

DP-200 Exam Prep Free – 50 Practice Questions to Get You Ready for Exam Day
Getting ready for the DP-200 certification? Our DP-200 Exam Prep Free resource includes 50 exam-style questions designed to help you practice effectively and feel confident on test day
Effective DP-200 exam prep free is the key to success. With our free practice questions, you can:
- Get familiar with exam format and question style
- Identify which topics you’ve mastered—and which need more review
- Boost your confidence and reduce exam anxiety
Below, you will find 50 realistic DP-200 Exam Prep Free questions that cover key exam topics. These questions are designed to reflect the structure and challenge level of the actual exam, making them perfect for your study routine.
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure storage account 2. Create an external file format and external table using the external data source 3. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
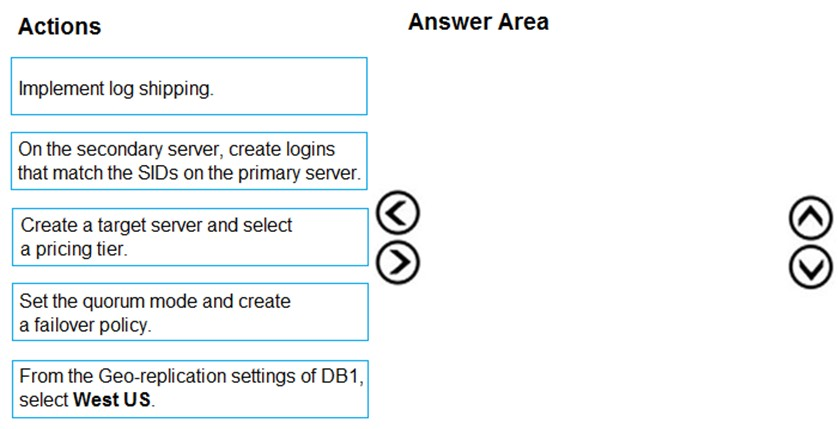
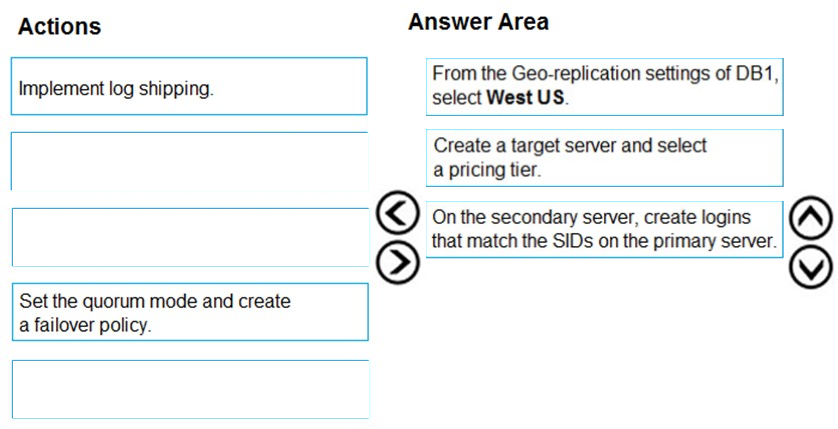
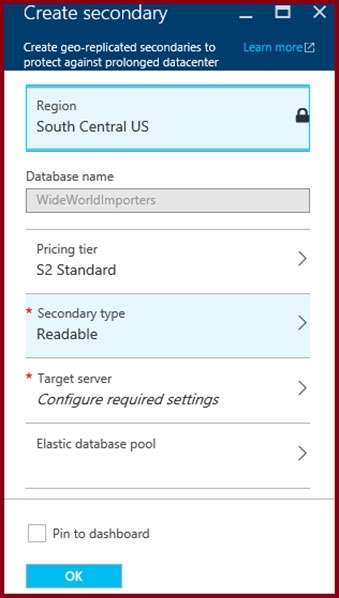
DRAG DROP - You have an Azure SQL database named DB1 in the East US 2 region. You need to build a secondary geo-replicated copy of DB1 in the West US region on a new server. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
You are designing an enterprise data warehouse in Azure Synapse Analytics. You plan to load millions of rows of data into the data warehouse each day. You must ensure that staging tables are optimized for data loading. You need to design the staging tables. What type of tables should you recommend?
A. Round-robin distributed table
B. Hash-distributed table
C. Replicated table
D. External table
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table. Which output mode should you use?
A. complete
B. update
C. append
HOTSPOT - You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You need to build a solution to collect the telemetry data for Race Central. What should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You need to implement complex stateful business logic within an Azure Stream Analytics service. Which type of function should you create in the Stream Analytics topology?
A. JavaScript user-define functions (UDFs)
B. Azure Machine Learning
C. JavaScript user-defined aggregates (UDA)
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a High Concurrency cluster for the jobs. Does this meet the goal?
A. Yes
B. No
HOTSPOT - You are implementing Azure Stream Analytics windowing functions. Which windowing function should you use for each requirement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


A company is designing a hybrid solution to synchronize data and on-premises Microsoft SQL Server database to Azure SQL Database. You must perform an assessment of databases to determine whether data will move without compatibility issues. You need to perform the assessment. Which tool should you use?
