

DP-200 Mock Test Free – 50 Realistic Questions to Prepare with Confidence.
Getting ready for your DP-200 certification exam? Start your preparation the smart way with our DP-200 Mock Test Free – a carefully crafted set of 50 realistic, exam-style questions to help you practice effectively and boost your confidence.
Using a mock test free for DP-200 exam is one of the best ways to:
- Familiarize yourself with the actual exam format and question style
- Identify areas where you need more review
- Strengthen your time management and test-taking strategy
Below, you will find 50 free questions from our DP-200 Mock Test Free resource. These questions are structured to reflect the real exam’s difficulty and content areas, helping you assess your readiness accurately.
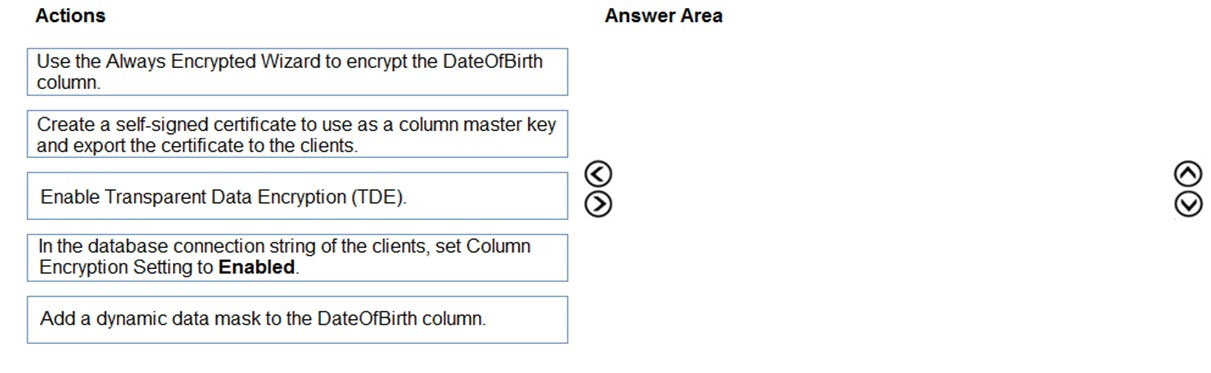
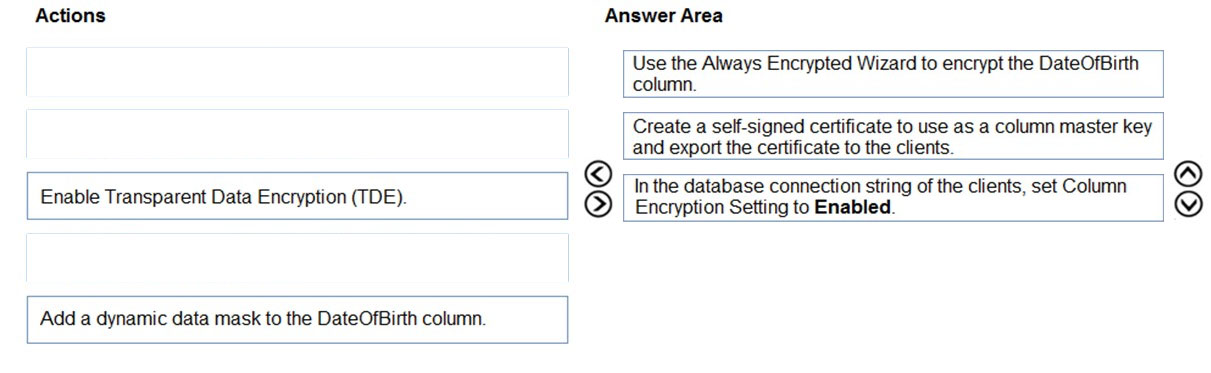
DRAG DROP - You have an ASP.NET web app that uses an Azure SQL database. The database contains a table named Employee. The table contains sensitive employee information, including a column named DateOfBirth. You need to ensure that the data in the DateOfBirth column is encrypted both in the database and when transmitted between a client and Azure. Only authorized clients must be able to view the data in the column. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions in the answer area and arrange them in the correct order. Select and Place:
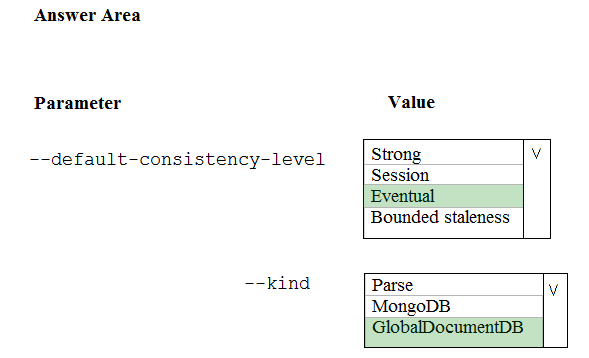
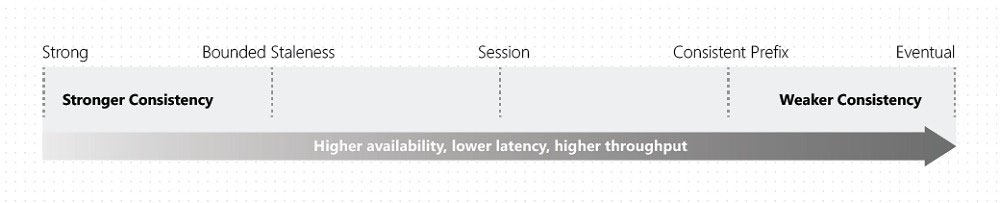
HOTSPOT - A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command: az cosmosdb create -`"name "cosmosdbdev1" `"-resource-group "rgdev" You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

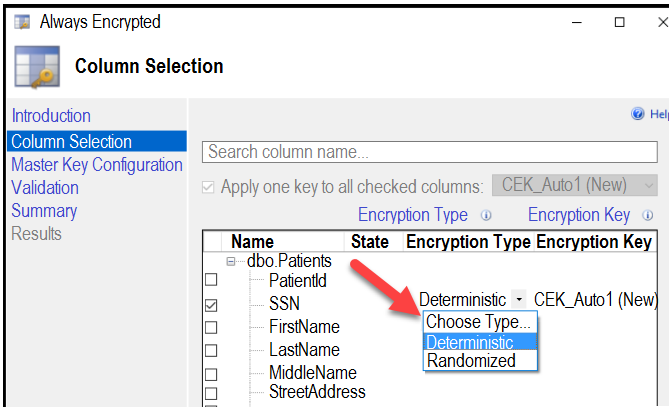
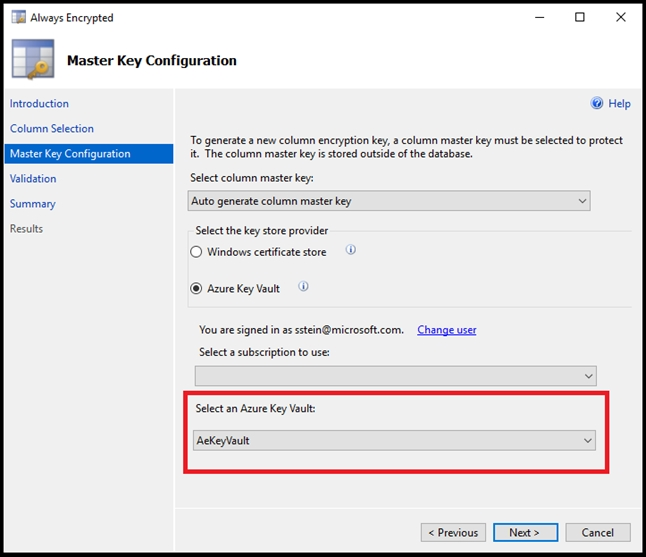
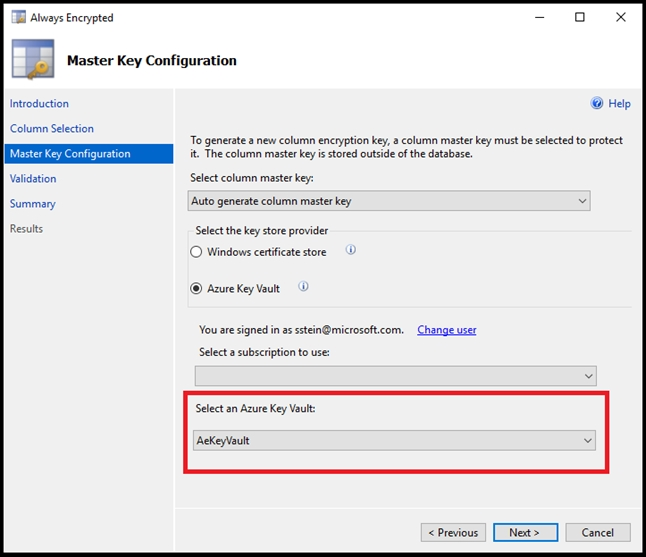
Overview - XYZ is an online training provider. Current Environment - The company currently has Microsoft SQL databases that are split into different categories or tiers. Some of the databases are used by Internal users, some by external partners and external distributions. Below is the List of applications, tiers and their individual requirements:Below are the current requirements of the company: * For Tier 4 and Tier 5 databases, the backup strategy must include the following: - Transactional log backup every hour - Differential backup every day - Full backup every week * Backup strategies must be in place for all standalone Azure SQL databases using methods available with Azure SQL databases * Tier 1 database must implement the following data masking logic: - For Data type XYZ-A `" Mask 4 or less string data type characters - For Data type XYZ-B `" Expose the first letter and mask the domain - For Data type XYZ-C `" Mask everything except characters at the beginning and the end * All certificates and keys are internally managed in on-premise data stores * For Tier 2 databases, if there are any conflicts between the data transfer from on-premise, preference should be given to on-premise data. * Monitoring must be setup on every database * Applications with Tiers 6 through 8 must ensure that unexpected resource storage usage is immediately reported to IT data engineers. * Azure SQL Data warehouse would be used to gather data from multiple internal and external databases. * The Azure SQL Data warehouse must be optimized to use data from its cache * The below metrics must be available when it comes to the cache: - Metric XYZ-A `" Low cache hit %, high cache usage % - Metric XYZ-B `" Low cache hit %, low cache usage % - Metric XYZ-C `" high cache hit %, high cache usage % * The reporting data for external partners must be stored in Azure storage. The data should be made available during regular business hours in connecting regions. * The reporting for Tier 9 needs to be moved to Event Hubs. * The reporting for Tier 10 needs to be moved to Azure Blobs. The following issues have been identified in the setup: * The