

DP-200 Practice Questions Free – 50 Exam-Style Questions to Sharpen Your Skills
Are you preparing for the DP-200 certification exam? Kickstart your success with our DP-200 Practice Questions Free – a carefully selected set of 50 real exam-style questions to help you test your knowledge and identify areas for improvement.
Practicing with DP-200 practice questions free gives you a powerful edge by allowing you to:
- Understand the exam structure and question formats
- Discover your strong and weak areas
- Build the confidence you need for test day success
Below, you will find 50 free DP-200 practice questions designed to match the real exam in both difficulty and topic coverage. They’re ideal for self-assessment or final review. You can click on each Question to explore the details.
HOTSPOT - You have a self-hosted integration runtime in Azure Data Factory. The current status of the integration runtime has the following configurations: ✑ Status: Running ✑ Type: Self-Hosted ✑ Version: 4.4.7292.1 ✑ Running / Registered Node(s): 1/1 ✑ High Availability Enabled: False ✑ Linked Count: 0 ✑ Queue Length: 0 ✑ Average Queue Duration: 0.00s The integration runtime has the following node details: ✑ Name: X-M ✑ Status: Running ✑ Version: 4.4.7292.1 ✑ Available Memory: 7697MB ✑ CPU Utilization: 6% ✑ Network (In/Out): 1.21KBps/0.83KBps ✑ Concurrent Jobs (Running/Limit): 2/14 ✑ Role: Dispatcher/Worker ✑ Credential Status: In Sync Use the drop-down menus to select the answer choice that completes each statement based on the information presented. NOTE: Each correct selection is worth one point. Hot Area:


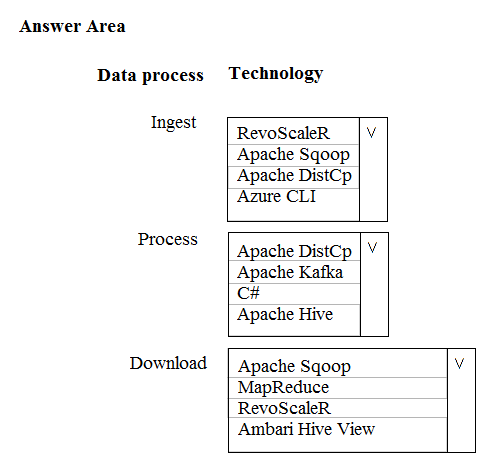
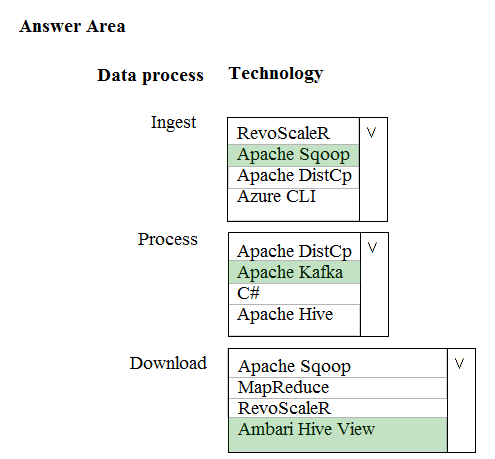
HOTSPOT - A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements: ✑ Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service ✑ Use an Azure Data Lake Storage account to store processed data ✑ Allow users to download processed data You need to recommend technologies for the solution. Which technologies should you use? To answer, select the appropriate options in the answer area. Hot Area:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You change the partition key to include ProductName. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure SQL database named DB1 that contains a table named Table1. Table1 has a field named Customer_ID that is varchar(22). You need to implement masking for the Customer_ID field to meet the following requirements: ✑ The first two prefix characters must be exposed. ✑ The last four suffix characters must be exposed. ✑ All other characters must be masked. Solution: You implement data masking and use a credit card function mask. Does this meet the goal?
A. Yes
B. No
HOTSPOT - You are implementing automatic tuning mode for Azure SQL databases. Automatic tuning mode is configured as shown in the following table.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


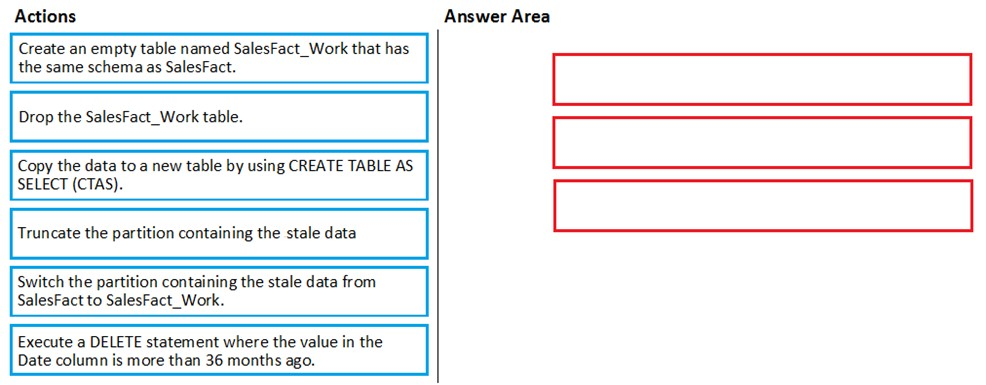
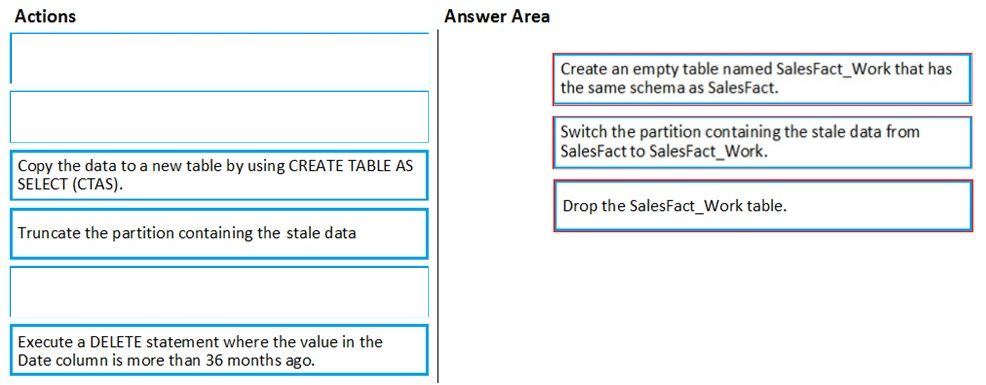
A company has an Azure SQL Datawarehouse. They have a table named whizlab_salesfact that contains data for the past 12 months. The data is partitioned by month. The table contains around a billion rows. The table has clustered columnstore indexes. At the beginning of each month you need to remove the data from the table that is older than 12 months. Which of the following actions would you implement for this requirement? (Choose three.)
