DP-200 Dump Free – 50 Practice Questions to Sharpen Your Exam Readiness.
Looking for a reliable way to prepare for your DP-200 certification? Our DP-200 Dump Free includes 50 exam-style practice questions designed to reflect real test scenarios—helping you study smarter and pass with confidence.
Using an DP-200 dump free set of questions can give you an edge in your exam prep by helping you:
Understand the format and types of questions you’ll face
Pinpoint weak areas and focus your study efforts
Boost your confidence with realistic question practice
Below, you will find 50 free questions from our DP-200 Dump Free collection. These cover key topics and are structured to simulate the difficulty level of the real exam, making them a valuable tool for review or final prep.
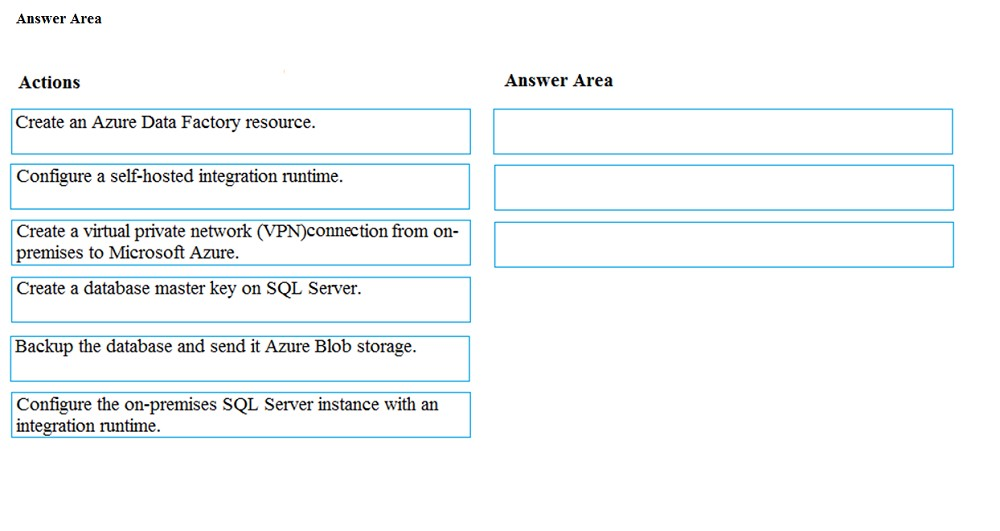
DRAG DROP -
Your company manages on-premises Microsoft SQL Server pipelines by using a custom solution.
The data engineering team must implement a process to pull data from SQL Server and migrate it to Azure Blob storage. The process must orchestrate and manage the data lifecycle.
You need to configure Azure Data Factory to connect to the on-premises SQL Server database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
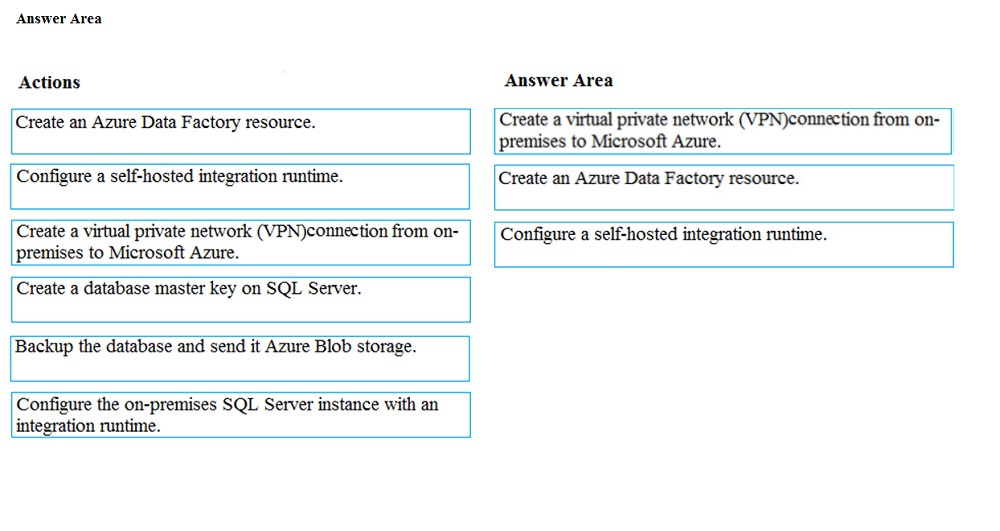
Step 1: Create a virtual private network (VPN) connection from on-premises to Microsoft Azure.
You can also use IPSec VPN or Azure ExpressRoute to further secure the communication channel between your on-premises network and Azure.
Azure Virtual Network is a logical representation of your network in the cloud. You can connect an on-premises network to your virtual network by setting up IPSec
VPN (site-to-site) or ExpressRoute (private peering).
Step 2: Create an Azure Data Factory resource.
Step 3: Configure a self-hosted integration runtime.
You create a self-hosted integration runtime and associate it with an on-premises machine with the SQL Server database. The self-hosted integration runtime is the component that copies data from the SQL Server database on your machine to Azure Blob storage.
Note: A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on- premises machine or a virtual machine (VM) inside a private network.
References: https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-powershell
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data.
The analytical data store performs poorly.
You must implement a solution that meets the following requirements:
✑ Provide data warehousing
✑ Reduce ongoing management activities
✑ Deliver SQL query responses in less than one second
You need to create an HDInsight cluster to meet the requirements.
Which type of cluster should you create?
A. Interactive Query
B. Apache Hadoop
C. Apache HBase
D. Apache Spark
Suggested Answer: D
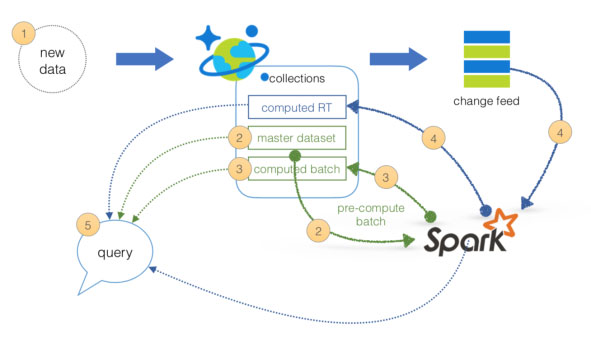
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics:
1. Azure Cosmos DB, a globally distributed and multi-model database service.
2. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.
3. Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process.
4. The Spark to Azure Cosmos DB Connector
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References: alt=”Reference Image” />
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References: https://sqlwithmanoj.com/2018/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-db/
DRAG DROP -
You manage a financial computation data analysis process. Microsoft Azure virtual machines (VMs) run the process in daily jobs, and store the results in virtual hard drives (VHDs.)
The VMs product results using data from the previous day and store the results in a snapshot of the VHD. When a new month begins, a process creates a new
VHD.
You must implement the following data retention requirements:
✑ Daily results must be kept for 90 days
✑ Data for the current year must be available for weekly reports
✑ Data from the previous 10 years must be stored for auditing purposes
✑ Data required for an audit must be produced within 10 days of a request.
You need to enforce the data retention requirements while minimizing cost.
How should you configure the lifecycle policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
DRAG DROP -
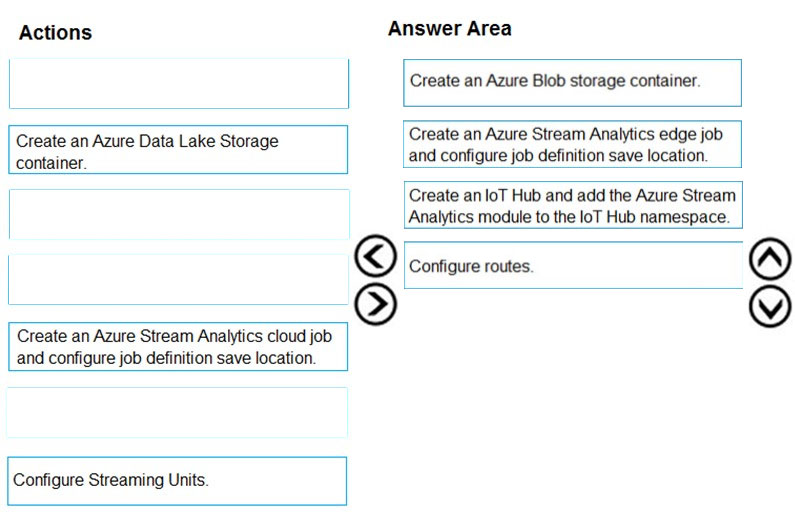
You develop data engineering solutions for a company.
You need to deploy a Microsoft Azure Stream Analytics job for an IoT solution. The solution must:
✑ Minimize latency.
✑ Minimize bandwidth usage between the job and IoT device.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Step 1: Create an Azure Blob Storage container
To prepare your Stream Analytics job to be deployed on an IoT Edge device, you need to associate the job with a container in a storage account. When you go to deploy your job, the job definition is exported to the storage container.