External partners have control over the data formats, types and schemas. * For External based clients, the queries can't be changed or optimized. * The database development staff are familiar with T-SQL language. * Because of the size and amount of data, some applications and reporting features are not performing at SLA levels. The data for the external applications needs to be encrypted at rest. You decide to implement the following steps: - Use the Always Encrypted Wizard in SQL Server Management Studio - Select the column that needs to be encrypted - Set the encryption type to Randomized - Configure the master key to be used from the Windows Certificate Store - Confirm the configuration and deploy the solution Would these steps fulfill the requirement?
A. Yes
B. No
You have to deploy resources on Azure HDInsight for a batch processing job. The batch processing must run daily and must scale to minimize costs. You also be able to monitor cluster performance. You need to decide on a tool that will monitor the clusters and provide information on suggestions on how to scale. You decide on monitoring the cluster load by using the Ambari Web UI. Would this fulfill the requirement?
A. Yes
B. No

You create an Azure Databricks cluster and specify an additional library to install. When you attempt to load the library to a notebook, the library is not found. You need to identify the cause of the issue. What should you review?
A. workspace logs
B. notebook logs
C. global init scripts logs
D. cluster event logs
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You need to configure data encryption for external applications. Solution: 1. Access the Always Encrypted Wizard in SQL Server Management Studio 2. Select the column to be encrypted 3. Set the encryption type to Randomized 4. Configure the master key to use the Windows Certificate Store 5. Validate configuration results and deploy the solution Does the solution meet the goal?
A. Yes
B. No
You plan to perform batch processing in Azure Databricks once daily. Which type of Databricks cluster should you use?
A. automated
B. interactive
C. High Concurrency
A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU). You need to optimize performance for the Azure Stream Analytics job. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Implement event ordering
B. Scale the SU count for the job up
C. Implement Azure Stream Analytics user-defined functions (UDF)
D. Scale the SU count for the job down
E. Implement query parallelization by partitioning the data output
F. Implement query parallelization by partitioning the data input
DRAG DROP - You implement an event processing solution using Microsoft Azure Stream Analytics. The solution must meet the following requirements: ✑ Ingest data from Blob storage ✑ Analyze data in real time ✑ Store processed data in Azure Cosmos DB Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
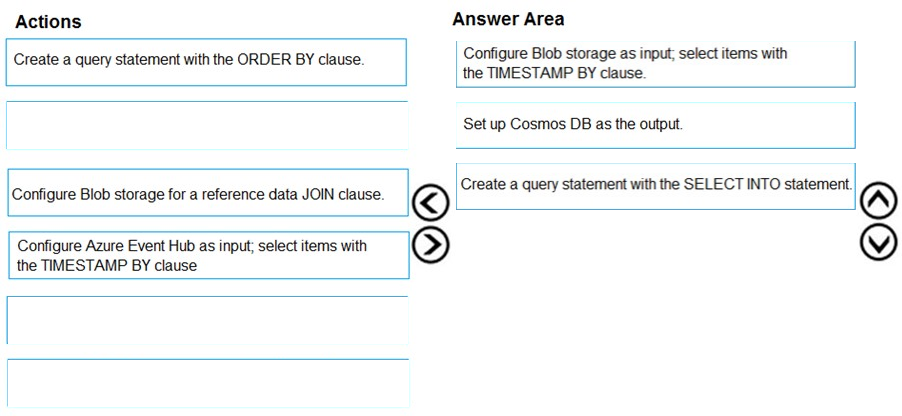
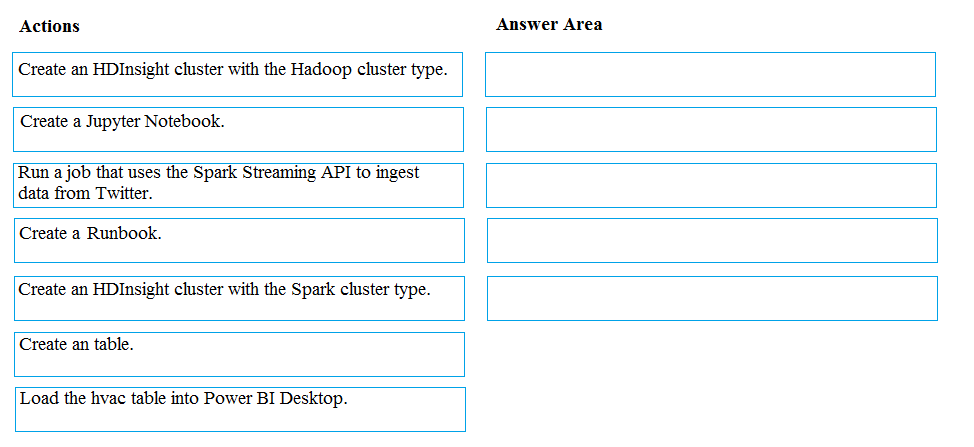
DRAG DROP - You develop data engineering solutions for a company. A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution. Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

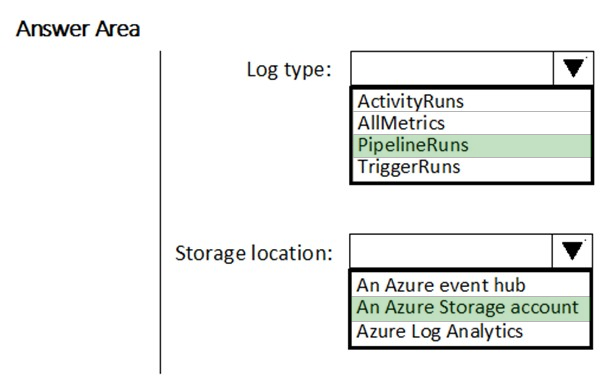
HOTSPOT - You have a new Azure Data Factory environment. You need to periodically analyze pipeline executions from the last 60 days to identify trends in execution durations. The solution must use Azure Log Analytics to query the data and create charts. Which diagnostic settings should you configure in Data Factory? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
A company has an Azure SQL data warehouse. They want to use PolyBase to retrieve data from an Azure Blob storage account and ingest into the Azure SQL data warehouse. The files are stored in parquet format. The data needs to be loaded into a table called XYZ_sales. Which of the following actions need to be performed to implement this requirement? (Choose four.)