A. SQL Server Migration Assistant (SSMA)
B. Microsoft Assessment and Planning Toolkit
C. SQL Vulnerability Assessment (VA)
D. Azure SQL Data Sync
E. Data Migration Assistant (DMA)
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1. You need to verify whether the size of the transaction log file for each distribution of DW1 is smaller than 160 GB. What should you do?
A. On the master database, execute a query against the sys.dm_pdw_nodes_os_performance_counters dynamic management view.
B. From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
C. On DW1, execute a query against the sys.database_files dynamic management view.
D. Execute a query against the logs of DW1 by using the Get-AzOperationalInsightsSearchResult PowerShell cmdlet.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address. You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes. You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention. Solution: You implement a Stream Analytics job that has two streaming inputs, one query, and two outputs. Does this meet the goal?
A. Yes
B. No
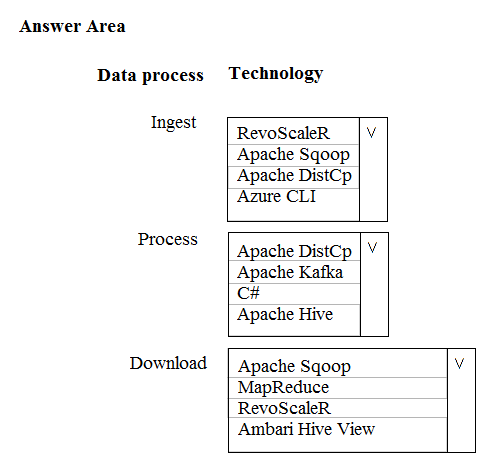
HOTSPOT - A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements: ✑ Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service ✑ Use an Azure Data Lake Storage account to store processed data ✑ Allow users to download processed data You need to recommend technologies for the solution. Which technologies should you use? To answer, select the appropriate options in the answer area. Hot Area:
You have a SQL pool in Azure Synapse. You discover that some queries fail or take a long time to complete. You need to monitor for transactions that have rolled back. Which dynamic management view should you query?
A. sys.dm_pdw_nodes_tran_database_transactions
B. sys.dm_pdw_waits
C. sys.dm_pdw_request_steps
D. sys.dm_pdw_exec_sessions
You have the Diagnostics settings of an Azure Storage account as shown in the following exhibit.How long will the logging data be retained?
A. 7 days
B. 365 days
C. indefinitely
D. 90 days
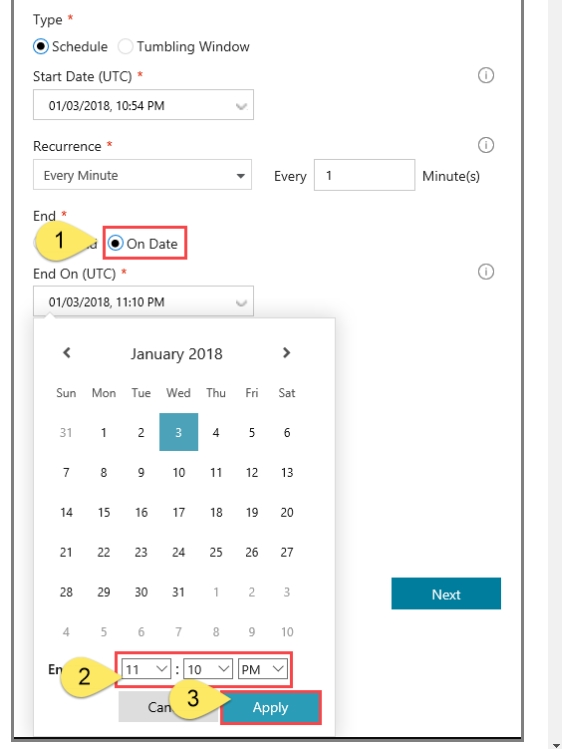
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to create multiple pipelines in a new Azure Data Factory V2. You need to create the data factory, and then create a scheduled trigger for the planned pipelines. The trigger must execute every two hours starting at 24:00:00. To complete this task, sign in to the Azure portal.
HOTSPOT - You need to implement an Azure Databricks cluster that automatically connects to Azure Data Lake Storage Gen2 by using Azure Active Directory (Azure AD) integration. How should you configure the new cluster? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have an Azure SQL server named Server1 that hosts two development databases named DB1 and DB2. You have an administrative workstation that has an IP address of 192.168.8.8. The development team at your company has an IP addresses in the range of 192.168.8.1 to 192.168.8.5. You need to set up firewall rules to meet the following requirements: ✑ Allows connection from your workstation to both databases. ✑ The development team must be able connect to DB1 but must be prevented from connecting to DB2. ✑ Web services running in Azure must be able to connect to DB1 but must be prevented from connecting to DB2. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create a firewall rule on DB1 that has a start IP address of 192.168.8.1 and an end IP address of 192.168.8.5.