Step 2: Create an Azure Stream Analytics edge job and configure job definition save location
When you create an Azure Stream Analytics job to run on an IoT Edge device, it needs to be stored in a way that can be called from the device.
Step 3: Create and IoT hub and add the Azure Stream Analytics module to the IoT Hub namespace
An IoT Hub in Azure is required.
Stream Analytics accepts data incoming from several kinds of event sources including Event Hubs, IoT Hub, and Blob storage.
Step 4: Configure routes –
You are now ready to deploy the Azure Stream Analytics job on your IoT Edge device.
The routes that you declare define the flow of data through the IoT Edge device.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-add-inputs https://docs.microsoft.com/en-us/azure/iot-edge/tutorial-deploy-stream-analytics https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-edge
DRAG DROP -
You are responsible for providing access to an Azure Data Lake Storage Gen2 account.
Your user account has contributor access to the storage account, and you have the application ID and access key.
You plan to use PolyBase to load data into an enterprise data warehouse in Azure Synapse Analytics.
You need to configure PolyBase to connect the data warehouse to the storage account.
Which three components should you create in sequence? To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Step 1: a database scoped credential
To access your Data Lake Storage account, you will need to create a Database Master Key to encrypt your credential secret used in the next step. You then create a database scoped credential.
Step 2: an external data source –
Create the external data source. Use the CREATE EXTERNAL DATA SOURCE command to store the location of the data. Provide the credential created in the previous step.
Step 3: an external file format –
Configure data format: To import the data from Data Lake Storage, you need to specify the External File Format. This object defines how the files are written in
Data Lake Storage.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
HOTSPOT -
You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository.
You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: NameNode –
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
Box 2: DataNode –
The DataNodes are responsible for serving read and write requests from the file system’s clients.
Box 3: DataNode –
The DataNodes perform block creation, deletion, and replication upon instruction from the NameNode.
Note: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
References: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
HOTSPOT -
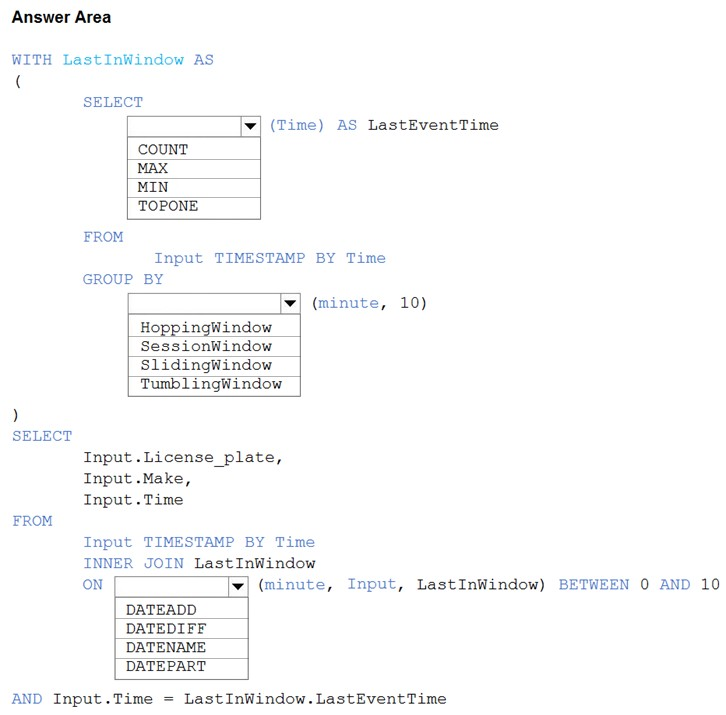
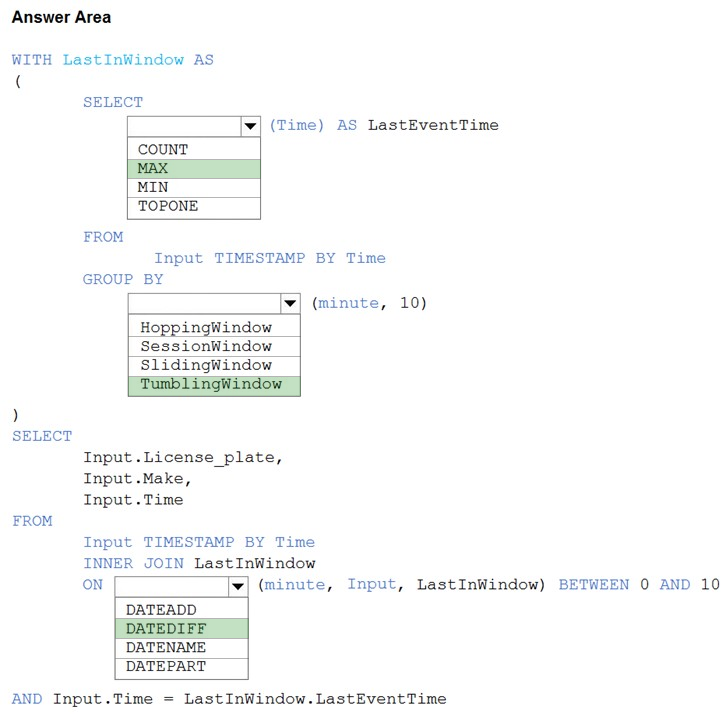
You are processing streaming data from vehicles that pass through a toll booth.
You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window.
How should you complete the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: MAX –
The first step on the query finds the maximum time stamp in 10-minute windows, that is the time stamp of the last event for that window. The second step joins the results of the first query with the original stream to find the event that match the last time stamps in each window.
Query:
WITH LastInWindow AS –
(
SELECT –
MAX(Time) AS LastEventTime –
FROM –
Input TIMESTAMP BY Time –
GROUP BY –
TumblingWindow(minute, 10)
)
SELECT –
Input.License_plate,
Input.Make,
Input.Time –
FROM –
Input TIMESTAMP BY Time –
INNER JOIN LastInWindow –
ON DATEDIFF(minute, Input, LastInWindow) BETWEEN 0 AND 10
AND Input.Time = LastInWindow.LastEventTime
Box 2: TumblingWindow –
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals.
Box 3: DATEDIFF –
DATEDIFF is a date-specific function that compares and returns the time difference between two DateTime fields, for more information, refer to date functions.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
HOTSPOT -
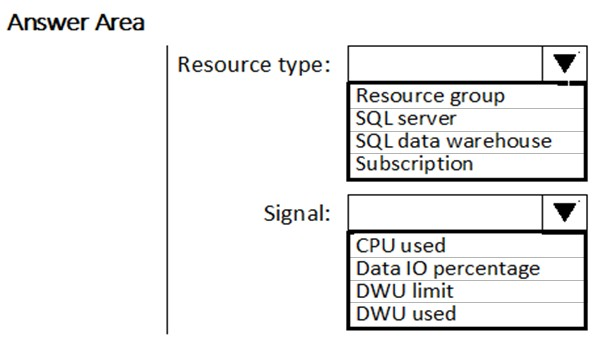
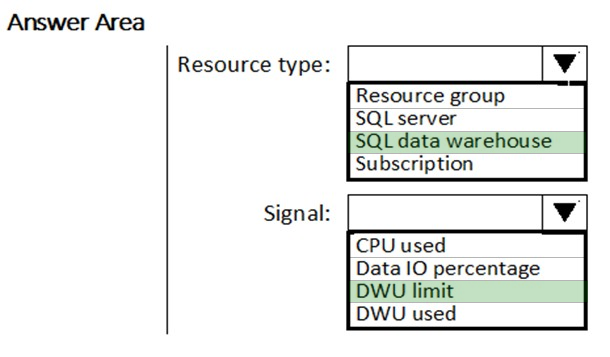
You need to receive an alert when Azure Synapse Analytics consumes the maximum allotted resources.
Which resource type and signal should you use to create the alert in Azure Monitor? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You have a SQL pool in Azure Synapse.
A user reports that queries against the pool take longer than expected to complete.
You need to add monitoring to the underlying storage to help diagnose the issue.
Which two metrics should you monitor? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure subscription that contains an Azure Storage account.
You plan to implement changes to a data storage solution to meet regulatory and compliance standards.
Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days.
Solution: You schedule an Azure Data Factory pipeline.
Does this meet the goal?
DRAG DROP -
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a property formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
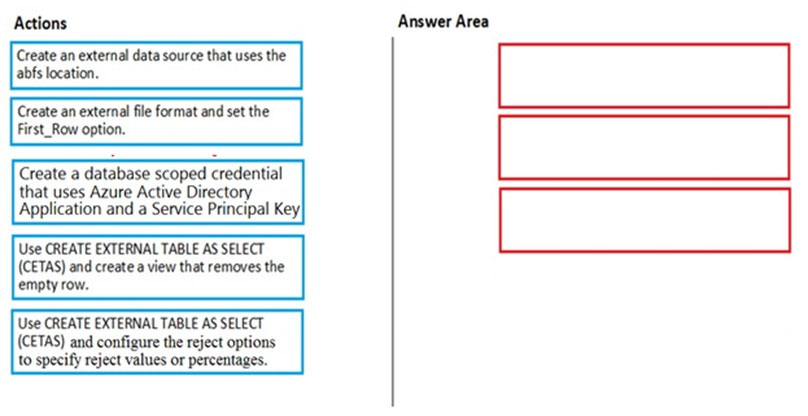
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Step 1: Create an external data source that uses the abfs location
Create External Data Source to reference Azure Data Lake Store Gen 1 or 2
Step 2: Create an external file format and set the First_Row option.
