

DP-100 Practice Test Free – 50 Real Exam Questions to Boost Your Confidence
Preparing for the DP-100 exam? Start with our DP-100 Practice Test Free – a set of 50 high-quality, exam-style questions crafted to help you assess your knowledge and improve your chances of passing on the first try.
Taking a DP-100 practice test free is one of the smartest ways to:
- Get familiar with the real exam format and question types
- Evaluate your strengths and spot knowledge gaps
- Gain the confidence you need to succeed on exam day
Below, you will find 50 free DP-100 practice questions to help you prepare for the exam. These questions are designed to reflect the real exam structure and difficulty level. You can click on each Question to explore the details.
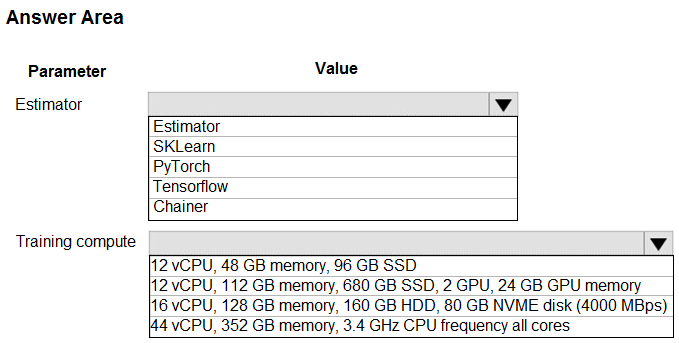
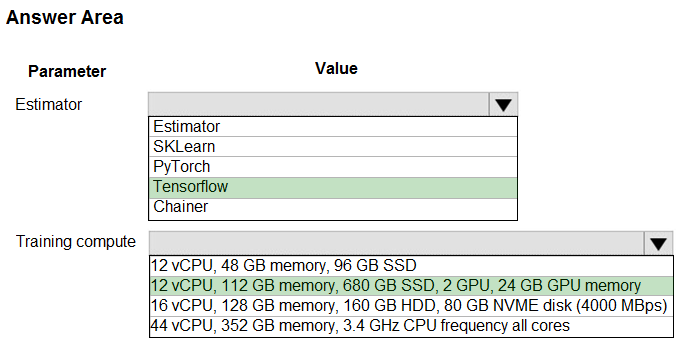
HOTSPOT - You create an Azure Machine Learning workspace and set up a development environment. You plan to train a deep neural network (DNN) by using the Tensorflow framework and by using estimators to submit training scripts. You must optimize computation speed for training runs. You need to choose the appropriate estimator to use as well as the appropriate training compute target configuration. Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You use Azure Machine Learning to train a model based on a dataset named dataset1. You define a dataset monitor and create a dataset named dataset2 that contains new data. You need to compare dataset1 and dataset2 by using the Azure Machine Learning SDK for Python. Which method of the DataDriftDetector class should you use?
A. run
B. get
C. backfill
D. update
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are a data scientist using Azure Machine Learning Studio. You need to normalize values to produce an output column into bins to predict a target column. Solution: Apply an Equal Width with Custom Start and Stop binning mode. Does the solution meet the goal?
A. Yes
B. No
You have a dataset that includes confidential data. You use the dataset to train a model. You must use a differential privacy parameter to keep the data of individuals safe and private. You need to reduce the effect of user data on aggregated results. What should you do?
A. Decrease the value of the epsilon parameter to reduce the amount of noise added to the data
B. Increase the value of the epsilon parameter to decrease privacy and increase accuracy
C. Decrease the value of the epsilon parameter to increase privacy and reduce accuracy
D. Set the value of the epsilon parameter to 1 to ensure maximum privacy
HOTSPOT - You have an Azure blob container that contains a set of TSV files. The Azure blob container is registered as a datastore for an Azure Machine Learning service workspace. Each TSV file uses the same data schema. You plan to aggregate data for all of the TSV files together and then register the aggregated data as a dataset in an Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python. You run the following code.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create an Azure Machine Learning pipeline named pipeline1 with two steps that contain Python scripts. Data processed by the first step is passed to the second step. You must update the content of the downstream data source of pipeline1 and run the pipeline again. You need to ensure the new run of pipeline1 fully processes the updated content. Solution: Change the value of the compute_target parameter of the PythonScriptStep object in the two steps. Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create a model to forecast weather conditions based on historical data. You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create a model to forecast weather conditions based on historical data. You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are analyzing a numerical dataset which contains missing values in several columns. You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set. You need to analyze a full dataset to include all values. Solution: Use the Last Observation Carried Forward (LOCF) method to impute the missing data points. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT
-
You create an Azure Machine Learning workspace.
