need to ensure that phone-based poling data can be analyzed in the PollingData database. How should you configure Azure Data Factory?
A. Use a tumbling schedule trigger
B. Use an event-based trigger
C. Use a schedule trigger
D. Use manual execution
Free Access Full DP-200 Practice Test Free Questions
If you’re looking for more DP-200 practice test free questions, click here to access the full DP-200 practice test.
We regularly update this page with new practice questions, so be sure to check back frequently.
Good luck with your DP-200 certification journey!