Create External File Format.
Step 3: Use CREATE EXTERNAL TABLE AS SELECT (CETAS) and configure the reject options to specify reject values or percentages
To use PolyBase, you must create external tables to reference your external data.
Use reject options.
Note: REJECT options don’t apply at the time this CREATE EXTERNAL TABLE AS SELECT statement is run. Instead, they’re specified here so that the database can use them at a later time when it imports data from the external table. Later, when the CREATE TABLE AS SELECT statement selects data from the external table, the database will use the reject options to determine the number or percentage of rows that can fail to import before it stops the import.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-t-sql-objects https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-table-as-select-transact-sql
HOTSPOT -
Which masking functions should you implement for each column to meet the data masking requirements? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Custom text/string: A masking method, which exposes the first and/or last characters and adds a custom padding string in the middle.
Only show the last four digits of the values in a column named SuspensionSprings.
Box 2: Default –
Default uses a zero value for numeric data types (bigint, bit, decimal, int, money, numeric, smallint, smallmoney, tinyint, float, real).
Scenario: Only show a zero value for the values in a column named ShockOilWeight.
Scenario:
The company identifies the following data masking requirements for the Race Central data that will be stored in SQL Database:
✑ Only show a zero value for the values in a column named ShockOilWeight.
✑ Only show the last four digits of the values in a column named SuspensionSprings.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and destroying clusters daily because most of the data pipeline process runs in minutes.
You need to implement a solution that deploys multiple HDInsight clusters with minimal effort.
What should you implement?
A. Azure Databricks
B. Azure Traffic Manager
C. Azure Resource Manager templates
D. Ambari web user interface
Suggested Answer: C
A Resource Manager template makes it easy to create the following resources for your application in a single, coordinated operation:
✑ HDInsight clusters and their dependent resources (such as the default storage account).
✑ Other resources (such as Azure SQL Database to use Apache Sqoop).
In the template, you define the resources that are needed for the application. You also specify deployment parameters to input values for different environments.
The template consists of JSON and expressions that you use to construct values for your deployment.
References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-create-linux-clusters-arm-templates
Each day, company plans to store hundreds of files in Azure Blob Storage and Azure Data Lake Storage. The company uses the parquet format.
You must develop a pipeline that meets the following requirements:
✑ Process data every six hours
✑ Offer interactive data analysis capabilities
✑ Offer the ability to process data using solid-state drive (SSD) caching
✑ Use Directed Acyclic Graph(DAG) processing mechanisms
✑ Provide support for REST API calls to monitor processes
✑ Provide native support for Python
✑ Integrate with Microsoft Power BI
You need to select the appropriate data technology to implement the pipeline.
Which data technology should you implement?
A. Azure SQL Data Warehouse
B. HDInsight Apache Storm cluster
C. Azure Stream Analytics
D. HDInsight Apache Hadoop cluster using MapReduce
E. HDInsight Spark cluster
Suggested Answer: B
Storm runs topologies instead of the Apache Hadoop MapReduce jobs that you might be familiar with. Storm topologies are composed of multiple components that are arranged in a directed acyclic graph (DAG). Data flows between the components in the graph. Each component consumes one or more data streams, and can optionally emit one or more streams.
Python can be used to develop Storm components.
References: https://docs.microsoft.com/en-us/azure/hdinsight/storm/apache-storm-overview
DRAG DROP -
You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1.
You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege.
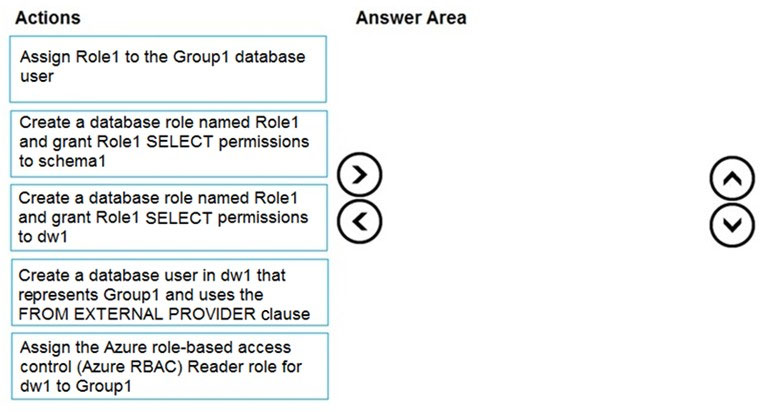
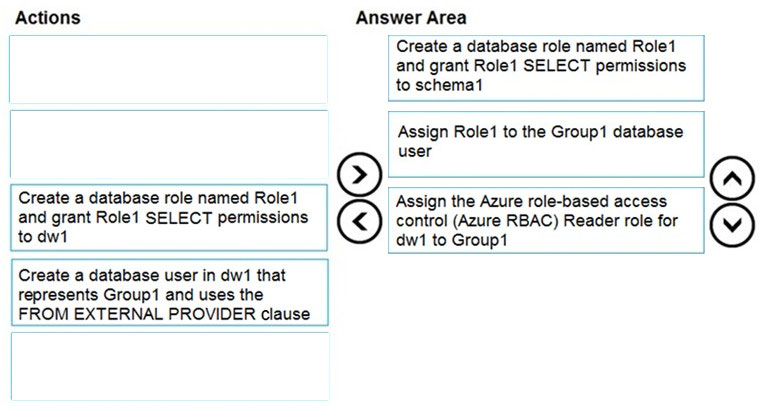
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:
Suggested Answer:
Step 1: Create a database role named Role1 and grant Role1 SELECT permissions to schema
You need to grant Group1 read-only permissions to all the tables and views in schema1.
Place one or more database users into a database role and then assign permissions to the database role.
Step 2: Assign Rol1 to the Group database user
Step 3: Assign the Azure role-based access control (Azure RBAC) Reader role for dw1 to Group1
Reference: https://docs.microsoft.com/en-us/azure/data-share/how-to-share-from-sql
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure
Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one query, and two outputs.
Does this meet the goal?
DRAG DROP -
You need to replace the SSIS process by using Data Factory.
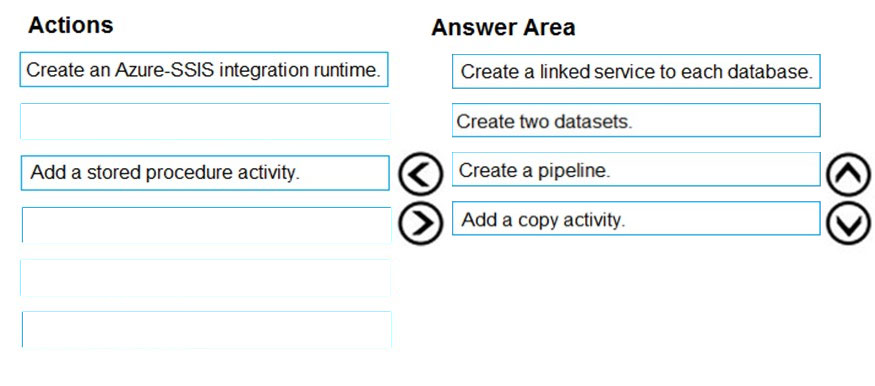
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Scenario: A daily process creates reporting data in REPORTINGDB from the data in SALESDB. The process is implemented as a SQL Server Integration
Services (SSIS) package that runs a stored procedure from SALESDB.
Step 1: Create a linked service to each database
Step 2: Create two datasets –
You can create two datasets: InputDataset and OutputDataset. These datasets are of type AzureBlob. They refer to the Azure Storage linked service that you created in the previous section.
Step 3: Create a pipeline –
You create and validate a pipeline with a copy activity that uses the input and output datasets.
Step 4: Add a copy activity –
References: https://docs.microsoft.com/en-us/azure/data-factory/quickstart-create-data-factory-portal
SIMULATION -
Use the following login credentials as needed:
Azure Username: xxxxx -
Azure Password: xxxxx -
The following information is for technical support purposes only:
Lab Instance: 10543936 -
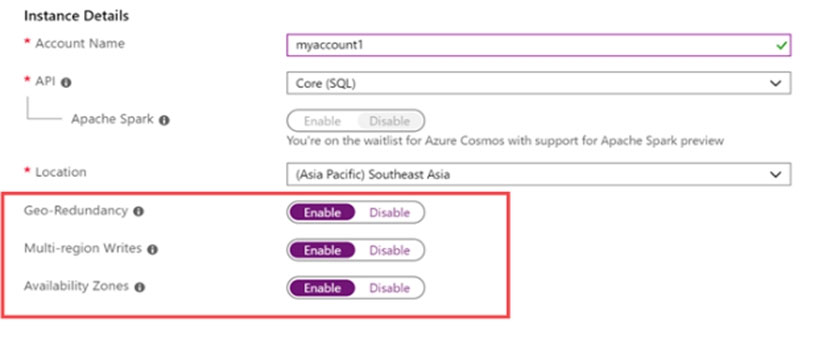
You need to ensure that users in the West US region can read data from a local copy of an Azure Cosmos DB database named cosmos10543936.