A. Create a new empty table named XYZ_salesfact_new that has the same schema as XYZ_salesfact
B. Drop the XYZ_salesfact_new table
C. Copy the data to the new table by using CREATE TABLE AS SELECT (CTAS)
D. Truncate the partition containing the stale data
E. Switch the partition containing the stale data from XYZ_salesfact to XYZ_salesfact_new
F. Execute the DELETE statement where the value in the Date column is greater than 12 months
You need to develop a pipeline for processing data. The pipeline must meet the following requirements: ✑ Scale up and down resources for cost reduction ✑ Use an in-memory data processing engine to speed up ETL and machine learning operations. ✑ Use streaming capabilities ✑ Provide the ability to code in SQL, Python, Scala, and R Integrate workspace collaboration with GitWhat should you use?
A. HDInsight Spark Cluster
B. Azure Stream Analytics
C. HDInsight Hadoop Cluster
D. Azure SQL Data Warehouse
E. HDInsight Kafka Cluster
F. HDInsight Storm Cluster
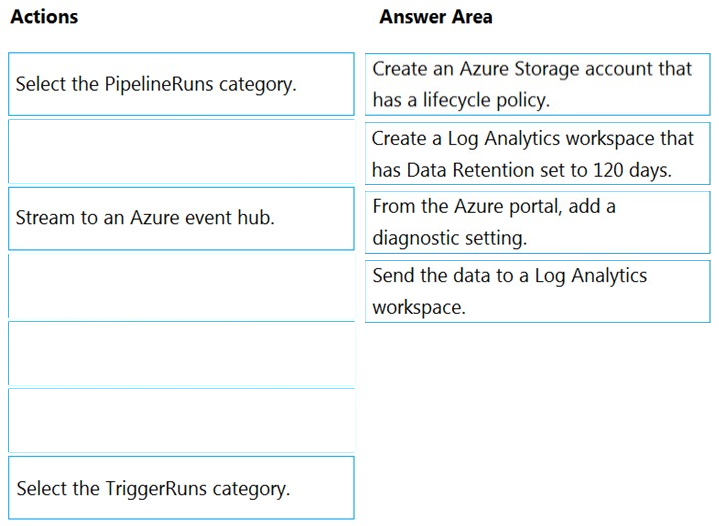
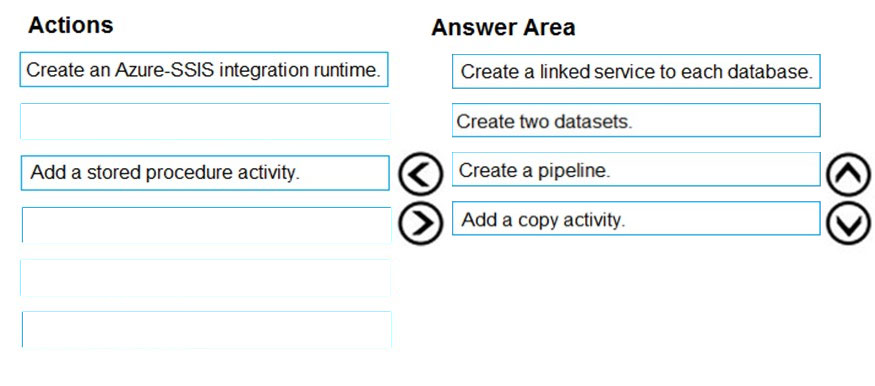
DRAG DROP - You have an Azure data factory. You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:

You plan to perform batch processing in Azure Databricks once daily. Which type of Databricks cluster should you use?
A. automated
B. interactive
C. High Concurrency
You develop data engineering solutions for a company. You must integrate the company's on-premises Microsoft SQL Server data with Microsoft Azure SQL Database. Data must be transformed incrementally. You need to implement the data integration solution. Which tool should you use to configure a pipeline to copy data?
A. Use the Copy Data tool with Blob storage linked service as the source
B. Use Azure PowerShell with SQL Server linked service as a source
C. Use Azure Data Factory UI with Blob storage linked service as a source
D. Use the .NET Data Factory API with Blob storage linked service as the source
DRAG DROP - You need to provision the polling data storage account. How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Use Azure Data Factory to convert the parquet files to CSV files 2. Create an external data source pointing to the Azure storage account 3. Create an external file format and external table using the external data source 4. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