B. Create a firewall rule on DB1 that has a start and end IP address of 0.0.0.0.
C. Create a firewall rule on Server1 that has a start IP address of 192.168.8.1 and an end IP address of 192.168.8.5.
D. Create a firewall rule on DB1 that has a start and end IP address of 192.168.8.8.
E. Create a firewall rule on Server1 that has a start and end IP address of 192.168.8.8.
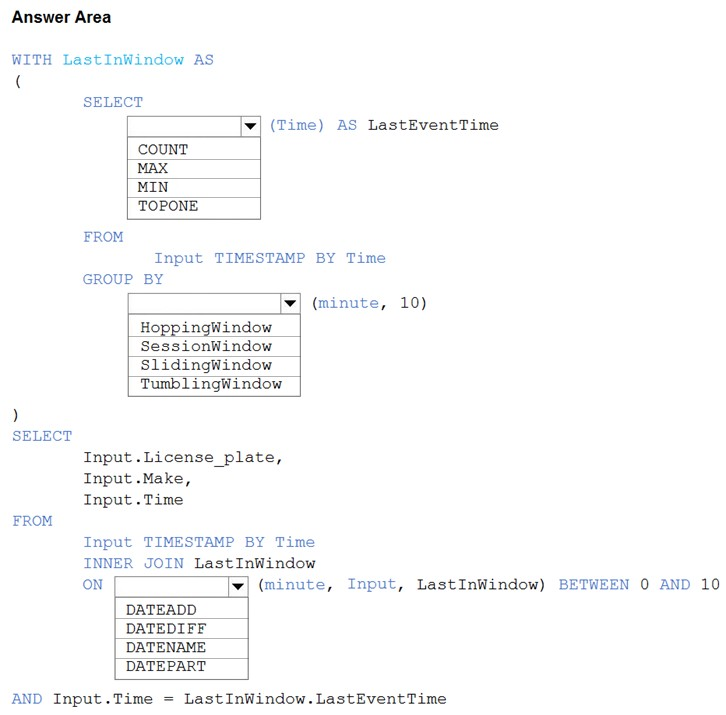
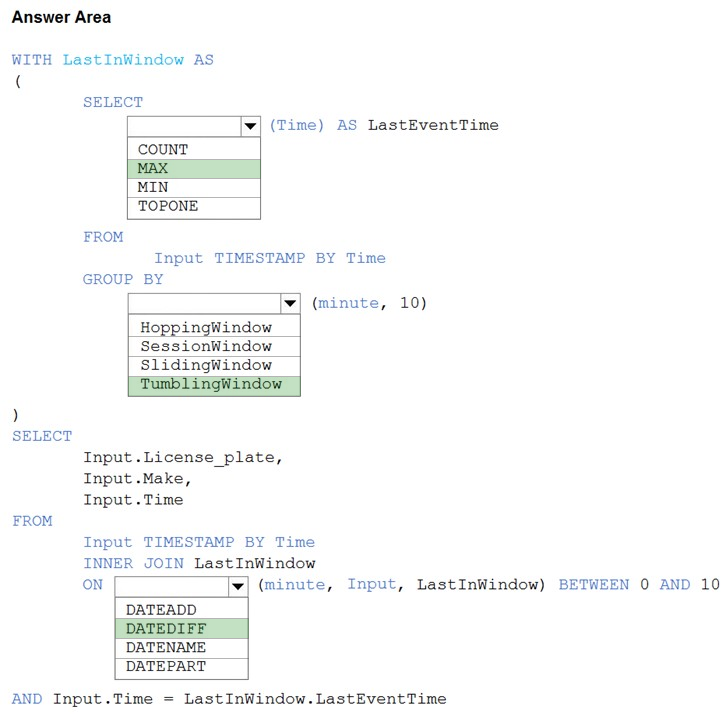
HOTSPOT - You are processing streaming data from vehicles that pass through a toll booth. You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
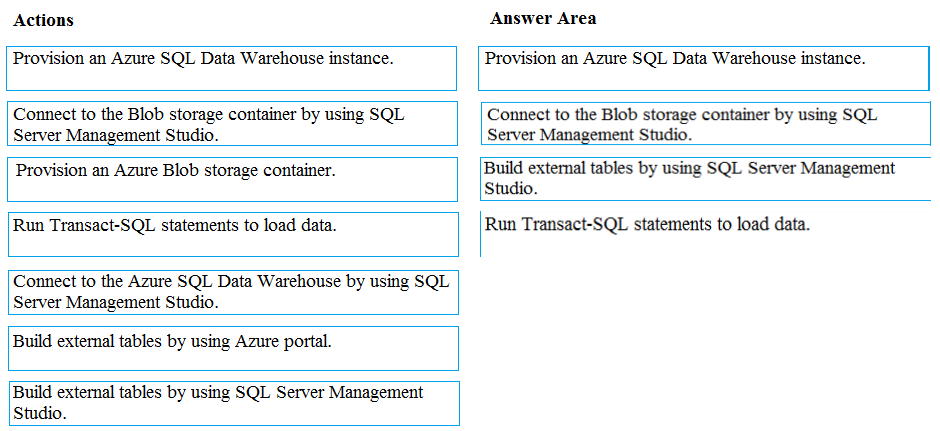
DRAG DROP - You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You create an Azure Databricks cluster and specify an additional library to install. When you attempt to load the library to a notebook, the library is not found. You need to identify the cause of the issue. What should you review?