To complete this task, sign in to the Azure portal.
NOTE: This task might take several minutes to complete. You can perform other tasks while the task completes or end this section of the exam.
Suggested Answer: See the explanation below.
You can enable Availability Zones by using Azure portal when creating an Azure Cosmos account.
You can enable Availability Zones by using Azure portal.
Step 1: enable the Geo-redundancy, Multi-region Writes
1. In Azure Portal search for and select Azure Cosmos DB.
2. Locate the Cosmos DB database named cosmos10543936
3. Access the properties for cosmos10543936
4. enable the Geo-redundancy, Multi-region Writes.
Location: West US region –
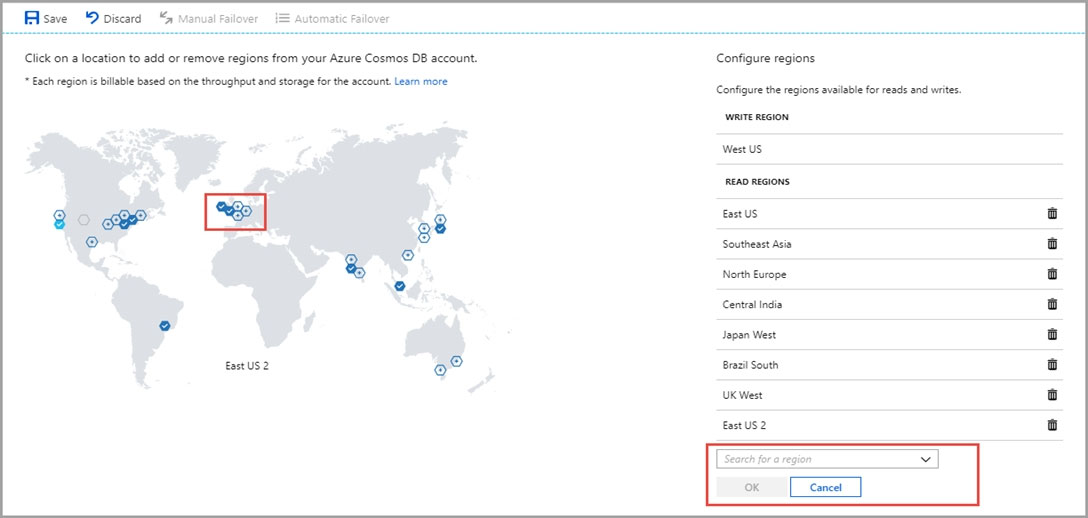
Step 2: Add region from your database account
1. In to Azure portal, go to your Azure Cosmos account, and open the Replicate data globally menu.
2. To add regions, select the hexagons on the map with the + label that corresponds to your desired region(s). Alternatively, to add a region, select the + Add region option and choose a region from the drop-down menu.
Add: West US region –
3. To save your changes, select OK.
Reference: alt=”Reference Image” />
Step 2: Add region from your database account
1. In to Azure portal, go to your Azure Cosmos account, and open the Replicate data globally menu.
2. To add regions, select the hexagons on the map with the + label that corresponds to your desired region(s). Alternatively, to add a region, select the + Add region option and choose a region from the drop-down menu.
Add: West US region –
<img src=”https://www.examtopics.com/assets/media/exam-media/03872/0008100001.jpg” alt=”Reference Image” />
3. To save your changes, select OK.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/high-availability https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-manage-database-account
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.
The partition key is set to the OrderId attribute.
Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete.
You need to reduce the amount of time it takes to execute the problematic queries.
Solution: You increase the Request Units (RUs) for the database.
Does this meet the goal?
A. Yes
B. No
Suggested Answer: A
To scale the provisioned throughput for your application, you can increase or decrease the number of RUs at any time.
Note: The cost of all database operations is normalized by Azure Cosmos DB and is expressed by Request Units (or RUs, for short). You can think of RUs per second as the currency for throughput. RUs per second is a rate-based currency. It abstracts the system resources such as CPU, IOPS, and memory that are required to perform the database operations supported by Azure Cosmos DB.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/request-units
You have to create a new single database instance of Microsoft Azure SQL database. You must ensure that client connections are accepted via a workstation.
The workstation will use SQL Server Management Studio to connect to the database instance.
Which of the following Powershell commands would you execute to create and configure the database? (Choose three.)
A. New-AzureRmSqlElasticPool
B. New-AzureRmSqlServerFirewallRule
C. New-AzureRmSqlServer
D. New-AzureRmSqlServerVirtualNetworkRule
E. New-AzureRmSqlDatabase
Suggested Answer: BCE
The Microsoft documentation clearly gives the steps to create and configure the database. Please note the below snippet shows the new powershell commands, but you can also use the older Azure PowerShell commands.
Since this is clearly given in the documentation, all other options are incorrect.
Reference: alt=”Reference Image” />
Since this is clearly given in the documentation, all other options are incorrect.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/scripts/sql-database-create-and-configure-database-powershell
You create an Azure Databricks cluster and specify an additional library to install.
When you attempt to load the library to a notebook, the library is not found.
You need to identify the cause of the issue.
What should you review?
A. workspace logs
B. notebook logs
C. global init scripts logs
D. cluster event logs
Suggested Answer: C
Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each cluster node before the Spark driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom libraries, launching background processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same root folder as driver and executor logs for the cluster.
Reference: https://databricks.com/blog/2018/08/30/introducing-cluster-scoped-init-scripts.html
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure subscription that contains an Azure Storage account.
You plan to implement changes to a data storage solution to meet regulatory and compliance standards.
Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days.
Solution: You apply an expired tag to the blobs in the storage account.
Does this meet the goal?
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse.
Solution:
1. Create an external data source pointing to the Azure Data Lake Gen 2 storage account
2. Create an external file format and external table using the external data source
3. Load the data using the CREATE TABLE AS SELECT statement
Does the solution meet the goal?
You have to implement Azure Stream Analytics Functions as part of your data streaming solution.
The solution has the following requirements:
- Segment the data stream into distinct time segments that do not repeat or overlap
- Segment the data stream into distinct time segments that repeat and can overlap
- Segment the data stream to produce an output when an event occurs
Which of the following windowing function would you use for the following requirement?
`Segment the data stream into distinct time segments that do not repeat or overlap`
A. Hopping
B. Session
C. Sliding
D. Tumbling
Suggested Answer: D
You need to use the Tumbling windowing function for this requirement.
The Microsoft documentation mentions the following:
Tumbling window –
Tumbling window functions are used to segment a data stream into distinct time segments and perform a function against them, such as the example below. The key differentiators of a Tumbling window are that they repeat, do not overlap, and an event cannot belong to more than one tumbling window.
Since this is clearly given in the documentation, all other options are incorrect.
Reference: alt=”Reference Image” />
Since this is clearly given in the documentation, all other options are incorrect.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1.
Several users execute adhoc queries to DW1 concurrently.
You regularly perform automated data loads to DW1.
You need to ensure that the automated data loads have enough memory available to complete quickly and successfully when the adhoc queries run.
What should you do?
A. Hash distribute the large fact tables in DW1 before performing the automated data loads.
B. Assign a larger resource class to the automated data load queries.
C. Create sampled statistics for every column in each table of DW1.
D. Assign a smaller resource class to the automated data load queries.
DRAG DROP -
You need to provision the polling data storage account.
How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE:
Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Account type: StorageV2 –
You must create new storage accounts as type StorageV2 (general-purpose V2) to take advantage of Data Lake Storage Gen2 features.
Scenario: Polling data is stored in one of the two locations:
✑ An on-premises Microsoft SQL Server 2019 database named PollingData
✑ Azure Data Lake Gen 2
Data in Data Lake is queried by using PolyBase
Replication type: RA-GRS –
Scenario: All services and processes must be resilient to a regional Azure outage.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9’s) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
If you opt for GRS, you have two related options to choose from:
✑ GRS replicates your data to another data center in a secondary region, but that data is available to be read only if Microsoft initiates a failover from the primary to secondary region.
✑ Read-access geo-redundant storage (RA-GRS) is based on GRS. RA-GRS replicates your data to another data center in a secondary region, and also provides you with the option to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether Microsoft initiates a failover from the primary to secondary region.
References: https://docs.microsoft.com/bs-cyrl-ba/azure/storage/blobs/data-lake-storage-quickstart-create-account https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database named DB1 that contains a table named Table1. Table1 has a field named Customer_ID that is varchar(22).