DRAG DROP - A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations. You must monitor data usage, and data copied from the system to prevent data leakage. You need to configure Azure SQL Database to email a specific user when data leakage occurs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
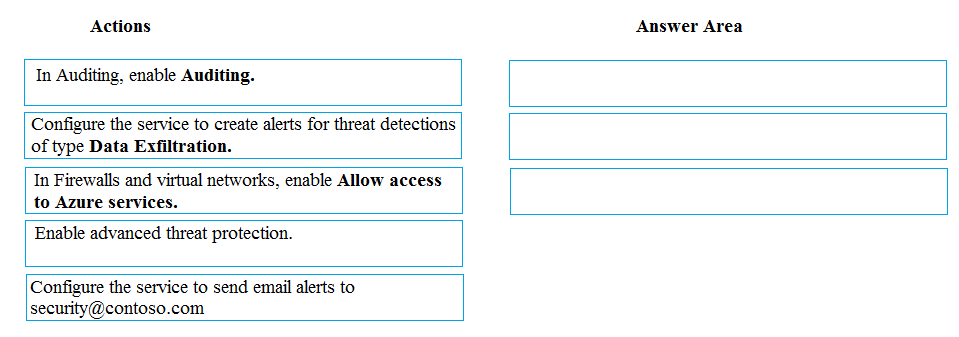

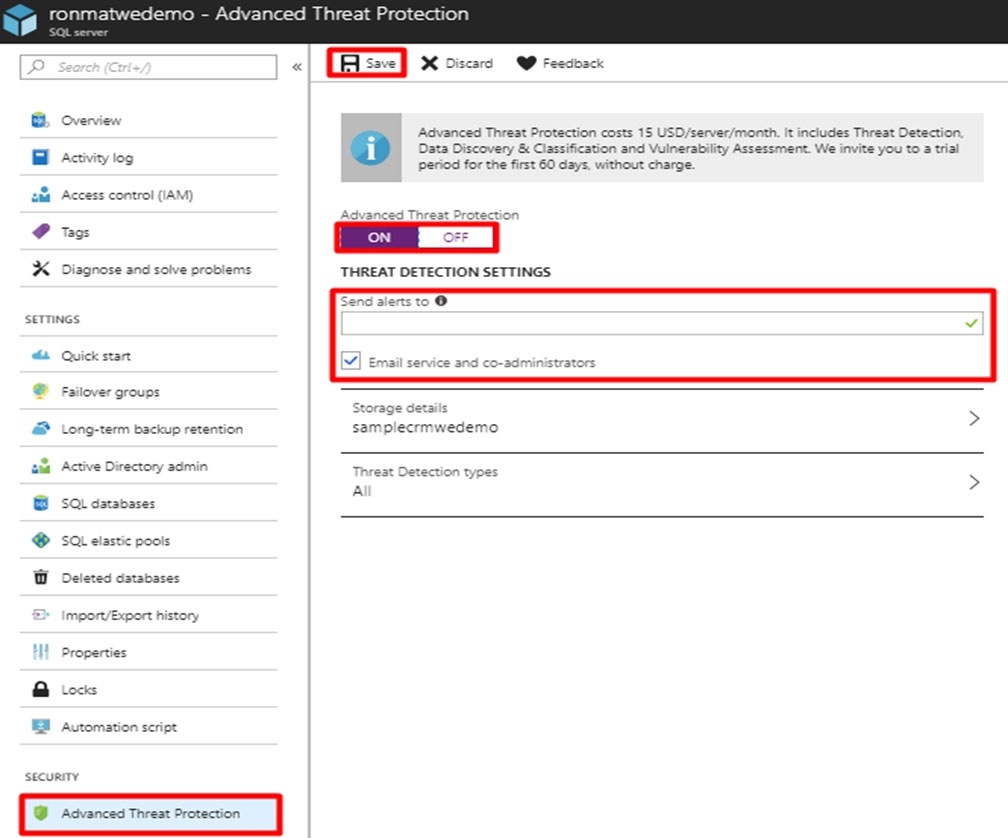
Contoso, Ltd. plans to configure existing applications to use Azure SQL Database. When security-related operations occur, the security team must be informed. You need to configure Azure Monitor while minimizing administrative efforts. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create a new action group to email alerts@contoso.com.
B. Use alerts@contoso.com as an alert email address.
C. Use all security operations as a condition.
D. Use all Azure SQL Database servers as a resource.
E. Query audit log entries as a condition.
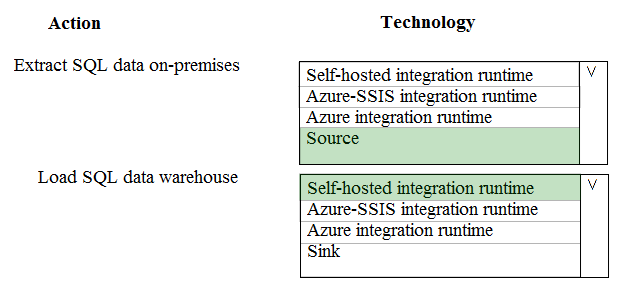
HOTSPOT - A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse. The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort. You need to create the pipeline system. Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
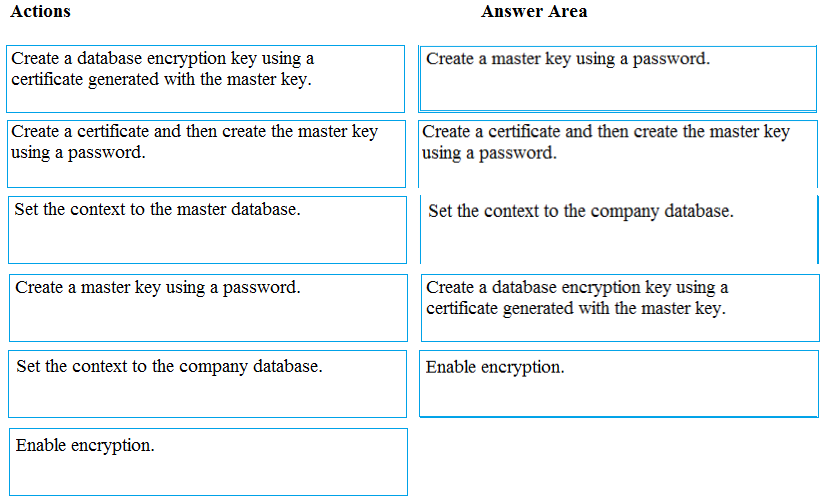
DRAG DROP - You manage security for a database that supports a line of business application. Private and personal data stored in the database must be protected and encrypted. You need to configure the database to use Transparent Data Encryption (TDE). Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Use Azure Data Factory to convert the parquet files to CSV files 2. Create an external data source pointing to the Azure Data Lake Gen 2 storage account 3. Create an external file format and external table using the external data source 4. Load the data using the CREATE TABLE AS SELECT statement Does the solution meet the goal?
A. Yes
B. No
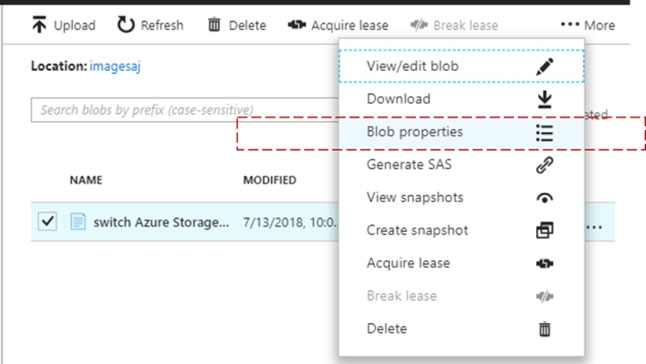
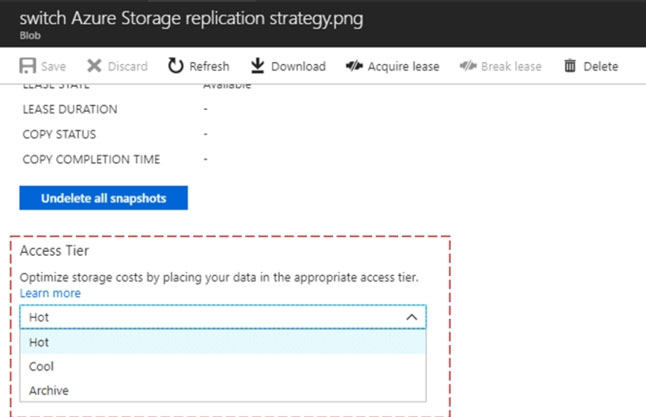
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You need to ensure that you can recover any blob data from an Azure Storage account named storage 10277521 up to 30 days after the data is deleted. To complete this task, sign in to the Azure portal.