You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log a table in the following format:
table = {
"col1" : [1, 2, 3],
"col2" : [4, 5, 6]
)
You need to complete the Python code to log the table.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


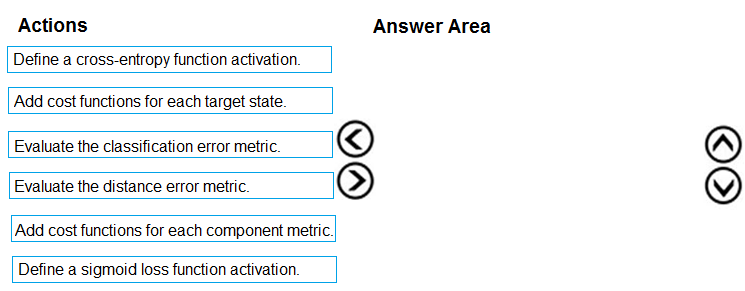
DRAG DROP - You need to define an evaluation strategy for the crowd sentiment models. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You write a Python script that processes data in a comma-separated values (CSV) file. You plan to run this script as an Azure Machine Learning experiment. The script loads the data and determines the number of rows it contains using the following code:You need to record the row count as a metric named row_count that can be returned using the get_metrics method of the Run object after the experiment run completes. Which code should you use?
A. run.upload_file(T3 row_count’, ‘./data.csv’)
B. run.log(‘row_count’, rows)
C. run.tag(‘row_count’, rows)
D. run.log_table(‘row_count’, rows)
E. run.log_row(‘row_count’, rows)
You create an Azure Machine learning workspace. You must use the Azure Machine Learning Python SDK v2 to define the search space for discrete hyperparameters. The hyperparameters must consist of a list of predetermined, comma-separated integer values. You need to import the class from the azure.ai.ml.sweep package used to create the list of values. Which class should you import?
A. Choice
B. Randint
C. Uniform
D. Normal
HOTSPOT - You create a Python script named train.py and save it in a folder named scripts. The script uses the scikit-learn framework to train a machine learning model. You must run the script as an Azure Machine Learning experiment on your local workstation. You need to write Python code to initiate an experiment that runs the train.py script. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You are performing feature engineering on a dataset. You must add a feature named CityName and populate the column value with the text London. You need to add the new feature to the dataset. Which Azure Machine Learning Studio module should you use?
A. Extract N-Gram Features from Text
B. Edit Metadata
C. Preprocess Text
D. Apply SQL Transformation
You manage an Azure Machine Learning workspace. You have an environment for training jobs which uses an existing Docker image. A new version of the Docker image is available. You need to use the latest version of the Docker image for the environment configuration by using the Azure Machine Learning SDK v2. What should you do?
A. Modify the conda_file to specify the new version of the Docker image.
B. Use the Environment class to create a new version of the environment.
C. Use the create_or_update method to change the tag of the image.
D. Change the description parameter of the environment configuration.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Machine Learning workspace. You plan to tune model hyperparameters by using a sweep job. You need to find a sampling method that supports early termination of low-performance jobs and continuous hyperparameters. Solution: Use the grid sampling method over the hyperparameter space. Does the solution meet the goal?
A. Yes
B. No
You use Azure Machine Learning Studio to build a machine learning experiment. You need to divide data into two distinct datasets. Which module should you use?