A. workspace logs
B. notebook logs
C. global init scripts logs
D. cluster event logs
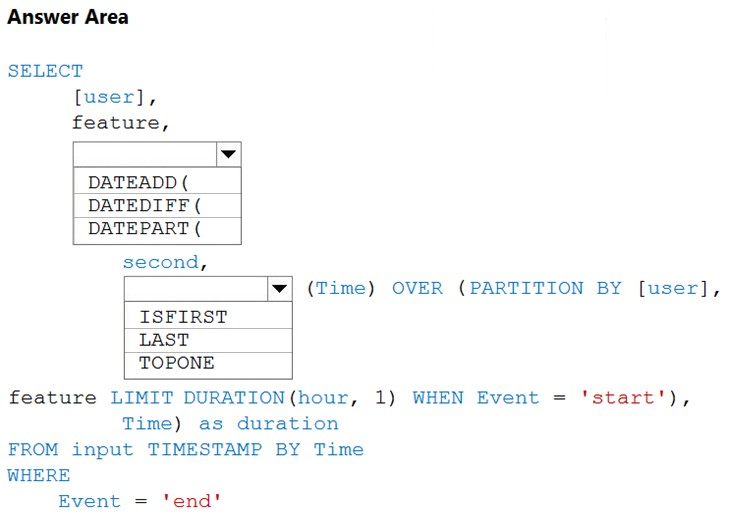
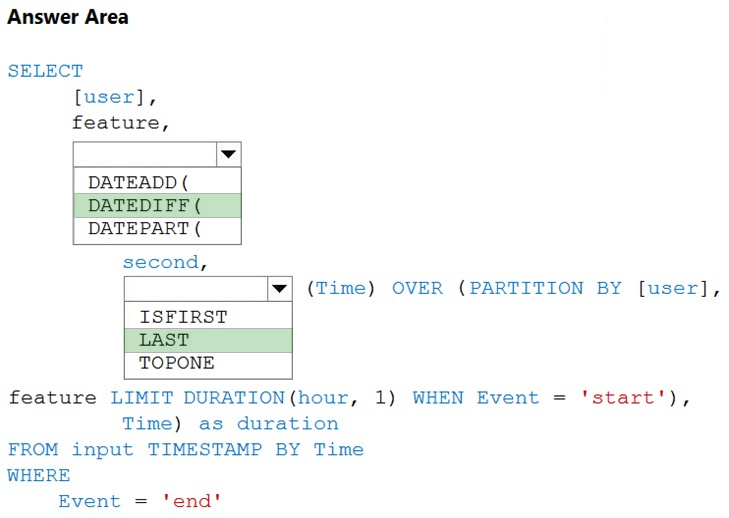
HOTSPOT - You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a webpage. The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has a type of either 'start' or 'end'. You need to calculate the duration between start and end events. How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
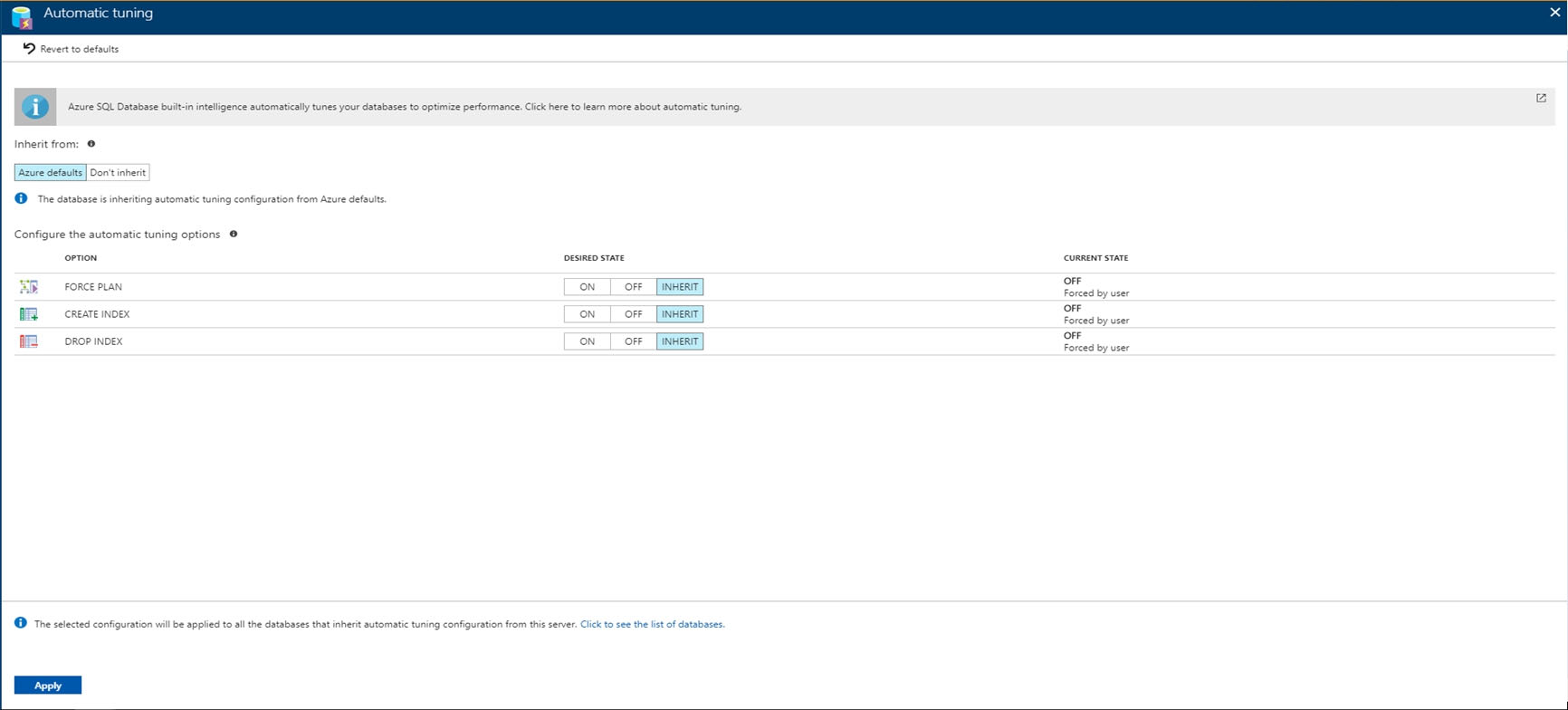
HOTSPOT - You are implementing automatic tuning mode for Azure SQL databases. Automatic tuning mode is configured as shown in the following table.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


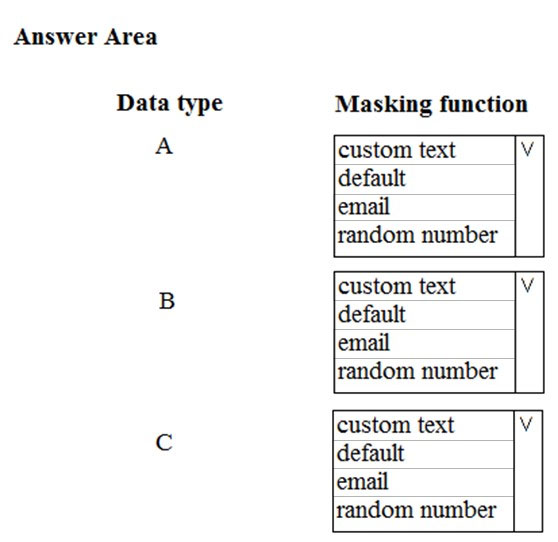
HOTSPOT - You need to mask tier 1 data. Which functions should you use? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

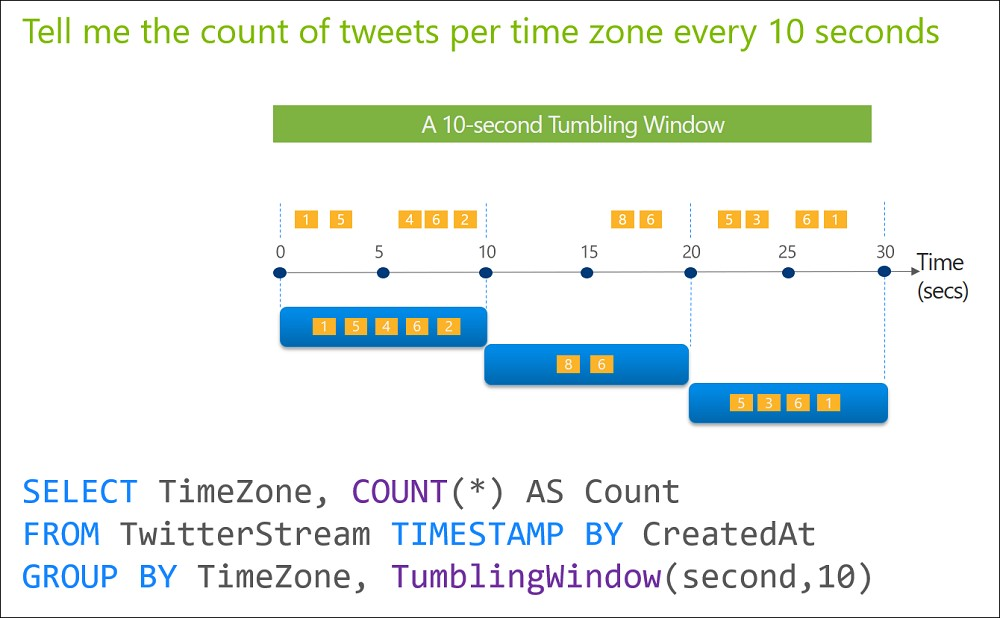
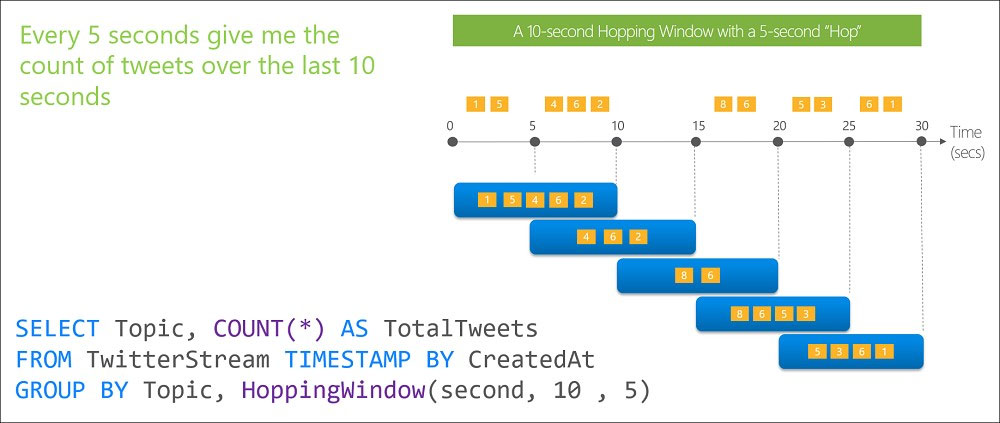