You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU% Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Watermark Delay
B. Late Input Events
C. Out of order Events
D. Backlogged Input Events
E. Function Events
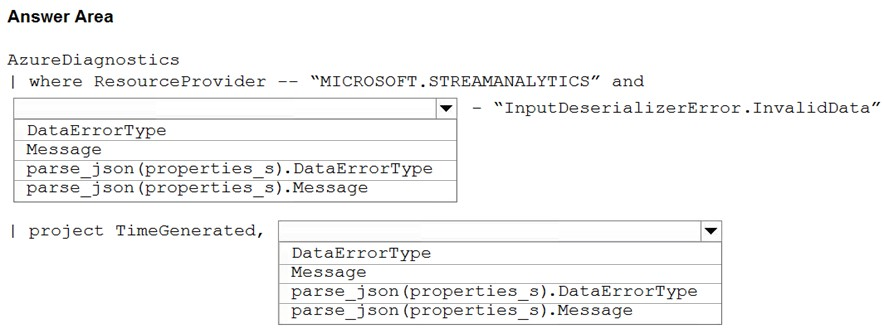
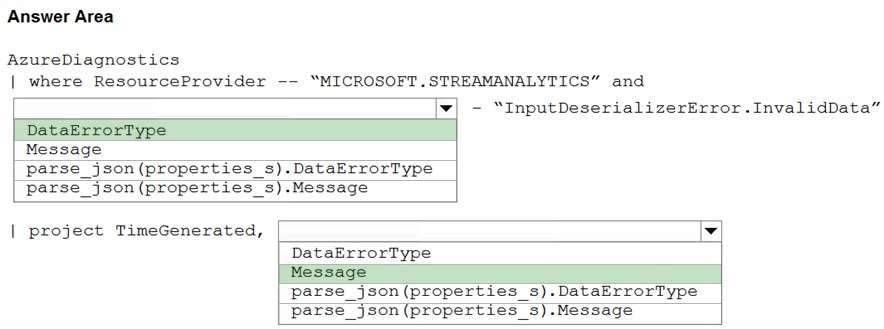
HOTSPOT - You have an Azure Stream Analytics job named ASA1. The Diagnostic settings for ASA1 are configured to write errors to Log Analytics. ASA1 reports an error, and the following message is sent to Log Analytics.You need to write a Kusto query language query to identify all instances of the error and return the message field. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
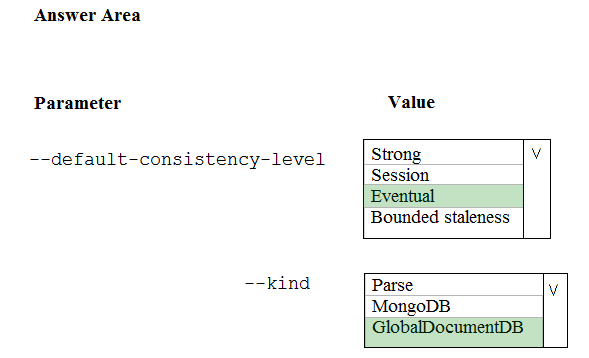
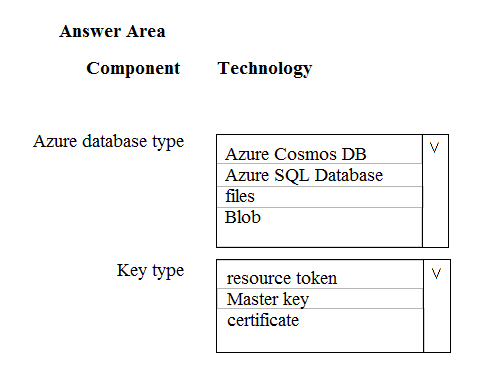
HOTSPOT - A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command: az cosmosdb create -`"name "cosmosdbdev1" `"-resource-group "rgdev" You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You apply an Azure Blob storage lifecycle policy. Does this meet the goal?
A. Yes
B. No
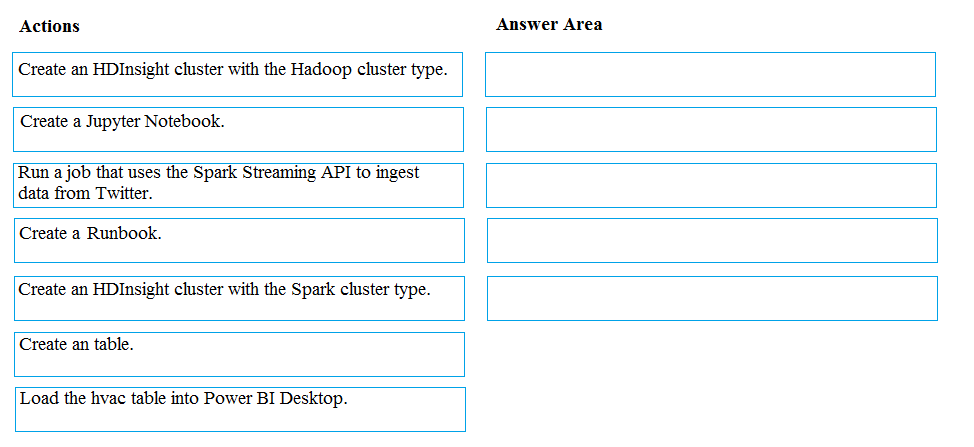
You develop data engineering solutions for a company. You need to ingest and visualize real-time Twitter data by using Microsoft Azure. Which three technologies should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Event Grid topic
B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
D. Logic App that sends Twitter posts which have target keywords to Azure
E. Event Grid subscription
F. Event Hub instance
You have an Azure virtual machine that has Microsoft SQL Server installed. The database on the virtual machine contains a table named Table1. You need to copy the data from Table1 to an Azure Data Lake Storage Gen2 account by using an Azure Data Factory V2 copy activity. Which type of integration runtime should you use?
A. Azure integration runtime
B. self-hosted integration runtime
C. Azure-SSIS integration runtime
Your company uses several Azure HDInsight clusters. The data engineering team reports several errors with some applications using these clusters. You need to recommend a solution to review the health of the clusters. What should you include in your recommendation?