A. Assign Data to Clusters
B. Load Trained Model
C. Partition and Sample
D. Tune Model-Hyperparameters
A set of CSV files contains sales records. All the CSV files have the same data schema. Each CSV file contains the sales record for a particular month and has the filename sales.csv. Each file is stored in a folder that indicates the month and year when the data was recorded. The folders are in an Azure blob container for which a datastore has been defined in an Azure Machine Learning workspace. The folders are organized in a parent folder named sales to create the following hierarchical structure:At the end of each month, a new folder with that month's sales file is added to the sales folder. You plan to use the sales data to train a machine learning model based on the following requirements: ✑ You must define a dataset that loads all of the sales data to date into a structure that can be easily converted to a dataframe. ✑ You must be able to create experiments that use only data that was created before a specific previous month, ignoring any data that was added after that month. ✑ You must register the minimum number of datasets possible. You need to register the sales data as a dataset in Azure Machine Learning service workspace. What should you do?
A. Create a tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/sales.csv’ file every month. Register the dataset with the name sales_dataset each month, replacing the existing dataset and specifying a tag named month indicating the month and year it was registered. Use this dataset for all experiments.
B. Create a tabular dataset that references the datastore and specifies the path ‘sales/*/sales.csv’, register the dataset with the name sales_dataset and a tag named month indicating the month and year it was registered, and use this dataset for all experiments.
C. Create a new tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/sales.csv’ file every month. Register the dataset with the name sales_dataset_MM-YYYY each month with appropriate MM and YYYY values for the month and year. Use the appropriate month-specific dataset for experiments.
D. Create a tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/sales.csv’ file. Register the dataset with the name sales_dataset each month as a new version and with a tag named month indicating the month and year it was registered. Use this dataset for all experiments, identifying the version to be used based on the month tag as necessary.
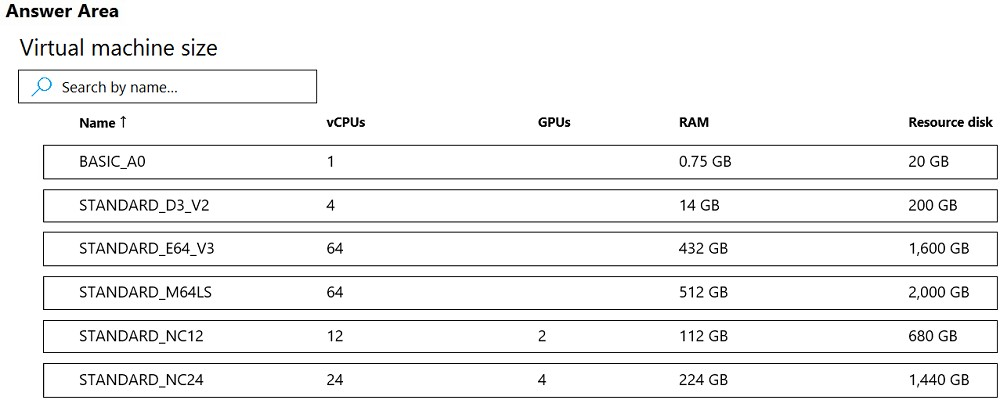
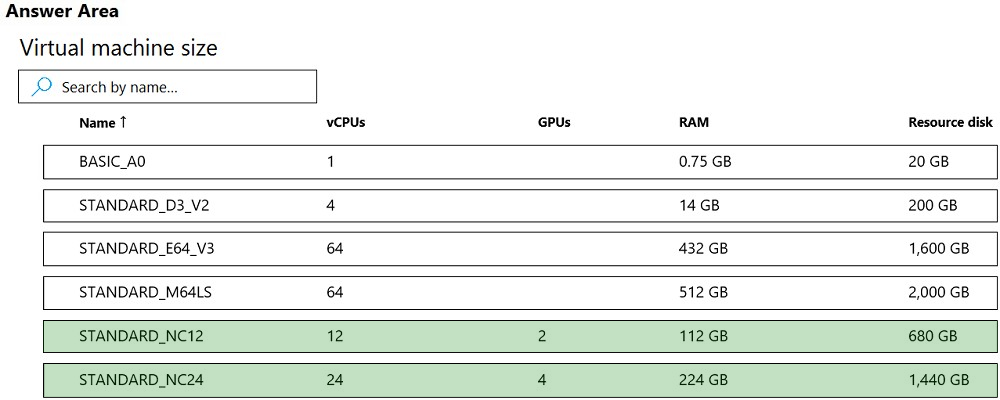
HOTSPOT - You are developing a deep learning model by using TensorFlow. You plan to run the model training workload on an Azure Machine Learning Compute Instance. You must use CUDA-based model training. You need to provision the Compute Instance. Which two virtual machines sizes can you use? To answer, select the appropriate virtual machine sizes in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You create a Python script that runs a training experiment in Azure Machine Learning. The script uses the Azure Machine Learning SDK for Python. You must add a statement that retrieves the names of the logs and outputs generated by the script. You need to reference a Python class object from the SDK for the statement. Which class object should you use?