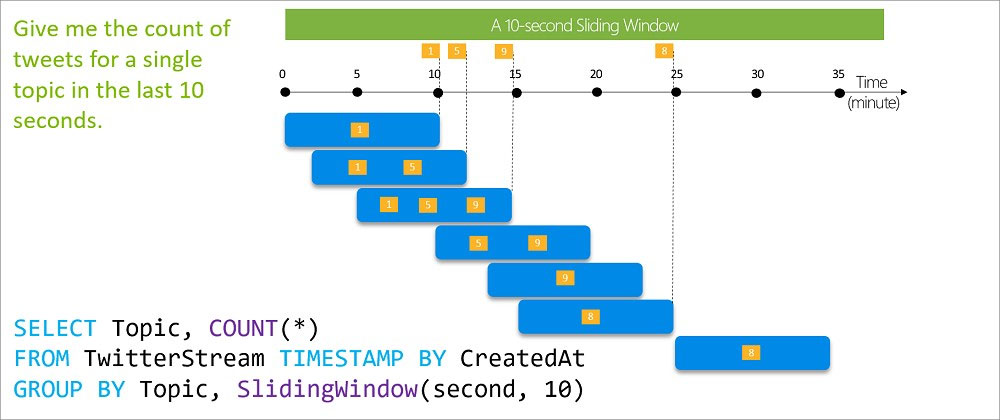
You have an Azure Stream Analytics job that receives clickstream data from an Azure event hub. You need to define a query in the Stream Analytics job. The query must meet the following requirements: ✑ Count the number of clicks within each 10-second window based on the country of a visitor. ✑ Ensure that each click is NOT counted more than once. How should you define the query?
A. SELECT Country, Count(*) AS Count FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, TumblingWindow(second, 10)
B. SELECT Country, Count(*) AS Count FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, SessionWindow(second, 5, 10)
C. SELECT Country, Avg(*) AS Average FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, SlidingWindow(second, 10)
D. SELECT Country, Avg(*) AS Average FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, HoppingWindow(second, 10, 2)
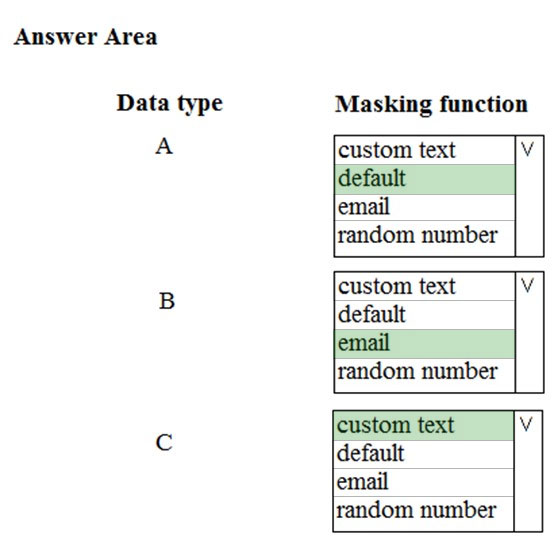
HOTSPOT - Which masking functions should you implement for each column to meet the data masking requirements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to create large data sets on db2. You need to ensure that missing indexes are created automatically by Azure in db2. The solution must apply ONLY to db2. To complete this task, sign in to the Azure portal.
HOTSPOT - You have a SQL pool in Azure Synapse. You plan to load data from Azure Blob storage to a staging table. Approximately 1 million rows of data will be loaded daily. The table will be truncated before each daily load. You need to create the staging table. The solution must minimize how long it takes to load the data to the staging table. How should you configure the table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You create a lookup collection that uses ProductName as a partition key and OrderId as a value. Does this meet the goal?