A. Azure Automation
B. Log Analytics
C. Application Insights
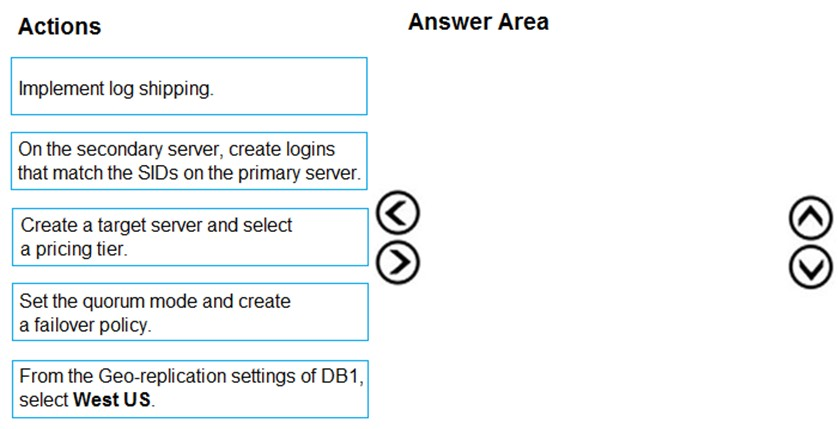
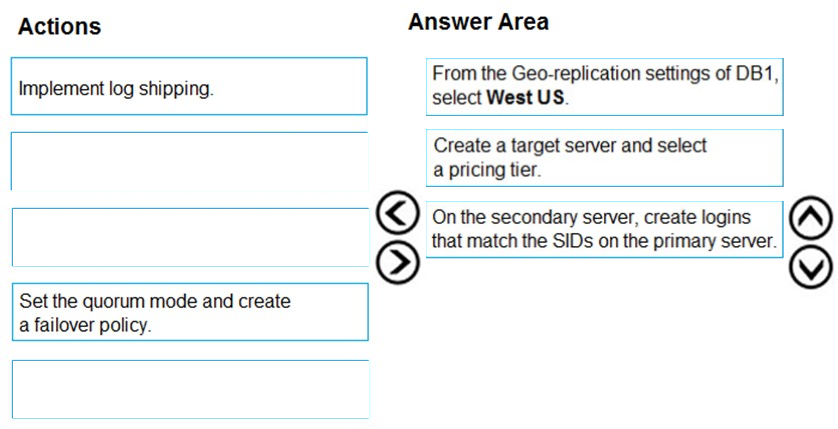
DRAG DROP - You have an Azure SQL database named DB1 in the East US 2 region. You need to build a secondary geo-replicated copy of DB1 in the West US region on a new server. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
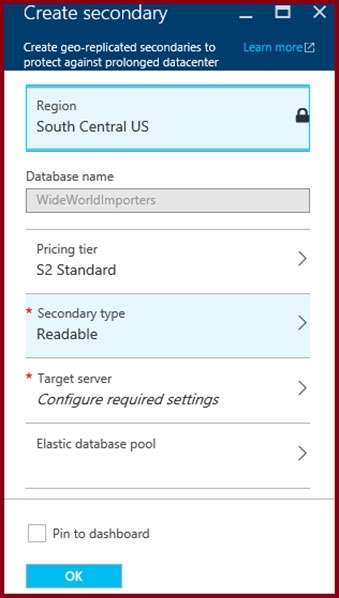
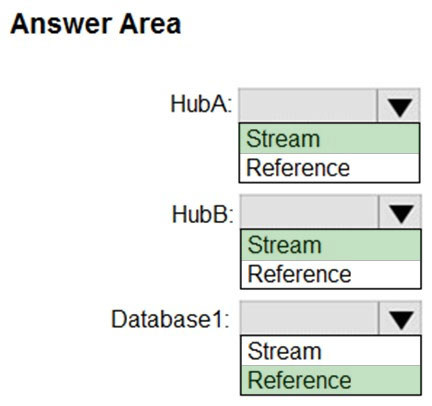
HOTSPOT - You have an Azure SQL database named Database1 and two Azure event hubs named HubA and HubB. The data consumed from each source is shown in the following table.You need to implement Azure Stream Analytics to calculate the average fare per mile by driver. How should you configure the Stream Analytics input for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

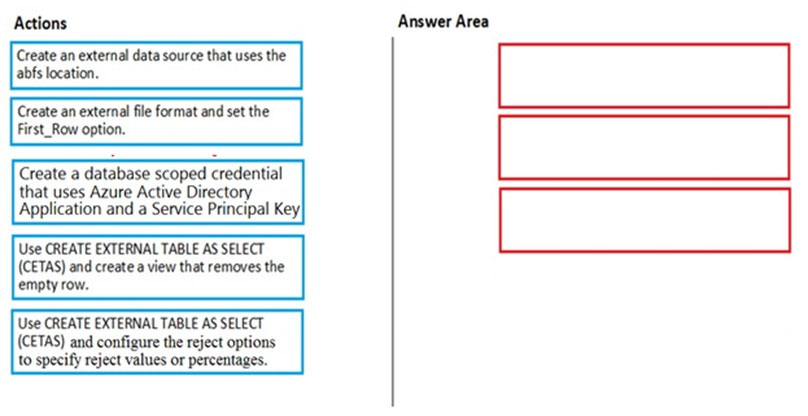
DRAG DROP - You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a property formatted carriage return (/r) and line feed (/n). You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase. You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

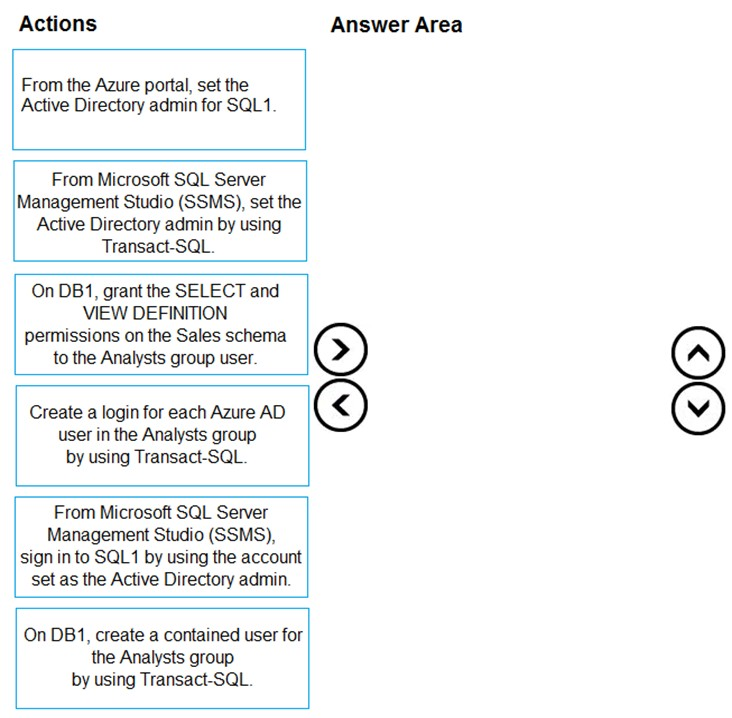
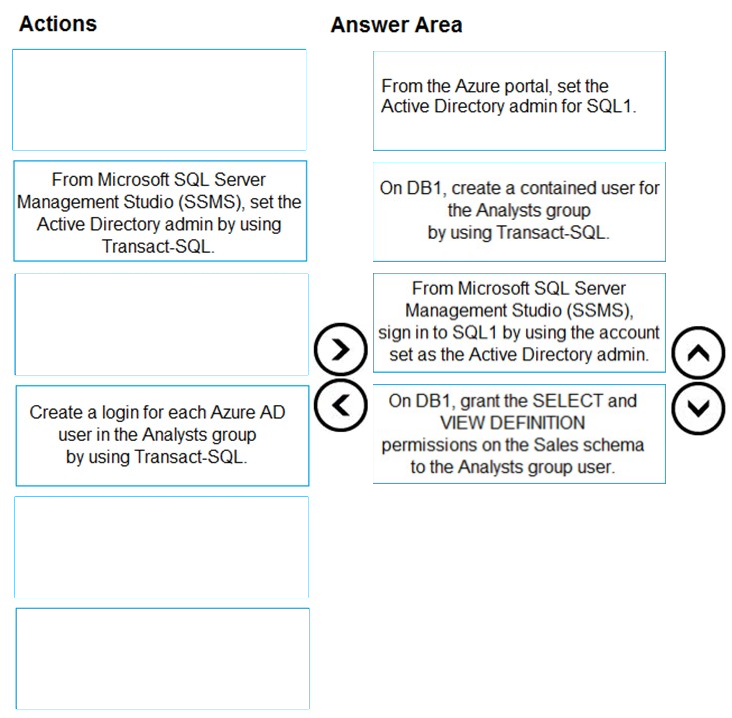