A. Run
B. ScriptRunConfig
C. Workspace
D. Experiment
HOTSPOT - You are creating data wrangling and model training solutions in an Azure Machine Learning workspace. You must use the same Python notebook to perform both data wrangling and model training. You need to use the Azure Machine Learning Python SDK v2 to define and configure the Synapse Spark pool asynchronously in the workspace as dedicated compute. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You create an Azure Machine Learning workspace. You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log a list of numeral metrics. You need to implement a method to log a list of numeral metrics. Which method should you use?
A. mlflow.log_metric()
B. mlflow.log.batch()
C. mlflow.log_image()
D. mlflow.log_artifact()
You use the Azure Machine Learning designer to create and run a training pipeline. The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset. You need to publish the pipeline as a REST service that can be used for the nightly inferencing run. What should you do?
A. Create a batch inference pipeline
B. Set the compute target for the pipeline to an inference cluster
C. Create a real-time inference pipeline
D. Clone the pipeline
You are in the process of constructing a deep convolutional neural network (CNN). The CNN will be used for image classification. You notice that the CNN model you constructed displays hints of overfitting. You want to make sure that overfitting is minimized, and that the model is converged to an optimal fit. Which of the following is TRUE with regards to achieving your goal?
A. You have to add an additional dense layer with 512 input units, and reduce the amount of training data.
B. You have to add L1/L2 regularization, and reduce the amount of training data.
C. You have to reduce the amount of training data and make use of training data augmentation.
D. You have to add L1/L2 regularization, and make use of training data augmentation.
E. You have to add an additional dense layer with 512 input units, and add L1/L2 regularization.
You are developing a machine learning model. You must inference the machine learning model for testing. You need to use a minimal cost compute target. Which two compute targets should you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Azure Machine Learning Kubernetes
B. Azure Databricks
C. Remote VM
D. Local web service
E. Azure Container Instances
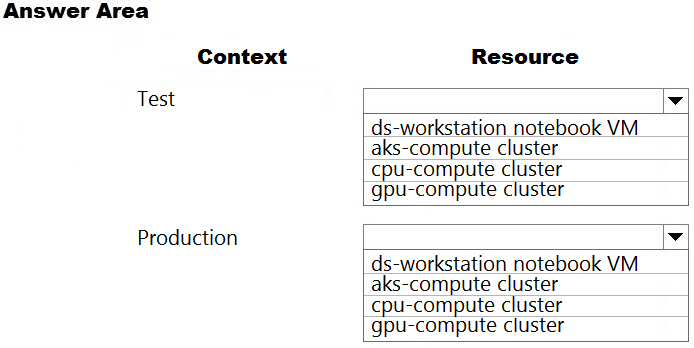
HOTSPOT - You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to develop a cross-platform mobile app that predicts the species of bird captured by app users. You must test and deploy the trained model as a web service. The deployed model must meet the following requirements: ✑ An authenticated connection must not be required for testing. ✑ The deployed model must perform with low latency during inferencing. ✑ The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application. You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted. Which compute resources should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You make use of Azure Machine Learning Studio to develop a linear regression model. You perform an experiment to assess various algorithms. Which of the following is an algorithm that reduces the variances between actual and predicted values?
A. Fast Forest Quantile Regression
B. Poisson Regression
C. Boosted Decision Tree Regression
D. Linear Regression
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. An IT department creates the following Azure resource groups and resources:The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace. You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed. You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics. Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace. Run the training script as an experiment on the aks- cluster compute target. Does the solution meet the goal?
A. Yes
B. No
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-class image classification deep learning model that uses a set of labeled bird photographs collected by experts. You have 100,000 photographs of birds. All photographs use the JPG format and are stored in an Azure blob container in an Azure subscription. You need to access the bird photograph files in the Azure blob container from the Azure Machine Learning service workspace that will be used for deep learning model training. You must minimize data movement. What should you do?
A. Create an Azure Data Lake store and move the bird photographs to the store.
B. Create an Azure Cosmos DB database and attach the Azure Blob containing bird photographs storage to the database.
C. Create and register a dataset by using TabularDataset class that references the Azure blob storage containing bird photographs.
D. Register the Azure blob storage containing the bird photographs as a datastore in Azure Machine Learning service.
E. Copy the bird photographs to the blob datastore that was created with your Azure Machine Learning service workspace.
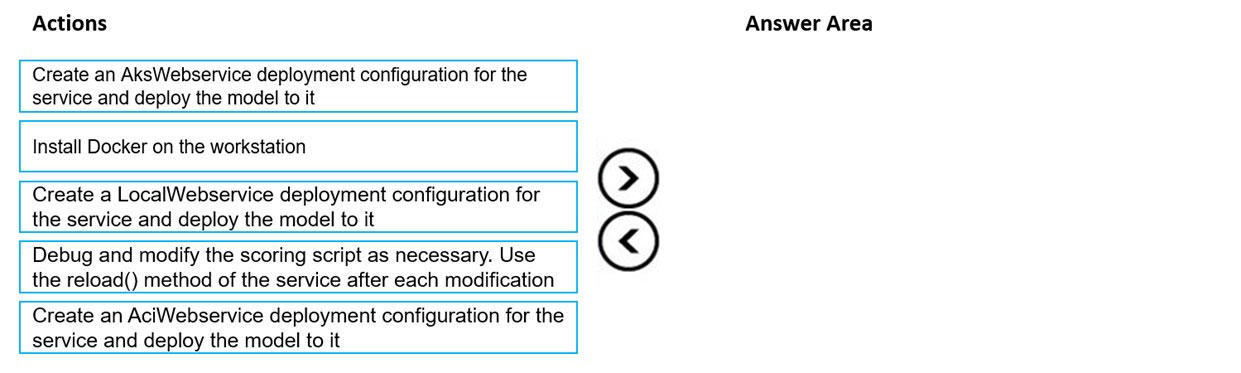
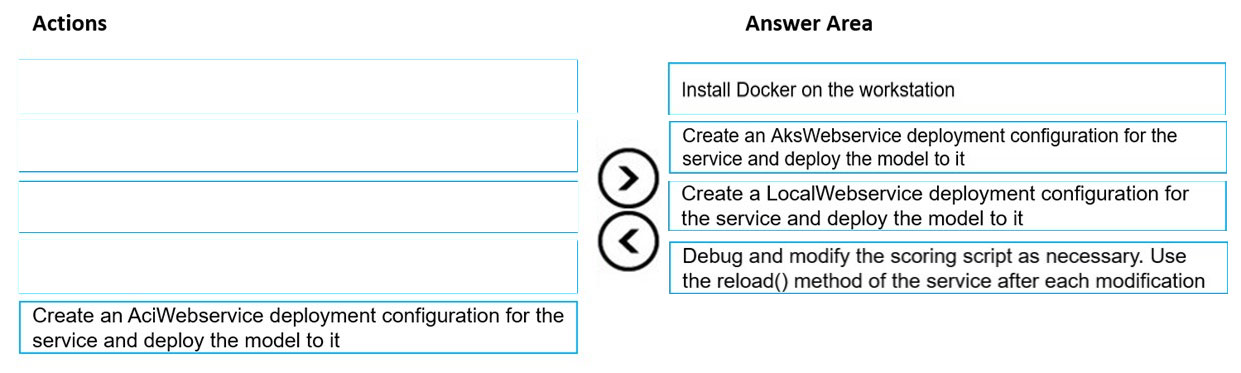
DRAG DROP - You train and register a model by using the Azure Machine Learning SDK on a local workstation. Python 3.6 and Visual Studio Code are installed on the workstation. When you try to deploy the model into production as an Azure Kubernetes Service (AKS)-based web service, you experience an error in the scoring script that causes deployment to fail. You need to debug the service on the local workstation before deploying the service to production. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a model to predict the price of a student's artwork depending on the following variables: the student's length of education, degree type, and art form. You start by creating a linear regression model. You need to evaluate the linear regression model. Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Accuracy, Precision, Recall, F1 score, and AUC. Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are a data scientist using Azure Machine Learning Studio. You need to normalize values to produce an output column into bins to predict a target column. Solution: Apply a Quantiles binning mode with a PQuantile normalization. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace. You add code that imports all relevant Python libraries. You must configure Bayesian sampling over the search space for the num_hidden_layers and batch_size hyperparameters. You need to complete the following Python code to configure Bayesian sampling. Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files: ✑ /data/2018/Q1.csv ✑ /data/2018/Q2.csv ✑ /data/2018/Q3.csv ✑ /data/2018/Q4.csv ✑ /data/2019/Q1.csv All files store data in the following format: id,f1,f2,I 1,1,2,0 2,1,1,1 3,2,1,0 4,2,2,1 You run the following code:You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
Solution: Run the following code:
Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You create an Azure Machine Learning workspace and load a Python training script named train.py in the src subfolder. The dataset used to train your model is available locally. You run the following script to train the model:Instructions: For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You manage an Azure Machine Learning workspace. You create an experiment named experiment by using the Azure Machine Learning Python SDK v2 and MLflow. You are reviewing the results of experiment by using the following code segment:For each of the following statements, select Yes if the statement is true. Otherwise, select No.