A. Yes
B. No
HOTSPOT - You have the following Azure Stream Analytics query.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


You have to deploy resources on Azure HDInsight for a batch processing job. The batch processing must run daily and must scale to minimize costs. You also be able to monitor cluster performance. You need to decide on a tool that will monitor the clusters and provide information on suggestions on how to scale. You decide on monitoring the cluster load by using the Ambari Web UI. Would this fulfill the requirement?
A. Yes
B. No

You have an enterprise data warehouse in Azure Synapse Analytics. Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse. The external table has three columns. You discover that the Parquet files have a fourth column named ItemID. Which command should you run to add the ItemID column to the external table?

A. Option A
B. Option B
C. Option C
D. Option D
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Use information stored in Azure Active Directory reports. Does the solution meet the goal?
A. Yes
B. No
You develop data engineering solutions for a company. You must integrate the company's on-premises Microsoft SQL Server data with Microsoft Azure SQL Database. Data must be transformed incrementally. You need to implement the data integration solution. Which tool should you use to configure a pipeline to copy data?
A. Use the Copy Data tool with Blob storage linked service as the source
B. Use Azure PowerShell with SQL Server linked service as a source
C. Use Azure Data Factory UI with Blob storage linked service as a source
D. Use the .NET Data Factory API with Blob storage linked service as the source
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account. Does the solution meet the goal?
A. Yes
B. No
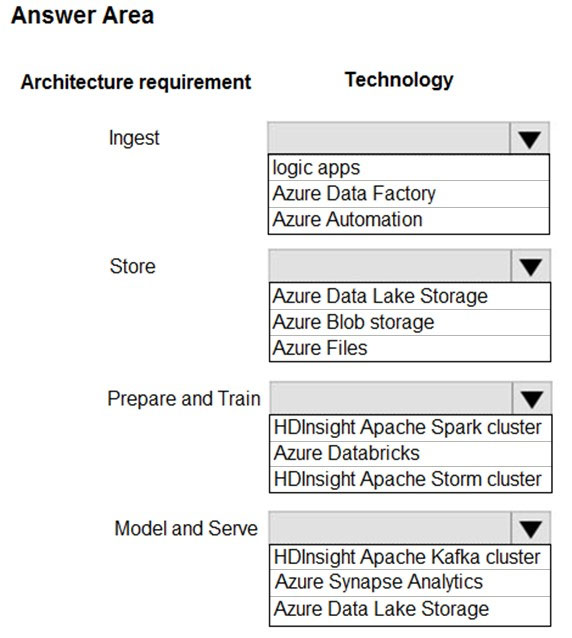
HOTSPOT - A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements: Ingest: ✑ Access multiple data sources. ✑ Provide the ability to orchestrate workflow. ✑ Provide the capability to run SQL Server Integration Services packages. Store: ✑ Optimize storage for big data workloads ✑ Provide encryption of data at rest. ✑ Operate with no size limits. Prepare and Train: ✑ Provide a fully-managed and interactive workspace for exploration and visualization. ✑ Provide the ability to program in R, SQL, Python, Scala, and Java. ✑ Provide seamless user authentication with Azure Active Directory. Model & Serve: ✑ Implement native columnar storage. ✑ Support for the SQL language. ✑ Provide support for structured streaming. You need to build the data integration pipeline. Which technologies should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
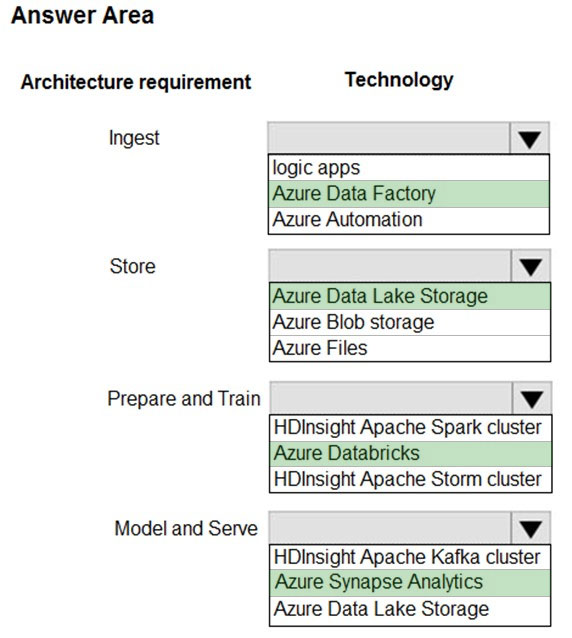
You need to develop a pipeline for processing data. The pipeline must meet the following requirements: ✑ Scale up and down resources for cost reduction ✑ Use an in-memory data processing engine to speed up ETL and machine learning operations. ✑ Use streaming capabilities ✑ Provide the ability to code in SQL, Python, Scala, and R Integrate workspace collaboration with GitWhat should you use?