DRAG DROP - You deploy an Azure SQL database named DB1 to an Azure SQL server named SQL1. Currently, only the server admin has access to DB1. An Azure Active Directory (Azure AD) group named Analysts contains all the users who must have access to DB1. You have the following data security requirements: ✑ The Analysts group must have read-only access to all the views and tables in the Sales schema of DB1. ✑ A manager will decide who can access DB1. The manager will not interact directly with DB1. ✑ Users must not have to manage a separate password solely to access DB1. Which four actions should you perform in sequence to meet the data security requirements? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
HOTSPOT - You have an Azure subscription that contains the following resources: ✑ An Azure Active Directory (Azure AD) tenant that contains a security group named Group1 ✑ An Azure Synapse Analytics SQL pool named Pool1 You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. Hot Area:


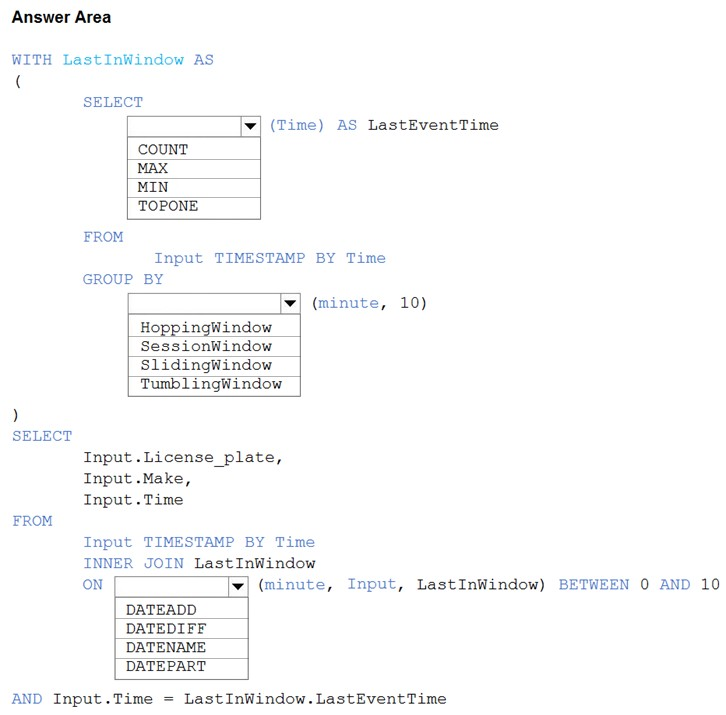
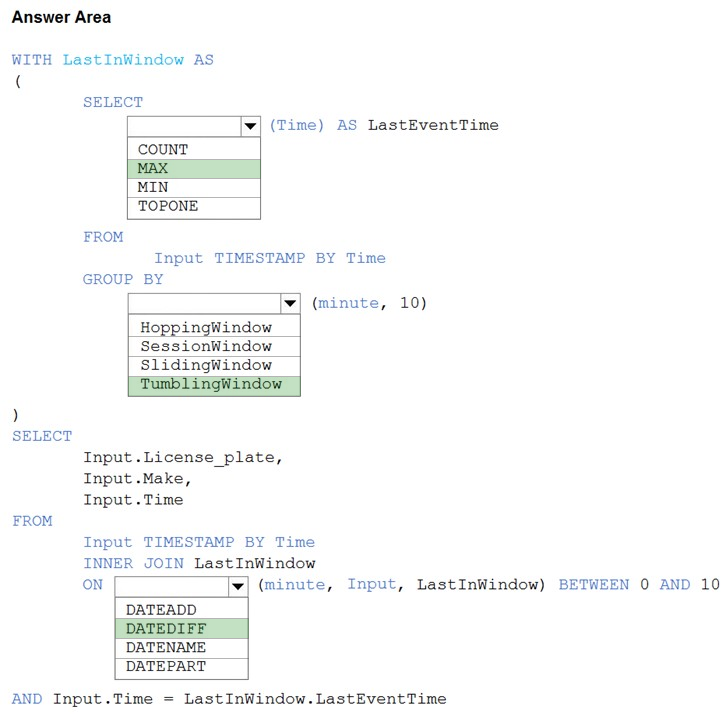
HOTSPOT - You are processing streaming data from vehicles that pass through a toll booth. You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have a SQL pool in Azure Synapse. You discover that some queries fail or take a long time to complete. You need to monitor for transactions that have rolled back. Which dynamic management view should you query?