You need to implement masking for the Customer_ID field to meet the following requirements:
✑ The first two prefix characters must be exposed.
✑ The last four suffix characters must be exposed.
✑ All other characters must be masked.
Solution: You implement data masking and use a random number function mask.
Does this meet the goal?
A company plans to use Azure Storage for file storage purposes. Compliance rules require:
✑ A single storage account to store all operations including reads, writes and deletes
✑ Retention of an on-premises copy of historical operations
You need to configure the storage account.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Configure the storage account to log read, write and delete operations for service type Blob
B. Use the AzCopy tool to download log data from $logs/blob
C. Configure the storage account to log read, write and delete operations for service-type table
D. Use the storage client to download log data from $logs/table
E. Configure the storage account to log read, write and delete operations for service type queue
Suggested Answer: AB
Storage Logging logs request data in a set of blobs in a blob container named $logs in your storage account. This container does not show up if you list all the blob containers in your account but you can see its contents if you access it directly.
To view and analyze your log data, you should download the blobs that contain the log data you are interested in to a local machine. Many storage-browsing tools enable you to download blobs from your storage account; you can also use the Azure Storage team provided command-line Azure Copy Tool (AzCopy) to download your log data.
References: https://docs.microsoft.com/en-us/rest/api/storageservices/enabling-storage-logging-and-accessing-log-data
You implement an enterprise data warehouse in Azure Synapse Analytics.
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key Sale Key column to retrieve data as displayed in the following table:
You need to distribute the large fact table across multiple nodes to optimize performance of the table.
Which technology should you use?
A. hash distributed table with clustered ColumnStore index
B. hash distributed table with clustered index
C. heap table with distribution replicate
D. round robin distributed table with clustered index
E. round robin distributed table with clustered ColumnStore index
You have an enterprise data warehouse in Azure Synapse Analytics.
You need to monitor the data warehouse to identify whether you must scale up to a higher service level to accommodate the current workloads.
Which is the best metric to monitor?
More than one answer choice may achieve the goal. Select the BEST answer.
A. CPU percentage
B. DWU used
C. DWU percentage
D. Data IO percentage
Suggested Answer: B
DWU used, defined as DWU limit * DWU percentage, represents only a high-level representation of usage across the SQL pool and is not meant to be a comprehensive indicator of utilization. To determine whether to scale up or down, consider all factors which can be impacted by DWU such as concurrency, memory, tempdb, and adaptive cache capacity. We recommend running your workload at different DWU settings to determine what works best to meet your business objectives.
Reference: https://docs.microsoft.com/bs-latn-ba/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-concept-resource-utilization-query-activity
HOTSPOT -
You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:
Which database and authorization types are used? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
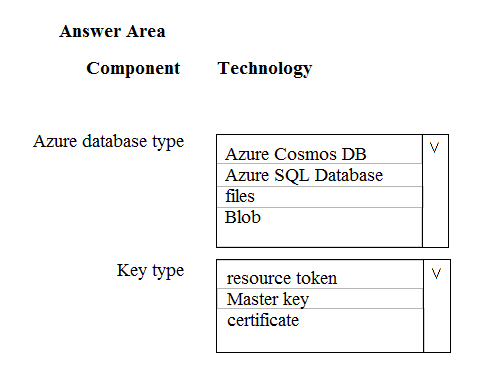
Box 1: Azure Cosmos DB –
The DocumentClient.CreateDatabaseAsync(Database, RequestOptions) method creates a database resource as an asychronous operation in the Azure Cosmos
DB service.
Box 2: Master Key –
Azure Cosmos DB uses two types of keys to authenticate users and provide access to its data and resources: Master Key, Resource Tokens
Master keys provide access to the all the administrative resources for the database account. Master keys:
Provide access to accounts, databases, users, and permissions.
✑ Cannot be used to provide granular access to containers and documents.
✑ Are created during the creation of an account.
✑ Can be regenerated at any time.
Incorrect Answers:
Resource Token: Resource tokens provide access to the application resources within a database.
References: alt=”Reference Image” />
✑ Cannot be used to provide granular access to containers and documents.
✑ Are created during the creation of an account.
✑ Can be regenerated at any time.
Incorrect Answers:
Resource Token: Resource tokens provide access to the application resources within a database.
References: https://docs.microsoft.com/en-us/dotnet/api/microsoft.azure.documents.client.documentclient.createdatabaseasync https://docs.microsoft.com/en-us/azure/cosmos-db/secure-access-to-data
You develop data engineering solutions for a company.
You must integrate the company's on-premises Microsoft SQL Server data with Microsoft Azure SQL Database. Data must be transformed incrementally.
You need to implement the data integration solution.
Which tool should you use to configure a pipeline to copy data?
A. Use the Copy Data tool with Blob storage linked service as the source
B. Use Azure PowerShell with SQL Server linked service as a source
C. Use Azure Data Factory UI with Blob storage linked service as a source
D. Use the .NET Data Factory API with Blob storage linked service as the source
Suggested Answer: C
The Integration Runtime is a customer managed data integration infrastructure used by Azure Data Factory to provide data integration capabilities across different network environments.
A linked service defines the information needed for Azure Data Factory to connect to a data resource. We have three resources in this scenario for which linked services are needed:
✑ On-premises SQL Server
✑ Azure Blob Storage
✑ Azure SQL database
Note: Azure Data Factory is a fully managed cloud-based data integration service that orchestrates and automates the movement and transformation of data. The key concept in the ADF model is pipeline. A pipeline is a logical grouping of Activities, each of which defines the actions to perform on the data contained in
Datasets. Linked services are used to define the information needed for Data Factory to connect to the data resources.
References: https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-sql-azure-adf
HOTSPOT -
A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row.
You need to create the input stream.
How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT -
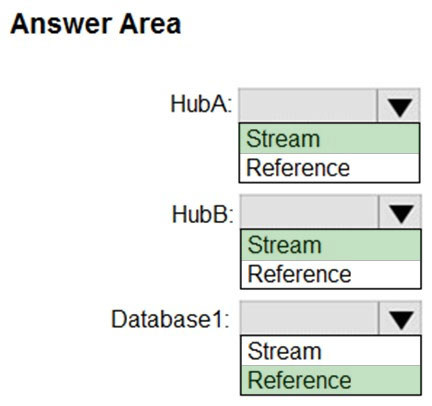
You have an Azure SQL database named Database1 and two Azure event hubs named HubA and HubB. The data consumed from each source is shown in the following table.
You need to implement Azure Stream Analytics to calculate the average fare per mile by driver.
How should you configure the Stream Analytics input for each source? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
HubA: Stream –
HubB: Stream –
Database1: Reference –
Reference data (also known as a lookup table) is a finite data set that is static or slowly changing in nature, used to perform a lookup or to augment your data streams. For example, in an IoT scenario, you could store metadata about sensors (which don’t change often) in reference data and join it with real time IoT data streams. Azure Stream Analytics loads reference data in memory to achieve low latency stream processing
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-reference-data
SIMULATION -
Use the following login credentials as needed:
Azure Username: xxxxx -
Azure Password: xxxxx -
The following information is for technical support purposes only:
Lab Instance: 10277521 -
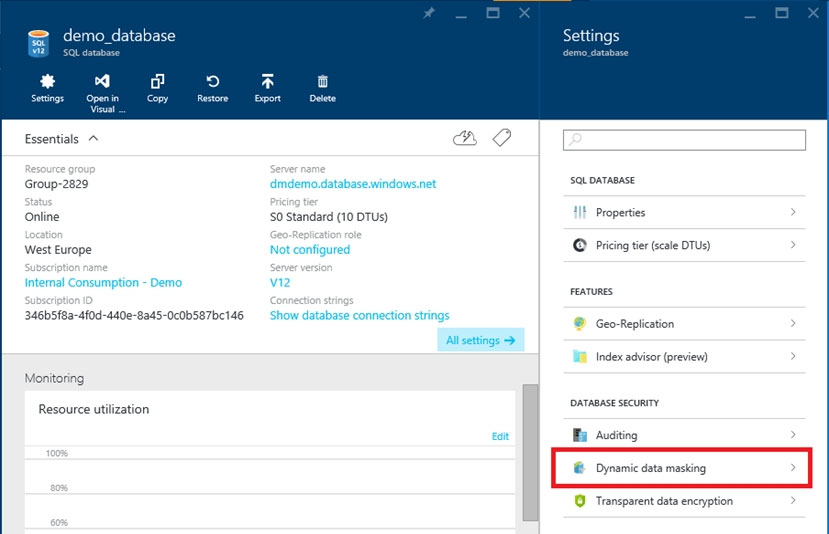
You plan to query db3 to retrieve a list of sales customers. The query will retrieve several columns that include the email address of each sales customer.
You need to modify db3 to ensure that a portion of the email addresses is hidden in the query results.
To complete this task, sign in to the Azure portal.
Suggested Answer: See the explanation below.