A. HDInsight Spark Cluster
B. Azure Stream Analytics
C. HDInsight Hadoop Cluster
D. Azure SQL Data Warehouse
E. HDInsight Kafka Cluster
F. HDInsight Storm Cluster
You have an activity in an Azure Data Factory pipeline. The activity calls a stored procedure in a data warehouse in Azure Synapse Analytics and runs daily. You need to verify the duration of the activity when it ran last. What should you use?
A. the sys.dm_pdw_wait_stats data management view in Azure Synapse Analytics
B. an Azure Resource Manager template
C. activity runs in Azure Monitor
D. Activity log in Azure Synapse Analytics
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a Standard cluster for the data engineers, and a High Concurrency cluster for the jobs. Does this meet the goal?
A. Yes
B. No
A company runs Microsoft SQL Server in an on-premises virtual machine (VM). You must migrate the database to Azure SQL Database. You synchronize users from Active Directory to Azure Active Directory (Azure AD). You need to configure Azure SQL Database to use an Azure AD user as administrator. What should you configure?
A. For each Azure SQL Database, set the Access Control to administrator.
B. For each Azure SQL Database server, set the Active Directory to administrator.
C. For each Azure SQL Database, set the Active Directory administrator role.
D. For each Azure SQL Database server, set the Access Control to administrator.
Your company manages a payroll application for its customers worldwide. The application uses an Azure SQL database named DB1. The database contains a table named Employee and an identity column named EmployeeId. A customer requests the EmployeeId be treated as sensitive data. Whenever a user queries EmployeeId, you need to return a random value between 1 and 10 instead of the EmployeeId value. Which masking format should you use?
A. string
B. number
C. default
SIMULATION - Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10543936 -You plan to enable Azure Multi-Factor Authentication (MFA). You need to ensure that User1-10543936@ExamUsers.com can manage any databases hosted on an Azure SQL server named SQL10543936 by signing in using his Azure Active Directory (Azure AD) user account. To complete this task, sign in to the Azure portal.
You have an Azure data factory. You need to examine the pipeline failures from the last 60 days. What should you use?
A. the Activity log blade for the Data Factory resource
B. Azure Monitor
C. the Monitor & Manage app in Data Factory
D. the Resource health blade for the Data Factory resource
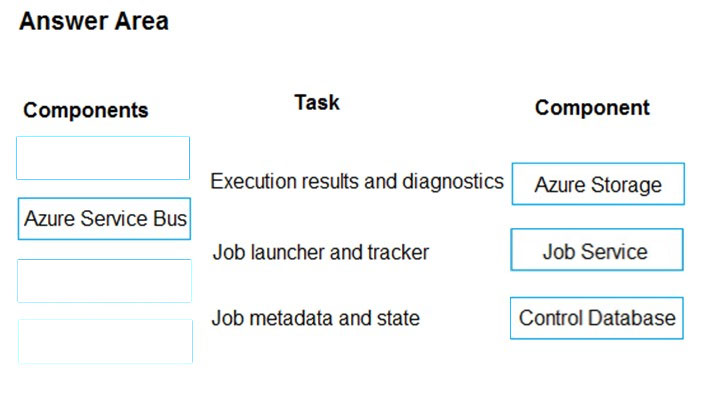
DRAG DROP - Your company uses Microsoft Azure SQL Database configured with Elastic pools. You use Elastic Database jobs to run queries across all databases in the pool. You need to analyze, troubleshoot, and report on components responsible for running Elastic Database jobs. You need to determine the component responsible for running job service tasks. Which components should you use for each Elastic pool job services task? To answer, drag the appropriate component to the correct task. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
You plan to create a dimension table in Azure Synapse Analytics that will be less than 1 GB. You need to create the table to meet the following requirements: ✑ Provide the fastest query time. ✑ Minimize data movement during queries. Which type of table should you use?
A. hash distributed
B. heap
C. replicated
D. round-robin
You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU% Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Watermark Delay
B. Late Input Events
C. Out of order Events
D. Backlogged Input Events
E. Function Events
DRAG DROP - You plan to create a new single database instance of Microsoft Azure SQL Database. The database must only allow communication from the data engineer's workstation. You must connect directly to the instance by using Microsoft SQL Server Management Studio. You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order. Select and Place:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You apply an Azure policy that tags the storage account. Does this meet the goal?
A. Yes
B. No
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution will have a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year. Which two factors affect your costs when sizing the Azure SQL Database elastic pools? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. maximum data size
B. number of databases
C. eDTUs consumption
D. number of read operations
E. number of transactions
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure subscription that contains an Azure Storage account. You plan to implement changes to a data storage solution to meet regulatory and compliance standards. Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days. Solution: You schedule an Azure Data Factory pipeline. Does this meet the goal?
A. Yes
B. No
Access Full DP-200 Exam Prep Free
Want to go beyond these 50 questions? Click here to unlock a full set of DP-200 exam prep free questions covering every domain tested on the exam.
We continuously update our content to ensure you have the most current and effective prep materials.
Good luck with your DP-200 certification journey!