DRAG DROP - You are in the process of constructing a regression model. You would like to make it a Poisson regression model. To achieve your goal, the feature values need to meet certain conditions. Which of the following are relevant conditions with regards to the label data? Answer by dragging the correct options from the list to the answer area. Select and Place:


You use differential privacy to ensure your reports are private. The calculated value of the epsilon for your data is 1.8. You need to modify your data to ensure your reports are private. Which epsilon value should you accept for your data?
A. between 0 and 1
B. between 2 and 3
C. between 3 and 10
D. more than 10
You create a binary classification model. The model is registered in an Azure Machine Learning workspace. You use the Azure Machine Learning Fairness SDK to assess the model fairness. You develop a training script for the model on a local machine. You need to load the model fairness metrics into Azure Machine Learning studio. What should you do?
A. Implement the download_dashboard_by_upload_id function
B. Implement the create_group_metric_set function
C. Implement the upload_dashboard_dictionary function
D. Upload the training script
HOTSPOT - You are preparing to build a deep learning convolutional neural network model for image classification. You create a script to train the model using CUDA devices. You must submit an experiment that runs this script in the Azure Machine Learning workspace. The following compute resources are available: ✑ a Microsoft Surface device on which Microsoft Office has been installed. Corporate IT policies prevent the installation of additional software ✑ a Compute Instance named ds-workstation in the workspace with 2 CPUs and 8 GB of memory ✑ an Azure Machine Learning compute target named cpu-cluster with eight CPU-based nodes ✑ an Azure Machine Learning compute target named gpu-cluster with four CPU and GPU-based nodes You need to specify the compute resources to be used for running the code to submit the experiment, and for running the script in order to minimize model training time. Which resources should the data scientist use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


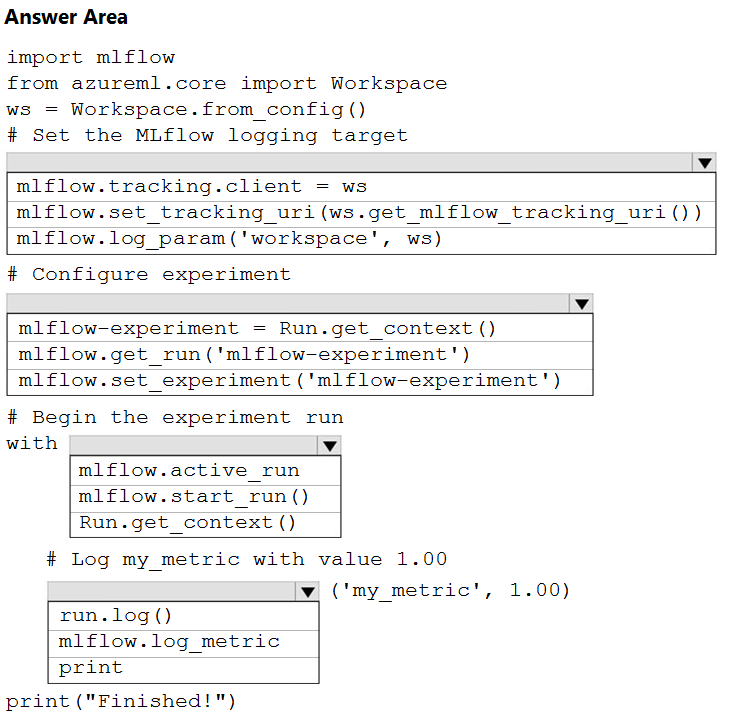
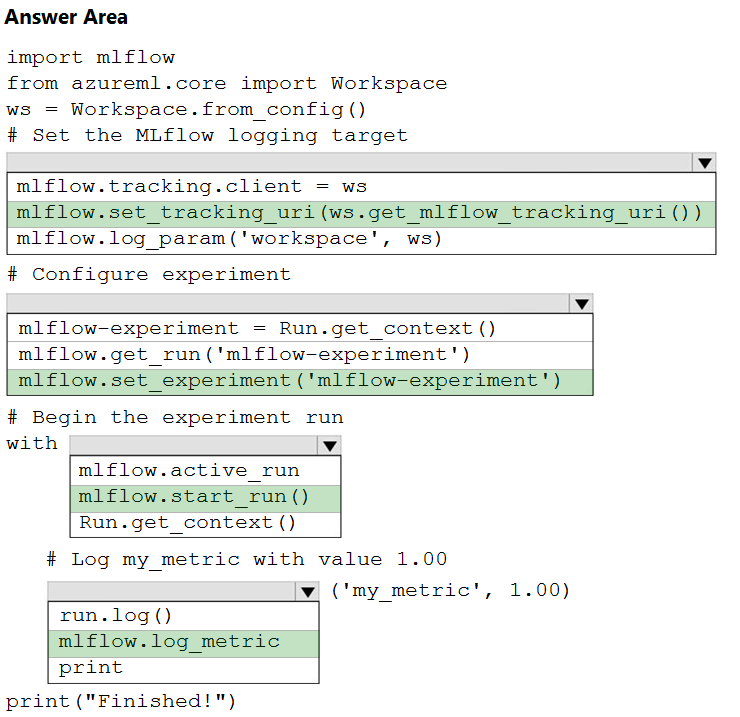