A. Create an external file format that would map to the parquet-based files
B. Load the data into a staging table
C. Create an external table called XYZ_sales_details
D. Create an external data source for the Azure Blob storage account
E. Create a master key on the database
F. Configure Polybase to use the Azure Blob storage account
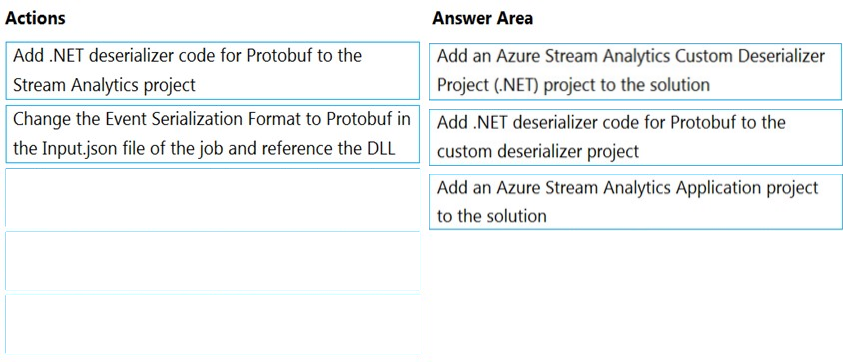
DRAG DROP - You have an Azure Stream Analytics job that is a Stream Analytics project solution in Microsoft Visual Studio. The job accepts data generated by IoT devices in the JSON format. You need to modify the job to accept data generated by the IoT devices in the Protobuf format. Which three actions should you perform from Visual Studio in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure Data Lake Gen 2 storage account 2. Create an external file format and external table using the external data source 3. Load the data using the CREATE TABLE AS SELECT statement Does the solution meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You create a lookup collection that uses ProductName as a partition key. Does this meet the goal?
A. Yes
B. No
HOTSPOT - You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct selection is worth one point. Hot Area:


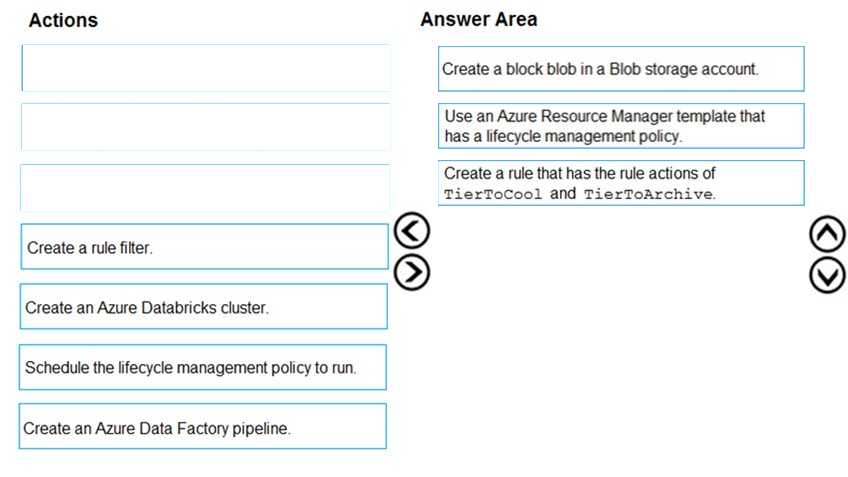
DRAG DROP - You are implementing an Azure Blob storage account for an application that has the following requirements: ✑ Data created during the last 12 months must be readily accessible. ✑ Blobs older than 24 months must use the lowest storage costs. This data will be accessed infrequently. ✑ Data created 12 to 24 months ago will be accessed infrequently but must be readily accessible at the lowest storage costs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You implement an enterprise data warehouse in Azure Synapse Analytics. You have a large fact table that is 10 terabytes (TB) in size. Incoming queries use the primary key Sale Key column to retrieve data as displayed in the following table:You need to distribute the large fact table across multiple nodes to optimize performance of the table. Which technology should you use?
A. hash distributed table with clustered ColumnStore index
B. hash distributed table with clustered index
C. heap table with distribution replicate
D. round robin distributed table with clustered index
E. round robin distributed table with clustered ColumnStore index
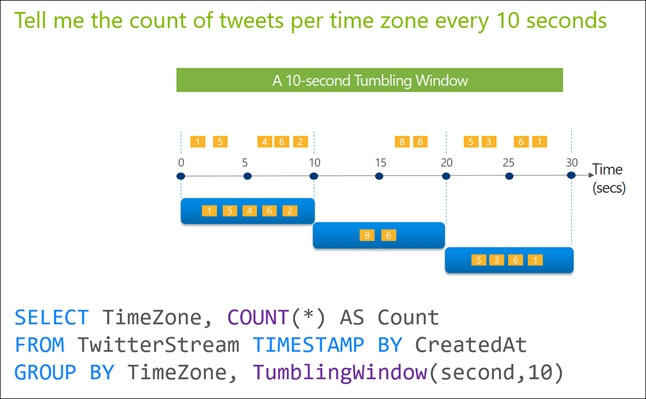
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account. You need to output the count of tweets during the last five minutes every five minutes. Each tweet must only be counted once. Which windowing function should you use?