1. Launch the Azure portal.
2. Navigate to the settings page of the database db3 that includes the sensitive data you want to mask.
3. Click the Dynamic Data Masking tile that launches the Dynamic Data Masking configuration page.
Note: Alternatively, you can scroll down to the Operations section and click Dynamic Data Masking.
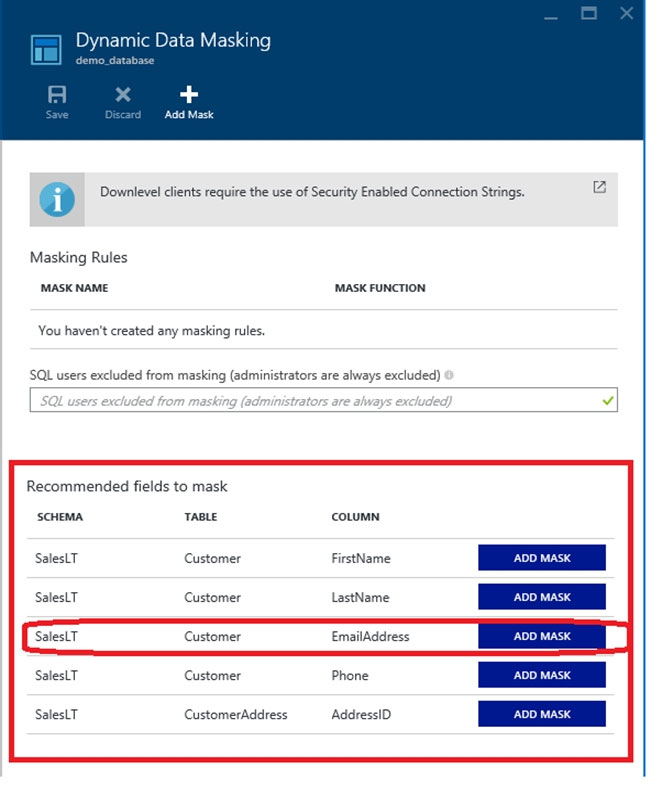
4. In the Dynamic Data Masking configuration page, you may see some database columns that the recommendations engine has flagged for masking.
5. Click ADD MASK for the EmailAddress column
6. Click Save in the data masking rule page to update the set of masking rules in the dynamic data masking policy.
References: alt=”Reference Image” />
4. In the Dynamic Data Masking configuration page, you may see some database columns that the recommendations engine has flagged for masking.
<img src=”https://www.examtopics.com/assets/media/exam-media/03872/0006300001.jpg” alt=”Reference Image” />
5. Click ADD MASK for the EmailAddress column
6. Click Save in the data masking rule page to update the set of masking rules in the dynamic data masking policy.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-dynamic-data-masking-get-started-portal
DRAG DROP -
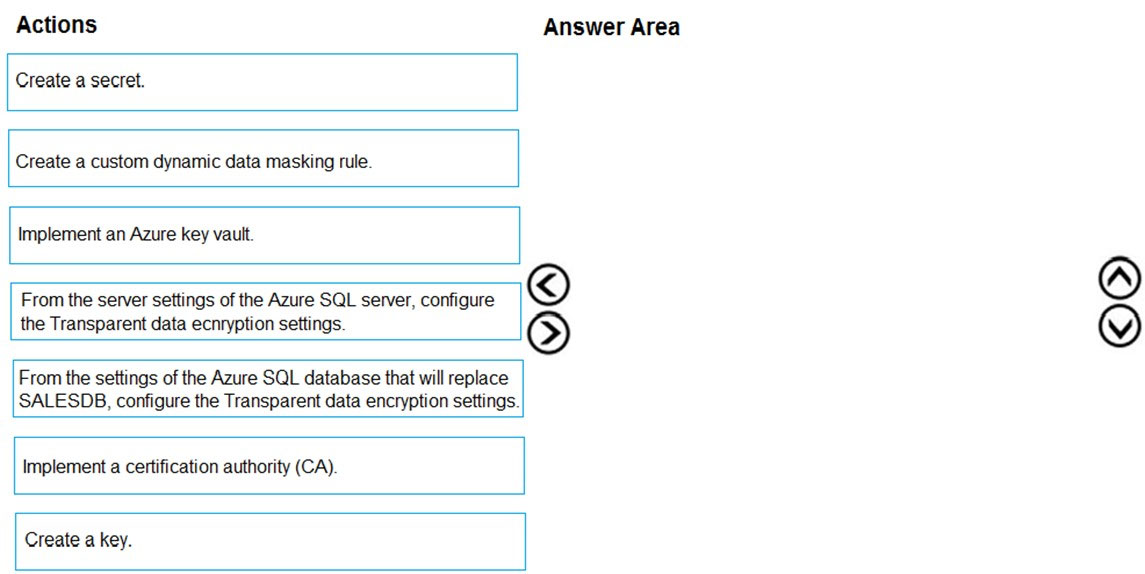
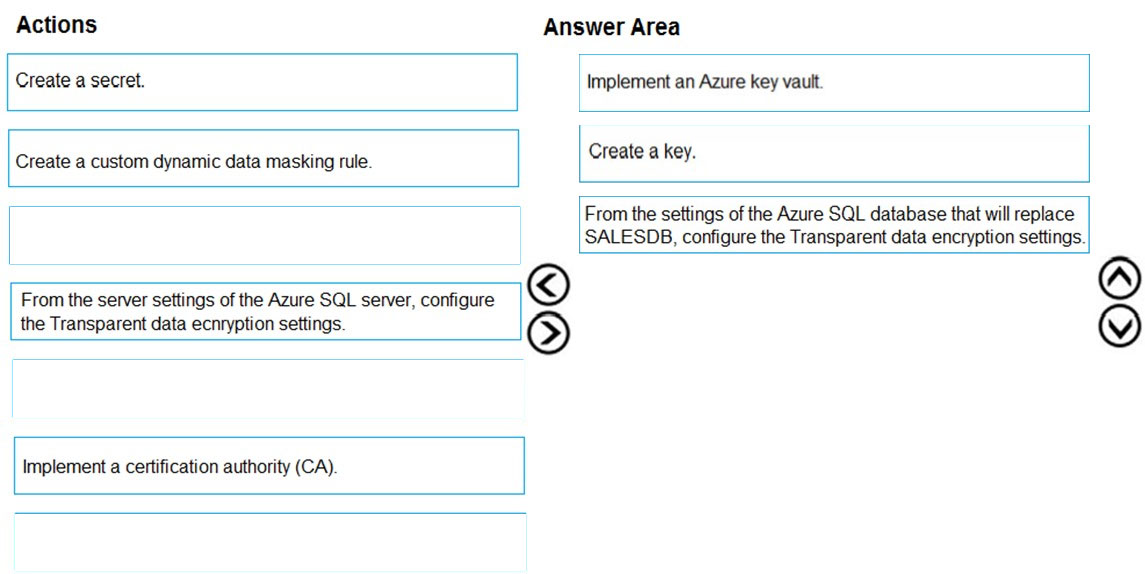
You need to implement the encryption for SALESDB.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Data in SALESDB must encrypted by using Transparent Data Encryption (TDE). The encryption must use your own key.
Step 1: Implement an Azure key vault
You must create an Azure Key Vault and Key to use for TDE
Step 2: Create a key –
Step 3: From the settings of the Azure SQL database ג€¦
You turn transparent data encryption on and off on the database level.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/transparent-data-encryption-byok-azure-sql-configure
You have an Azure SQL database that has masked columns.
You need to identify when a user attempts to infer data from the masked columns.
What should you use?
A. Azure Advanced Threat Protection (ATP)
B. custom masking rules
C. Transparent Data Encryption (TDE)
D. auditing
Suggested Answer: D
Dynamic Data Masking is designed to simplify application development by limiting data exposure in a set of pre-defined queries used by the application. While
Dynamic Data Masking can also be useful to prevent accidental exposure of sensitive data when accessing a production database directly, it is important to note that unprivileged users with ad-hoc query permissions can apply techniques to gain access to the actual data. If there is a need to grant such ad-hoc access,
Auditing should be used to monitor all database activity and mitigate this scenario.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
You plan to implement an Azure Cosmos DB database that will write 100,000,000 JSON records every 24 hours. The database will be replicated to three regions.
Only one region will be writable.
You need to select a consistency level for the database to meet the following requirements:
✑ Guarantee monotonic reads and writes within a session.
✑ Provide the fastest throughput.
✑ Provide the lowest latency.
Which consistency level should you select?
A. Strong
B. Bounded Staleness
C. Eventual
D. Session
E. Consistent Prefix
Suggested Answer: D
Session: Within a single client session reads are guaranteed to honor the consistent-prefix (assuming a single ג€writerג€ session), monotonic reads, monotonic writes, read-your-writes, and write-follows-reads guarantees. Clients outside of the session performing writes will see eventual consistency.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
You have an Azure Cosmos DB database that uses the SQL API.
You need to delete stale data from the database automatically.