HOTSPOT - You are running Python code interactively in a Conda environment. The environment includes all required Azure Machine Learning SDK and MLflow packages. You must use MLflow to log metrics in an Azure Machine Learning experiment named mlflow-experiment. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a new experiment in Azure Machine Learning Studio. One class has a much smaller number of observations than the other classes in the training set. You need to select an appropriate data sampling strategy to compensate for the class imbalance. Solution: You use the Stratified split for the sampling mode. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You are authoring a pipeline by using the Azure Machine Learning SDK for Python. You implement code to import all relevant classes, configure the workspace, and define all pipeline steps. You need to initiate pipeline execution. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


DRAG DROP - You have an Azure Machine Learning workspace. You are running an experiment on your local computer. You need to ensure that you can use MLflow Tracking with Azure Machine Learning Python SDK v2 to store metrics and artifacts from your local experiment runs m the workspace. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


You have an Azure Machine Learning workspace. You plan to run a job to train a model as an MLflow model output. You need to specify the output mode of the MLflow model. Which three modes can you specify? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. rw_mount
B. ro_mount
C. upload
D. download
E. direct
You have an Azure Machine Learning workspace named WS1. You plan to use Azure Machine Learning SDK v2 to register a model as an asset in WS1 from an artifact generated by an MLflow run. The artifact resides in a named output of a job used for the model training. You need to identify the syntax of the path to reference the model when you register it. Which syntax should you use?
A. t//model/
B. azureml://registries
C. mlflow-model/
D. azureml://jobs/
HOTSPOT - You create an Azure Machine Learning workspace and install the MLflow library. You need to log different types of data by using the MLflow library. Which method should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Free Access Full DP-100 Practice Test Free Questions
If you’re looking for more DP-100 practice test free questions, click here to access the full DP-100 practice test.
We regularly update this page with new practice questions, so be sure to check back frequently.
Good luck with your DP-100 certification journey!