A. sys.dm_pdw_nodes_tran_database_transactions
B. sys.dm_pdw_waits
C. sys.dm_pdw_request_steps
D. sys.dm_pdw_exec_sessions
HOTSPOT - You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:Which database and authorization types are used? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You are monitoring the Data Factory pipeline that runs from Cosmos DB to SQL Database for Race Central. You discover that the job takes 45 minutes to run. What should you do to improve the performance of the job?
A. Decrease parallelism for the copy activities.
B. Increase that data integration units.
C. Configure the copy activities to use staged copy.
D. Configure the copy activities to perform compression.
HOTSPOT - Which masking functions should you implement for each column to meet the data masking requirements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


DRAG DROP - You develop data engineering solutions for a company. A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution. Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

DRAG DROP - You have a table named SalesFact in an enterprise data warehouse in Azure Synapse Analytics. SalesFact contains sales data from the past 36 months and has the following characteristics: ✑ Is partitioned by month ✑ Contains one billion rows ✑ Has clustered columnstore indexes At the beginning of each month, you need to remove data from SalesFact that is older than 36 months as quickly as possible. Which three actions should you perform in sequence in a stored procedure? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
DRAG DROP - Your company manages on-premises Microsoft SQL Server pipelines by using a custom solution. The data engineering team must implement a process to pull data from SQL Server and migrate it to Azure Blob storage. The process must orchestrate and manage the data lifecycle. You need to configure Azure Data Factory to connect to the on-premises SQL Server database. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
You are developing a data engineering solution for a company. The solution will store a large set of key-value pair data by using Microsoft Azure Cosmos DB. The solution has the following requirements: ✑ Data must be partitioned into multiple containers. ✑ Data containers must be configured separately. ✑ Data must be accessible from applications hosted around the world. ✑ The solution must minimize latency. You need to provision Azure Cosmos DB. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Configure account-level throughput.
B. Provision an Azure Cosmos DB account with the Azure Table API. Enable geo-redundancy.
C. Configure table-level throughput.
D. Replicate the data globally by manually adding regions to the Azure Cosmos DB account.
E. Provision an Azure Cosmos DB account with the Azure Table API. Enable multi-region writes.
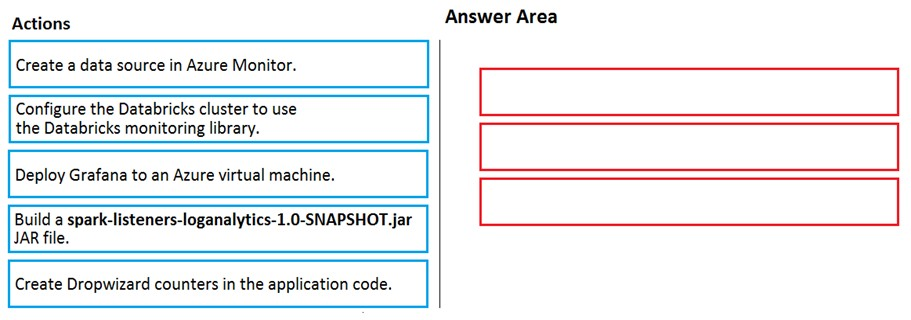
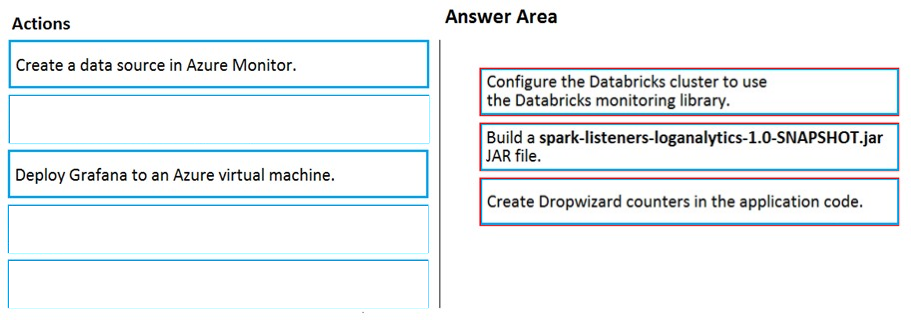
DRAG DROP - Your company analyzes images from security cameras and sends alerts to security teams that respond to unusual activity. The solution uses Azure Databricks. You need to send Apache Spark level events, Spark Structured Streaming metrics, and application metrics to Azure Monitor. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions in the answer area and arrange them in the correct order. Select and Place:
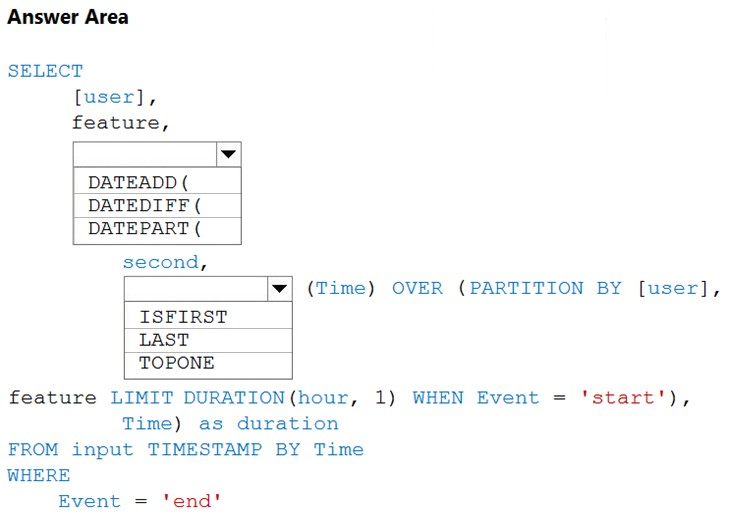
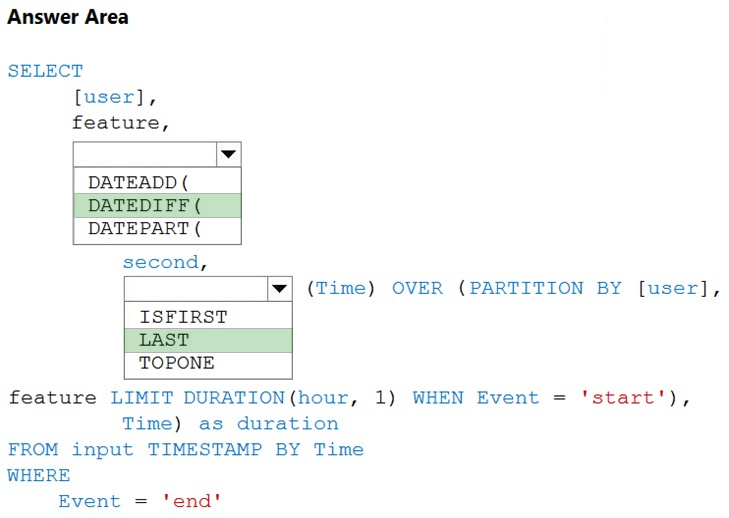
HOTSPOT - You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a webpage. The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has a type of either 'start' or 'end'. You need to calculate the duration between start and end events. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have an enterprise data warehouse in Azure Synapse Analytics. You need to monitor the data warehouse to identify whether you must scale up to a higher service level to accommodate the current workloads. Which is the best metric to monitor? More than one answer choice may achieve the goal. Select the BEST answer.
A. CPU percentage
B. DWU used
C. DWU percentage
D. Data IO percentage
HOTSPOT - A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row. You need to create the input stream. How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


What should you include in the Data Factory pipeline for Race Central?
A. a copy activity that uses a stored procedure as a source
B. a copy activity that contains schema mappings
C. a delete activity that has logging enabled
D. a filter activity that has a condition
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You have an Azure Synapse Analytics dedicated SQL pool that contains the users shown in the following table.User1 executes a query on the database, and the query returns the results shown in the following exhibit.
User1 is the only user who has access to the unmasked data. Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure SQL database named DB1 that contains a table named Table1. Table1 has a field named Customer_ID that is varchar(22). You need to implement masking for the Customer_ID field to meet the following requirements: ✑ The first two prefix characters must be exposed. ✑ The last four suffix characters must be exposed. ✑ All other characters must be masked. Solution: You implement data masking and use a random number function mask. Does this meet the goal?
A. Yes
B. No
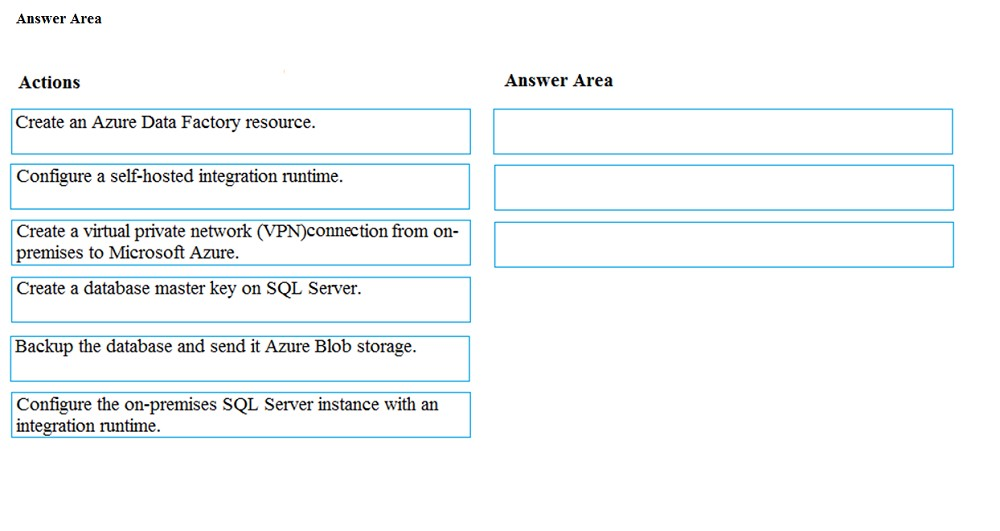
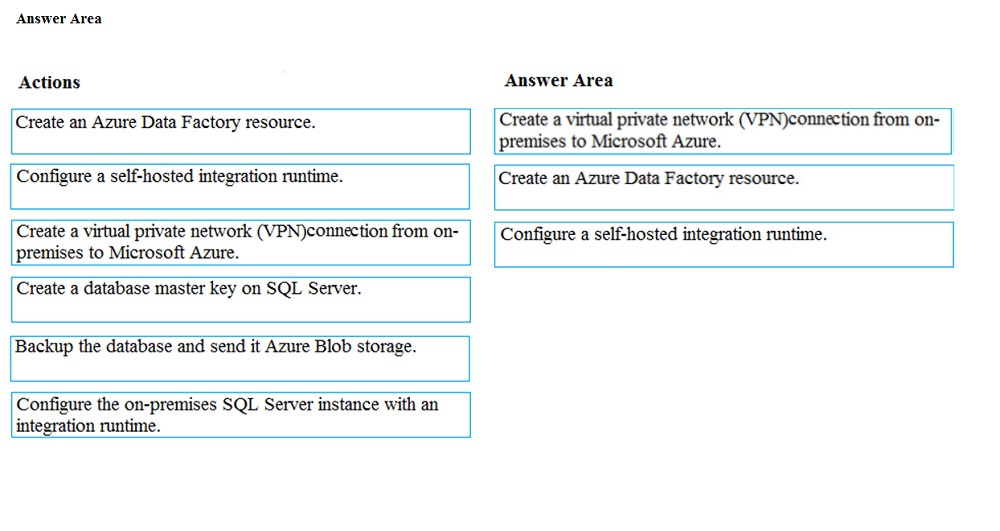
DRAG DROP - You need to replace the SSIS process by using Data Factory. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

HOTSPOT - You need to implement an Azure Databricks cluster that automatically connects to Azure Data Lake Storage Gen2 by using Azure Active Directory (Azure AD) integration. How should you configure the new cluster? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


Your company manages a payroll application for its customers worldwide. The application uses an Azure SQL database named DB1. The database contains a table named Employee and an identity column named EmployeeId. A customer requests the EmployeeId be treated as sensitive data. Whenever a user queries EmployeeId, you need to return a random value between 1 and 10 instead of the EmployeeId value. Which masking format should you use?
A. string
B. number
C. default
Free Access Full DP-200 Practice Questions Free
Want more hands-on practice? Click here to access the full bank of DP-200 practice questions free and reinforce your understanding of all exam objectives.
We update our question sets regularly, so check back often for new and relevant content.
Good luck with your DP-200 certification journey!