What should you use?
A. soft delete
B. Low Latency Analytical Processing (LLAP)
C. schema on read
D. Time to Live (TTL)
Suggested Answer: D
With Time to Live or TTL, Azure Cosmos DB provides the ability to delete items automatically from a container after a certain time period. By default, you can set time to live at the container level and override the value on a per-item basis. After you set the TTL at a container or at an item level, Azure Cosmos DB will automatically remove these items after the time period, since the time they were last modified.
References: https://docs.microsoft.com/en-us/azure/cosmos-db/time-to-live
DRAG DROP -
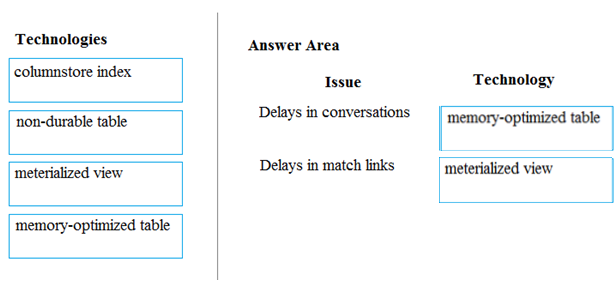
A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets.
When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation.
Customers report the following issues:
✑ Delays occur during live conversations
✑ A delay occurs before matching links appear after code snippets are added to conversations
You need to resolve the performance issues.
Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: memory-optimized table –
In-Memory OLTP can provide great performance benefits for transaction processing, data ingestion, and transient data scenarios.
Box 2: materialized view –
To support efficient querying, a common solution is to generate, in advance, a view that materializes the data in a format suited to the required results set. The
Materialized View pattern describes generating prepopulated views of data in environments where the source data isn’t in a suitable format for querying, where generating a suitable query is difficult, or where query performance is poor due to the nature of the data or the data store.
These materialized views, which only contain data required by a query, allow applications to quickly obtain the information they need. In addition to joining tables or combining data entities, materialized views can include the current values of calculated columns or data items, the results of combining values or executing transformations on the data items, and values specified as part of the query. A materialized view can even be optimized for just a single query.
References: https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view
DRAG DROP -
You plan to create a new single database instance of Microsoft Azure SQL Database.
The database must only allow communication from the data engineer's workstation. You must connect directly to the instance by using Microsoft SQL Server
Management Studio.
You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Step 1: New-AzureSqlServer –
Create a server.
Step 2: New-AzureRmSqlServerFirewallRule
New-AzureRmSqlServerFirewallRule creates a firewall rule for a SQL Database server.
Can be used to create a server firewall rule that allows access from the specified IP range.
Step 3: New-AzureRmSqlDatabase –
Example: Create a database on a specified server
PS C:>New-AzureRmSqlDatabase -ResourceGroupName “ResourceGroup01” -ServerName “Server01” -DatabaseName “Database01
References: https://docs.microsoft.com/en-us/azure/sql-database/scripts/sql-database-create-and-configure-database-powershell?toc=%2fpowershell%2fmodule%2ftoc.json
SIMULATION -
Use the following login credentials as needed:
Azure Username: xxxxx -
Azure Password: xxxxx -
The following information is for technical support purposes only:
Lab Instance: 10277521 -
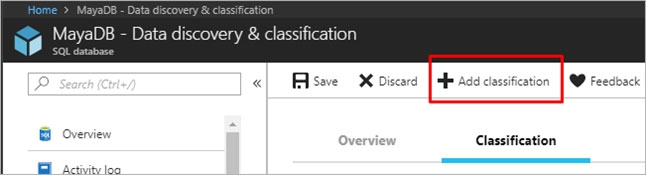
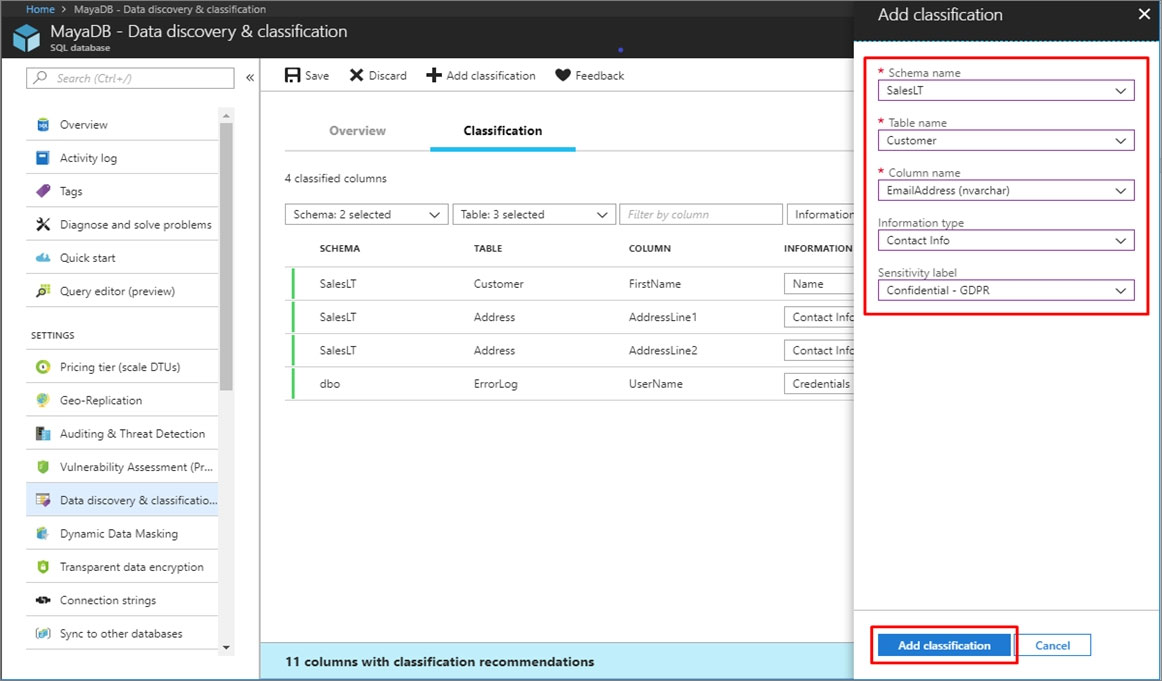
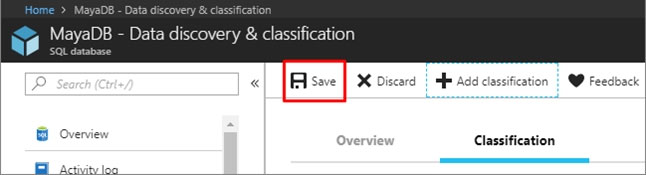
You need to classify the following information as Confidential:
✑ Database: db3
✑ Schema: SalesLT
✑ Table: Customer
Column: Phone Information -
✑ Type: Contact Info
To complete this task, sign in to the Azure portal.
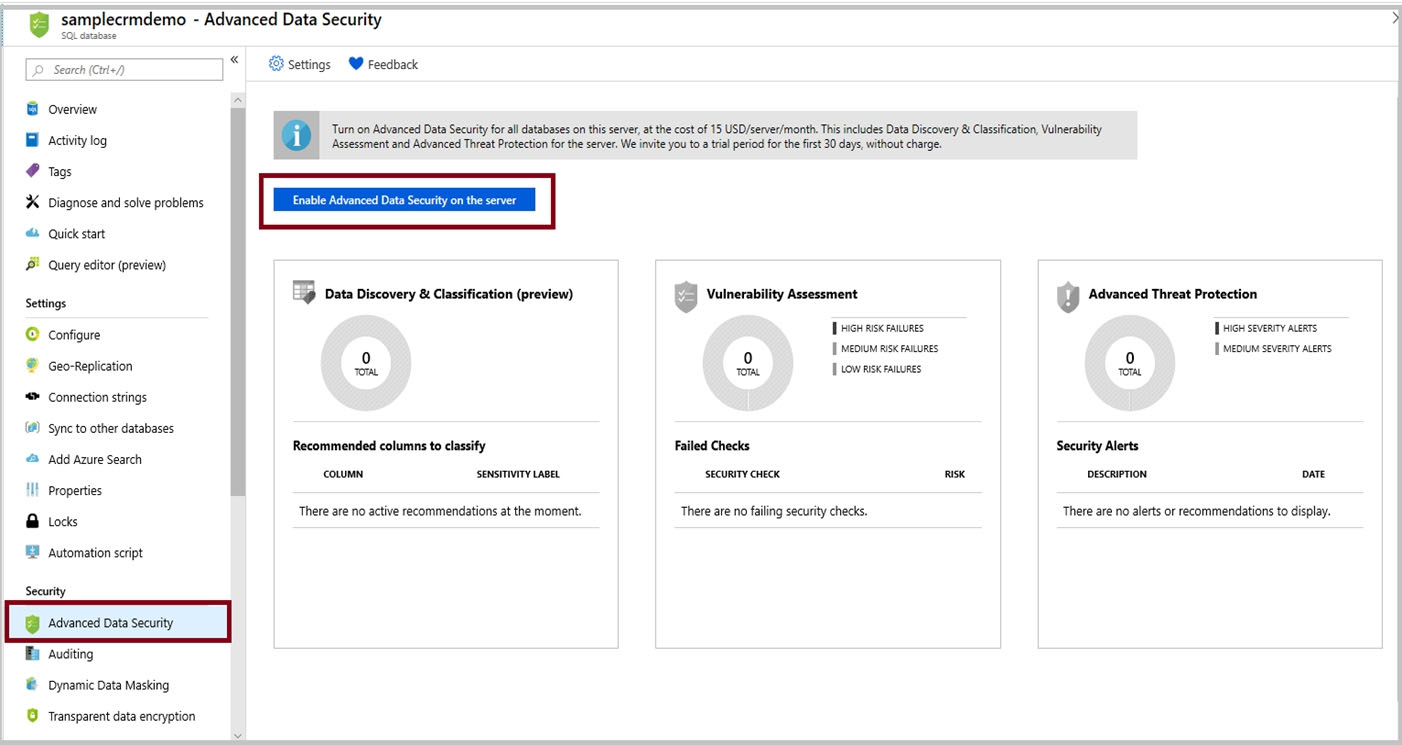
Suggested Answer: See the explanation below.