A. a five-minute Sliding window
B. a five-minute Session window
C. a five-minute Tumbling window
D. a five-minute Hopping window that has a one-minute hop
You have a data warehouse in Azure Synapse Analytics. You need to ensure that the data in the data warehouse is encrypted at rest. What should you enable?
A. Transparent Data Encryption (TDE)
B. Secure transfer required
C. Always Encrypted for all columns
D. Advanced Data Security for this database
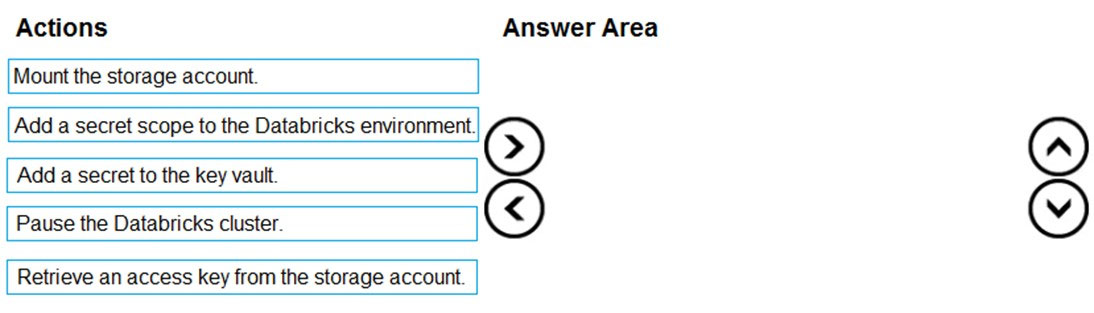
DRAG DROP - You have an Azure subscription that contains an Azure Databricks environment and an Azure Storage account. You need to implement secure communication between Databricks and the storage account. You create an Azure key vault. Which four actions should you perform in sequence? To answer, move the actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure storage account 2. Create a workload group using the Azure storage account name as the pool name 3. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
A company plans to use Azure Storage for file storage purposes. Compliance rules require: ✑ A single storage account to store all operations including reads, writes and deletes ✑ Retention of an on-premises copy of historical operations You need to configure the storage account. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Configure the storage account to log read, write and delete operations for service type Blob
B. Use the AzCopy tool to download log data from $logs/blob
C. Configure the storage account to log read, write and delete operations for service-type table
D. Use the storage client to download log data from $logs/table
E. Configure the storage account to log read, write and delete operations for service type queue
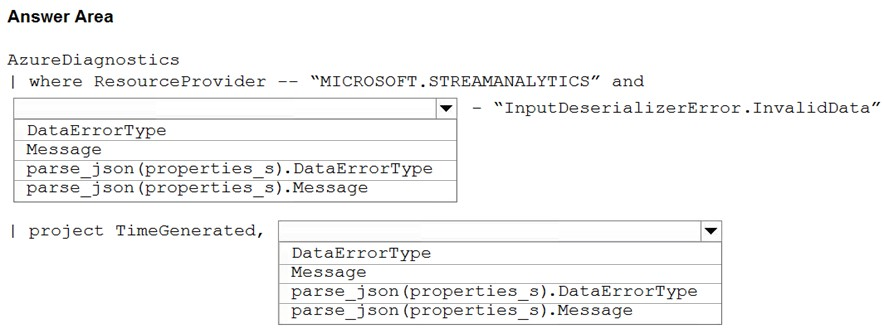
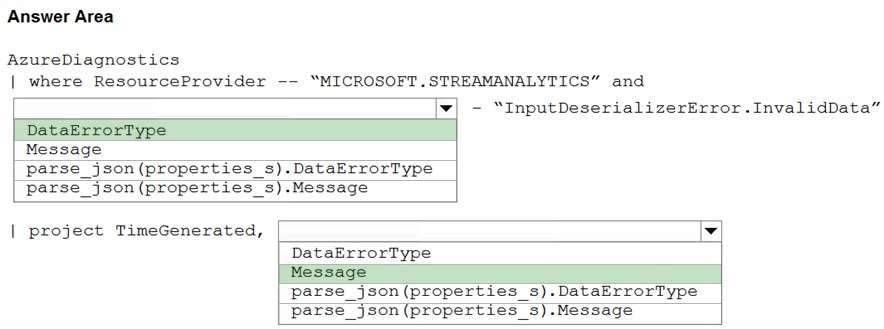
HOTSPOT - You have an Azure Stream Analytics job named ASA1. The Diagnostic settings for ASA1 are configured to write errors to Log Analytics. ASA1 reports an error, and the following message is sent to Log Analytics.You need to write a Kusto query language query to identify all instances of the error and return the message field. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
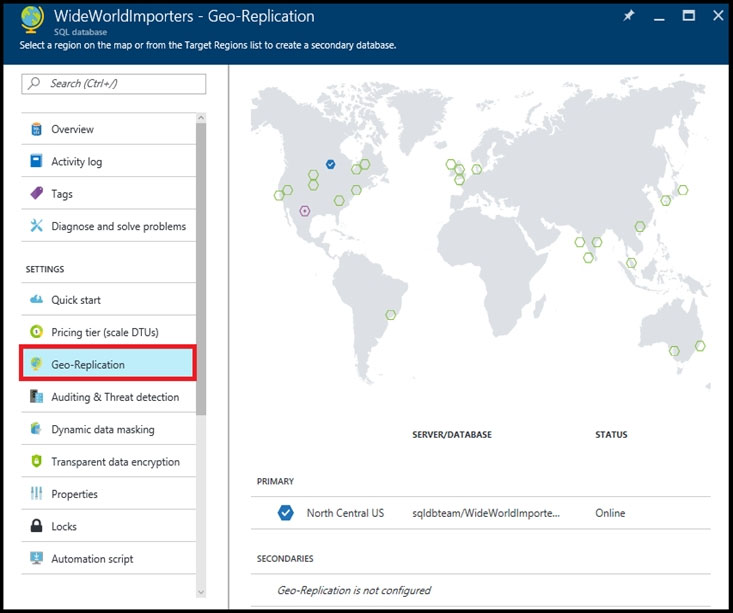
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You need to replicate db1 to a new Azure SQL server named REPL10277521 in the Central Canada region. To complete this task, sign in to the Azure portal. NOTE: This task might take several minutes to complete. You can perform other tasks while the task completes or ends this section of the exam. To complete this task, sign in to the Azure portal.
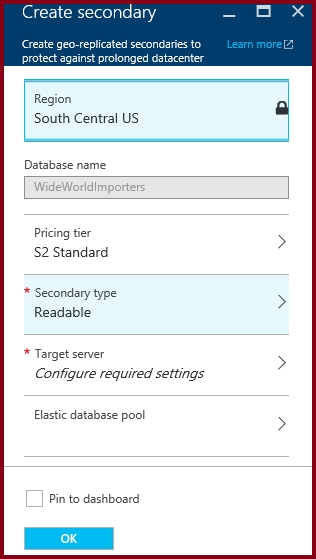
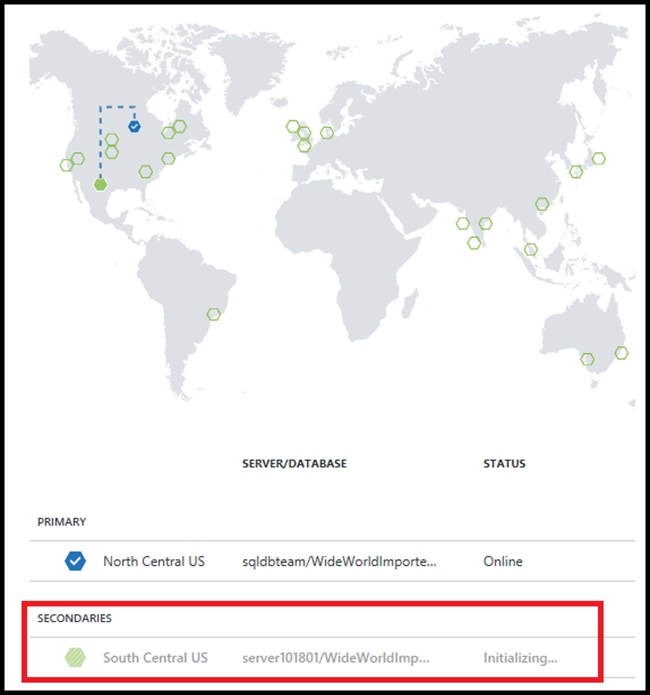
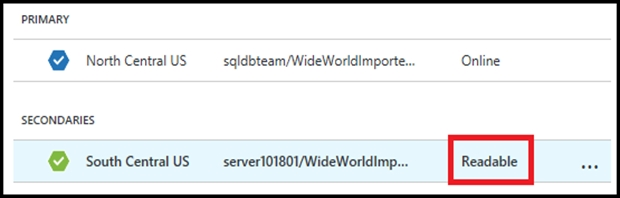
DRAG DROP - You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections. Each region maintains its own private virtual network. Building the sales projections is very resource intensive and generates upwards of 20 terabytes (TB) of data. Microsoft Azure SQL Databases must be provisioned. ✑ Database provisioning must maximize performance and minimize cost ✑ The daily sales for each region must be stored in an Azure SQL Database instance ✑ Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance You need to provision Azure SQL database instances. How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
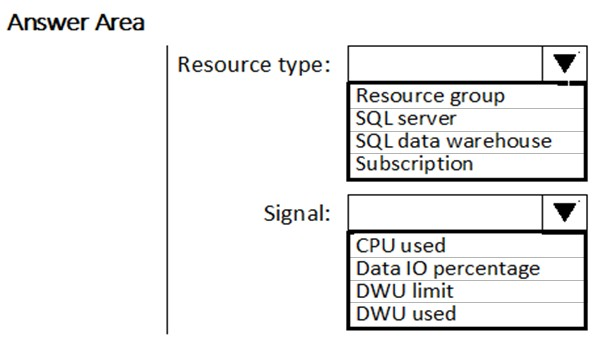
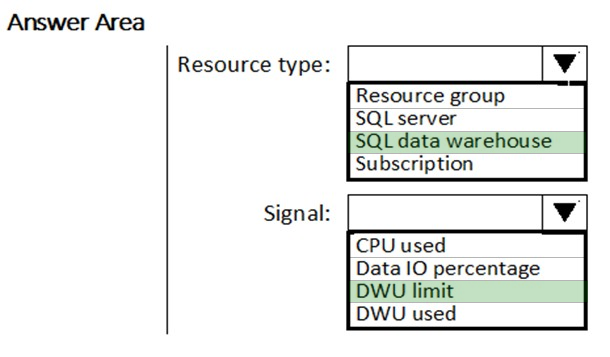
HOTSPOT - You need to receive an alert when Azure Synapse Analytics consumes the maximum allotted resources. Which resource type and signal should you use to create the alert in Azure Monitor? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
What should you implement to optimize SQL Database for Race Central to meet the technical requirements?
A. the sp_update_stats stored procedure
B. automatic tuning
C. Query Store
D. the dbcc checkdb command
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You need to configure data encryption for external applications. Solution: 1. Access the Always Encrypted Wizard in SQL Server Management Studio 2. Select the column to be encrypted 3. Set the encryption type to Deterministic 4. Configure the master key to use the Windows Certificate Store 5. Validate configuration results and deploy the solution Does the solution meet the goal?
A. Yes
B. No
You are monitoring the Data Factory pipeline that runs from Cosmos DB to SQL Database for Race Central. You discover that the job takes 45 minutes to run. What should you do to improve the performance of the job?
A. Decrease parallelism for the copy activities.
B. Increase that data integration units.
C. Configure the copy activities to use staged copy.
D. Configure the copy activities to perform compression.
Your company uses several Azure HDInsight clusters. The data engineering team reports several errors with some applications using these clusters. You need to recommend a solution to review the health of the clusters. What should you include in your recommendation?
A. Azure Automation
B. Log Analytics
C. Application Insights
You need to develop a pipeline for processing data. The pipeline must meet the following requirements: ✑ Scale up and down resources for cost reduction ✑ Use an in-memory data processing engine to speed up ETL and machine learning operations. ✑ Use streaming capabilities ✑ Provide the ability to code in SQL, Python, Scala, and R Integrate workspace collaboration with GitWhat should you use?
A. HDInsight Spark Cluster
B. Azure Stream Analytics
C. HDInsight Hadoop Cluster
D. Azure SQL Data Warehouse
E. HDInsight Kafka Cluster
F. HDInsight Storm Cluster
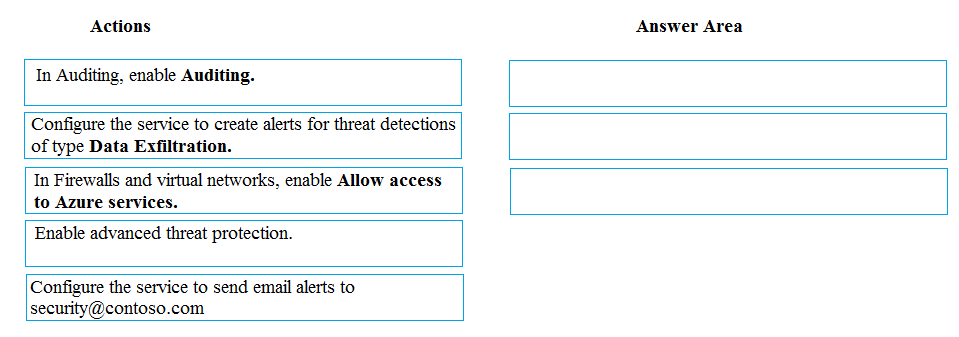
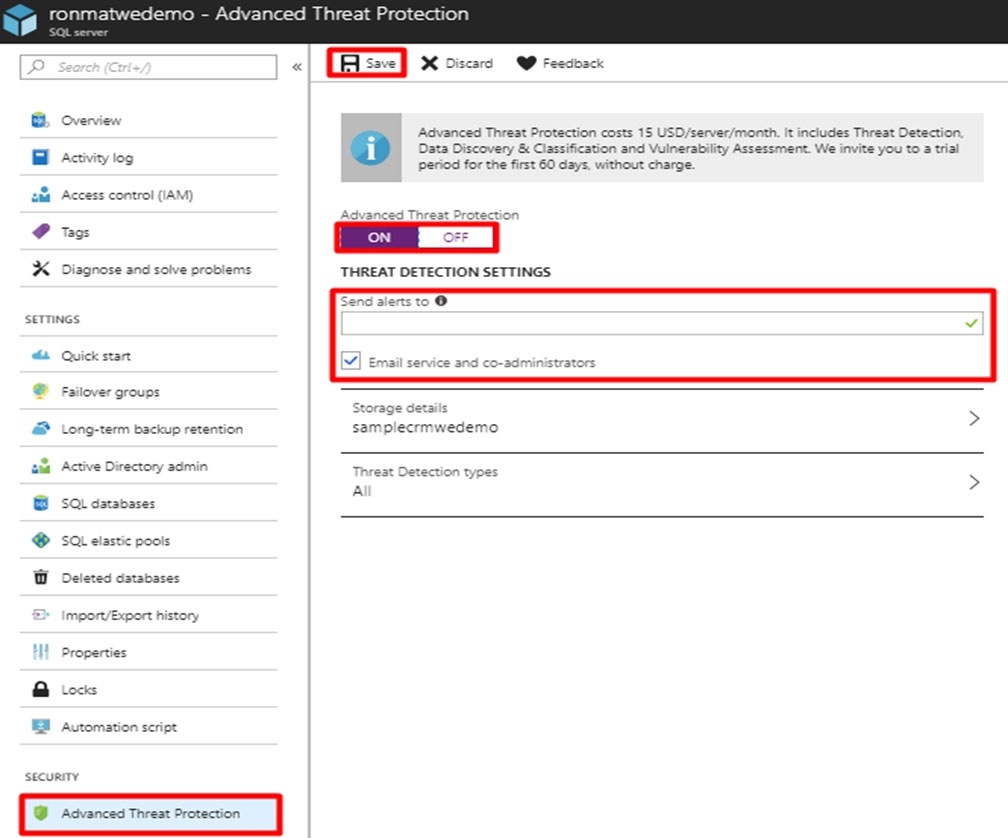
DRAG DROP - A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations. You must monitor data usage, and data copied from the system to prevent data leakage. You need to configure Azure SQL Database to email a specific user when data leakage occurs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

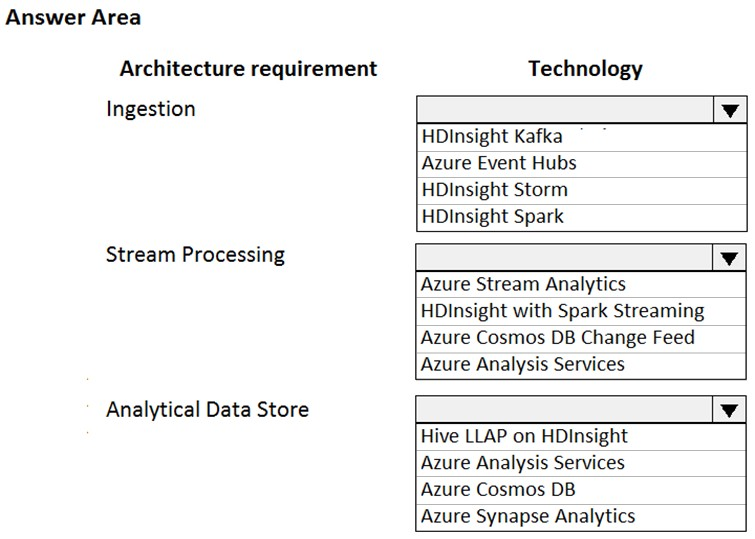
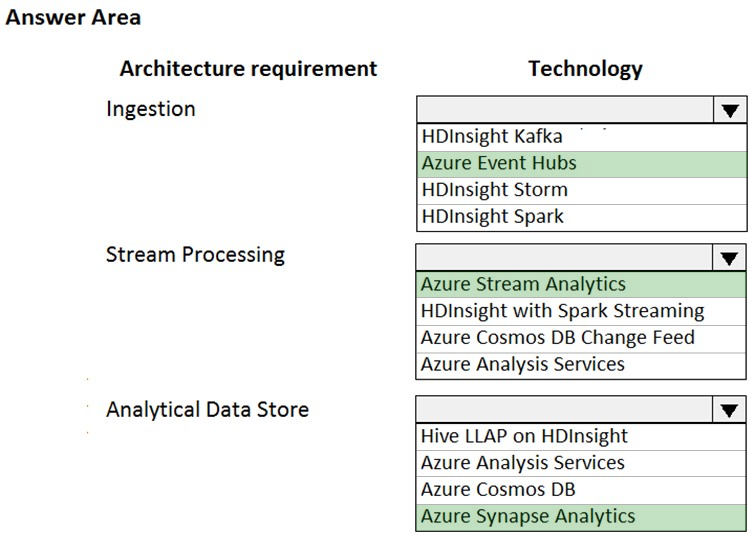
HOTSPOT - You are designing a new Lambda architecture on Microsoft Azure. The real-time processing layer must meet the following requirements: Ingestion: ✑ Receive millions of events per second ✑ Act as a fully managed Platform-as-a-Service (PaaS) solution ✑ Integrate with Azure Functions Stream processing: ✑ Process on a per-job basis ✑ Provide seamless connectivity with Azure services ✑ Use a SQL-based query language Analytical data store: ✑ Act as a managed service ✑ Use a document store ✑ Provide data encryption at rest You need to identify the correct technologies to build the Lambda architecture using minimal effort. Which technologies should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have an enterprise data warehouse in Azure Synapse Analytics. Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse. The external table has three columns. You discover that the Parquet files have a fourth column named ItemID. Which command should you run to add the ItemID column to the external table?

A. Option A
B. Option B
C. Option C
D. Option D
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address. You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes. You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention. Solution: You implement a Stream Analytics job that has one streaming input, one reference input, two queries, and four outputs. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a High Concurrency cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
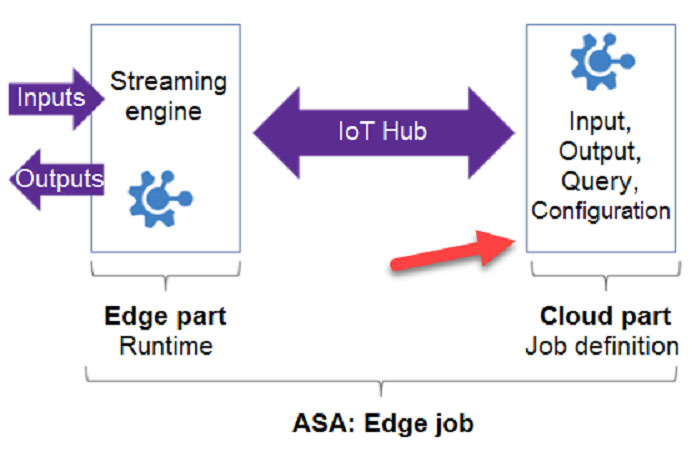
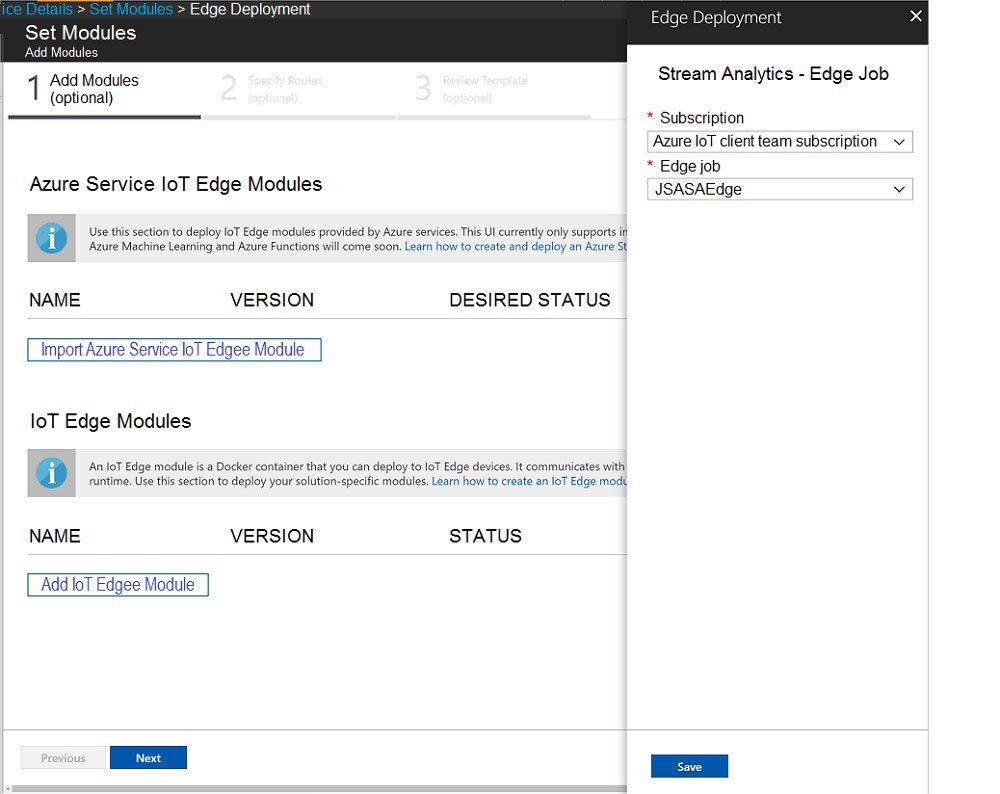
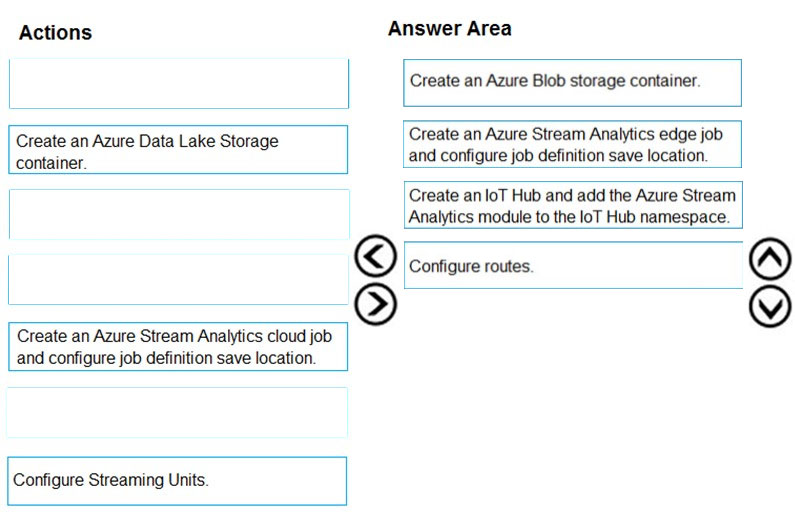
You need to deploy a Microsoft Azure Stream Analytics job for an IoT based solution. The solution must minimize latency. The solution must also minimize the bandwidth usage between the job and the IoT device. Which of the following actions must you perform for this requirement? (Choose four.)
A. Ensure to configure routes
B. Create an Azure Blob storage container
C. Configure Streaming Units
D. Create an IoT Hub and add the Azure Stream Analytics modules to the IoT Hub namespace
E. Create an Azure Stream Analytics edge job and configure job definition save location
F. Create an Azure Stream Analytics cloud job and configure job definition save location

HOTSPOT - A company plans to develop solutions to perform batch processing of multiple sets of geospatial data. You need to implement the solutions. Which Azure services should you use? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have an Azure data factory. You need to examine the pipeline failures from the last 60 days. What should you use?
A. the Activity log blade for the Data Factory resource
B. Azure Monitor
C. the Monitor & Manage app in Data Factory
D. the Resource health blade for the Data Factory resource
You have an alert on a SQL pool in Azure Synapse that uses the signal logic shown in the exhibit.On the same day, failures occur at the following times: ✑ 08:01 ✑ 08:03 ✑ 08:04 ✑ 08:06 ✑ 08:11 ✑ 08:16 ✑ 08:19 The evaluation period starts on the hour. At which times will alert notifications be sent?
A. 08:15 only
B. 08:10, 08:15, and 08:20
C. 08:05 and 08:10 only
D. 08:10 only
E. 08:05 only
A company is designing a hybrid solution to synchronize data and on-premises Microsoft SQL Server database to Azure SQL Database. You must perform an assessment of databases to determine whether data will move without compatibility issues. You need to perform the assessment. Which tool should you use?
A. SQL Server Migration Assistant (SSMA)
B. Microsoft Assessment and Planning Toolkit
C. SQL Vulnerability Assessment (VA)
D. Azure SQL Data Sync
E. Data Migration Assistant (DMA)
You have a SQL pool in Azure Synapse. A user reports that queries against the pool take longer than expected to complete. You need to add monitoring to the underlying storage to help diagnose the issue. Which two metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Cache used percentage
B. DWU Limit
C. Snapshot Storage Size
D. Active queries
E. Cache hit percentage
You need to ensure that phone-based poling data can be analyzed in the PollingData database. How should you configure Azure Data Factory?
A. Use a tumbling schedule trigger
B. Use an event-based trigger
C. Use a schedule trigger
D. Use manual execution
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to generate large amounts of real-time data that will be copied to Azure Blob storage. You plan to create reports that will read the data from an Azure Cosmos DB database. You need to create an Azure Stream Analytics job that will input the data from a blob storage named storage10277521 to the Cosmos DB database. To complete this task, sign in to the Azure portal.
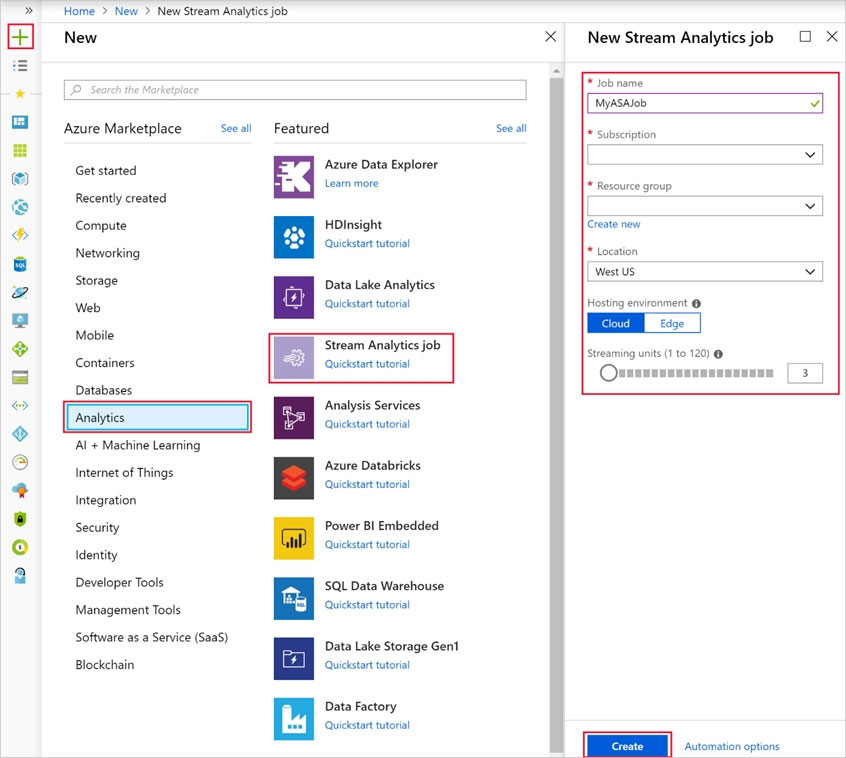
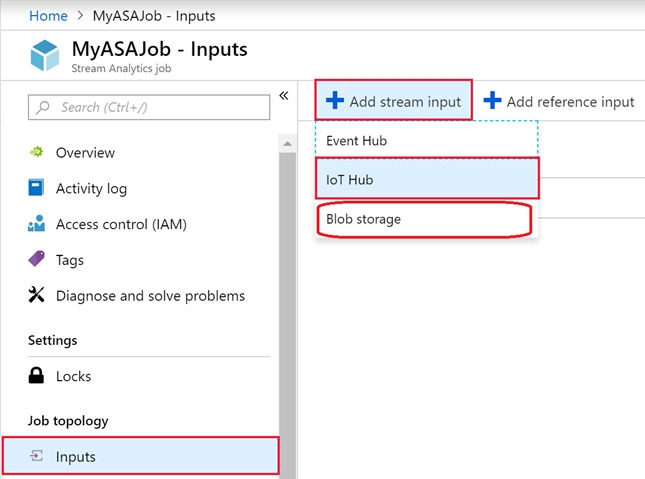
You develop data engineering solutions for a company. You need to ingest and visualize real-time Twitter data by using Microsoft Azure. Which three technologies should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Event Grid topic
B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
D. Logic App that sends Twitter posts which have target keywords to Azure
E. Event Grid subscription
F. Event Hub instance
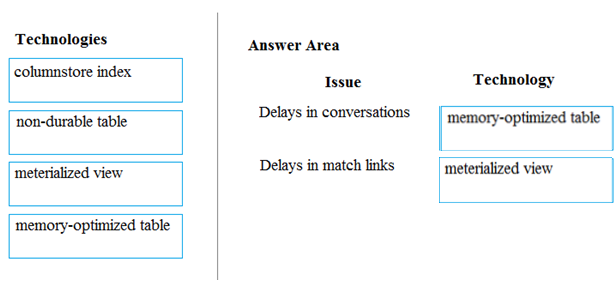
DRAG DROP - A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets. When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation. Customers report the following issues: ✑ Delays occur during live conversations ✑ A delay occurs before matching links appear after code snippets are added to conversations You need to resolve the performance issues. Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
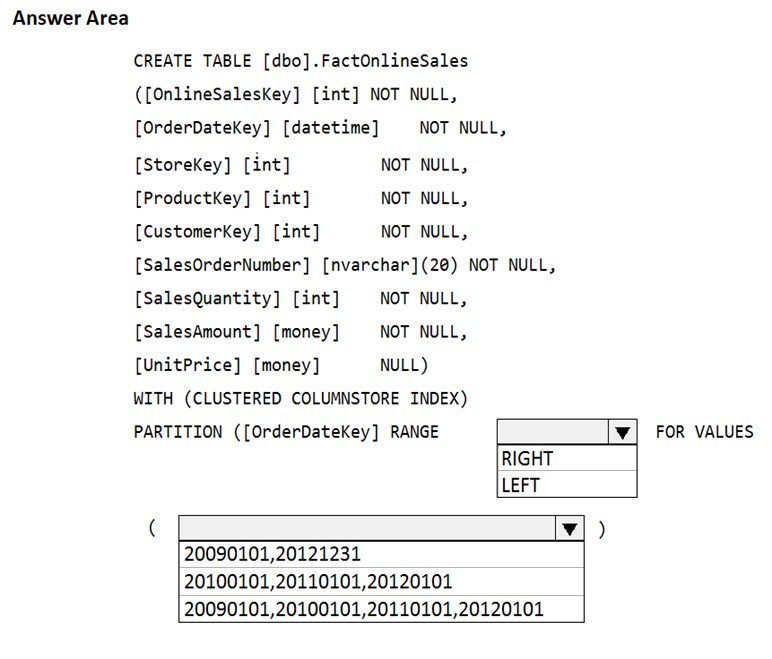
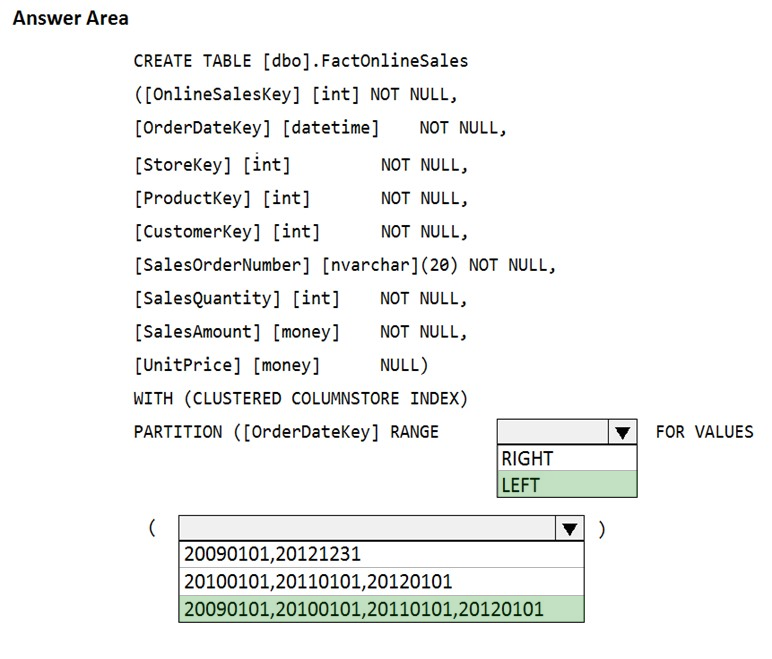
HOTSPOT - You have an enterprise data warehouse in Azure Synapse Analytics that contains a table named FactOnlineSales. The table contains data from the start of 2009 to the end of 2012. You need to improve the performance of queries against FactOnlineSales by using table partitions. The solution must meet the following requirements: ✑ Create four partitions based on the order date. ✑ Ensure that each partition contains all the orders placed during a given calendar year. How should you complete the T-SQL command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
DRAG DROP - You develop data engineering solutions for a company. You need to deploy a Microsoft Azure Stream Analytics job for an IoT solution. The solution must: ✑ Minimize latency. ✑ Minimize bandwidth usage between the job and IoT device. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

Access Full DP-200 Mock Test Free
Want a full-length mock test experience? Click here to unlock the complete DP-200 Mock Test Free set and get access to hundreds of additional practice questions covering all key topics.
We regularly update our question sets to stay aligned with the latest exam objectives—so check back often for fresh content!
Start practicing with our DP-200 mock test free today—and take a major step toward exam success!