1. In Azure Portal, locate and select database db3.
2. Select Security and Advance Data Security, and Click Enable advanced Data Security Protection
3. Click the Data Discovery & Classification card.
4. Click on Add classification in the top menu of the window.
5. In the context window that opens, select the schema > table > column that you want to classify, and the information type and sensitivity label. Then click on the blue Add classification button at the bottom of the context window.
Select/enter the following –
✑ Schema: SalesLT
✑ Table: Customer
✑ Column: Phone Information
Information type: Contact Info –
6. To complete your classification and persistently label (tag) the database columns with the new classification metadata, click on Save in the top menu of the window.
References: alt=”Reference Image” />
3. Click the Data Discovery & Classification card.
4. Click on Add classification in the top menu of the window.
5. In the context window that opens, select the schema > table > column that you want to classify, and the information type and sensitivity label. Then click on the blue Add classification button at the bottom of the context window.
Select/enter the following –
✑ Schema: SalesLT
✑ Table: Customer
✑ Column: Phone Information
Information type: Contact Info –
6. To complete your classification and persistently label (tag) the database columns with the new classification metadata, click on Save in the top menu of the window.
<img src=”https://www.examtopics.com/assets/media/exam-media/03872/0032700002.jpg” alt=”Reference Image” />
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-data-discovery-and-classification
What should you implement to optimize SQL Database for Race Central to meet the technical requirements?
A. the sp_update_stats stored procedure
B. automatic tuning
C. Query Store
D. the dbcc checkdb command
Suggested Answer: A
Scenario: The query performance of Race Central must be stable, and the administrative time it takes to perform optimizations must be minimized. sp_updatestats updates query optimization statistics on a table or indexed view. By default, the query optimizer already updates statistics as necessary to improve the query plan; in some cases you can improve query performance by using UPDATE STATISTICS or the stored procedure sp_updatestats to update statistics more frequently than the default updates.
Incorrect Answers:
D: dbcc checkdchecks the logical and physical integrity of all the objects in the specified database
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-updatestats-transact-sql?view=sql-server-ver15
DRAG DROP -
Your company plans to create an event processing engine to handle streaming data from Twitter.
The data engineering team uses Azure Event Hubs to ingest the streaming data.
You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs.
Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Suggested Answer:
Step 1: Deploy the Azure Databricks service
Create an Azure Databricks workspace by setting up an Azure Databricks Service.
Step 2: Deploy a Spark cluster and then attach the required libraries to the cluster.
To create a Spark cluster in Databricks, in the Azure portal, go to the Databricks workspace that you created, and then select Launch Workspace.
Attach libraries to Spark cluster: you use the Twitter APIs to send tweets to Event Hubs. You also use the Apache Spark Event Hubs connector to read and write data into Azure Event Hubs. To use these APIs as part of your cluster, add them as libraries to Azure Databricks and associate them with your Spark cluster.
Step 3: Create and configure a Notebook that consumes the streaming data.
You create a notebook named ReadTweetsFromEventhub in Databricks workspace. ReadTweetsFromEventHub is a consumer notebook you use to read the tweets from Event Hubs.
References: https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs
DRAG DROP -
You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive and generates upwards of 20 terabytes (TB) of data.
Microsoft Azure SQL Databases must be provisioned.
✑ Database provisioning must maximize performance and minimize cost
✑ The daily sales for each region must be stored in an Azure SQL Database instance
✑ Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance
You need to provision Azure SQL database instances.
How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure SQL Database server and share a set number of resources at a set price. Elastic pools in Azure
SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application ג€” connectivity, query processing, and so on, work like any other SQL database.
Incorrect Answers:
Azure SQL Database Managed Instance: The managed instance deployment model is designed for customers looking to migrate a large number of apps from on- premises or IaaS, self-built, or ISV provided environment to fully managed PaaS cloud environment, with as low migration effort as possible.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale-faq
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure
Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one reference input, two queries, and four outputs.
Does this meet the goal?
HOTSPOT -
You have the following Azure Stream Analytics query.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Yes –
You can now use a new extension of Azure Stream Analytics SQL to specify the number of partitions of a stream when reshuffling the data.
The outcome is a stream that has the same partition scheme. Please see below for an example:
WITH step1 AS (SELECT * FROM [input1] PARTITION BY DeviceID INTO 10), step2 AS (SELECT * FROM [input2] PARTITION BY DeviceID INTO 10)
SELECT * INTO [output] FROM step1 PARTITION BY DeviceID UNION step2 PARTITION BY DeviceID
Note: The new extension of Azure Stream Analytics SQL includes a keyword INTO that allows you to specify the number of partitions for a stream when performing reshuffling using a PARTITION BY statement.
Box 2: Yes –
When joining two streams of data explicitly repartitioned, these streams must have the same partition key and partition count.
Box 3: Yes –
Streaming Units (SUs) represents the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job.
In general, the best practice is to start with 6 SUs for queries that don’t use PARTITION BY.
Here there are 10 partitions, so 6×10 = 60 SUs is good.
Note: Remember, Streaming Unit (SU) count, which is the unit of scale for Azure Stream Analytics, must be adjusted so the number of physical resources available to the job can fit the partitioned flow. In general, six SUs is a good number to assign to each partition. In case there are insufficient resources assigned to the job, the system will only apply the repartition if it benefits the job.
Reference: https://azure.microsoft.com/en-in/blog/maximize-throughput-with-repartitioning-in-azure-stream-analytics/ https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unit-consumption
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution will have a dedicated database for each customer organization.
Customer organizations have peak usage at different periods during the year.
Which two factors affect your costs when sizing the Azure SQL Database elastic pools? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. maximum data size
B. number of databases
C. eDTUs consumption
D. number of read operations
E. number of transactions
Suggested Answer: AC
A: With the vCore purchase model, in the General Purpose tier, you are charged for Premium blob storage that you provision for your database or elastic pool.
Storage can be configured between 5 GB and 4 TB with 1 GB increments. Storage is priced at GB/month.
C: In the DTU purchase model, elastic pools are available in basic, standard and premium service tiers. Each tier is distinguished primarily by its overall performance, which is measured in elastic Database Transaction Units (eDTUs).
References: https://azure.microsoft.com/en-in/pricing/details/sql-database/elastic/
Access Full DP-200 Dump Free
Looking for even more practice questions? Click here to access the complete DP-200 Dump Free collection, offering hundreds of questions across all exam objectives.
We regularly update our content to ensure accuracy and relevance—so be sure to check back for new material.
Begin your certification journey today with our DP-200 dump free questions — and get one step closer to exam success!














You need to ensure that users in the West US region can read data from a local copy of an Azure Cosmos DB database named cosmos10543936. To complete this task, sign in to the Azure portal. NOTE: This task might take several minutes to complete. You can perform other tasks while the task completes or end this section of the exam.
The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You increase the Request Units (RUs) for the database. Does this meet the goal?



You need to distribute the large fact table across multiple nodes to optimize performance of the table. Which technology should you use?
Which database and authorization types are used? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:




You need to implement Azure Stream Analytics to calculate the average fare per mile by driver. How should you configure the Stream Analytics input for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to query db3 to retrieve a list of sales customers. The query will retrieve several columns that include the email address of each sales customer. You need to modify db3 to ensure that a portion of the email addresses is hidden in the query results. To complete this task, sign in to the Azure portal.


Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You need to classify the following information as Confidential: ✑ Database: db3 ✑ Schema: SalesLT ✑ Table: Customer Column: Phone Information -
✑ Type: Contact Info To complete this task, sign in to the Azure portal.

How long will the logging data be retained?




For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:

