

DP-100 Practice Questions Free – 50 Exam-Style Questions to Sharpen Your Skills
Are you preparing for the DP-100 certification exam? Kickstart your success with our DP-100 Practice Questions Free – a carefully selected set of 50 real exam-style questions to help you test your knowledge and identify areas for improvement.
Practicing with DP-100 practice questions free gives you a powerful edge by allowing you to:
- Understand the exam structure and question formats
- Discover your strong and weak areas
- Build the confidence you need for test day success
Below, you will find 50 free DP-100 practice questions designed to match the real exam in both difficulty and topic coverage. They’re ideal for self-assessment or final review. You can click on each Question to explore the details.
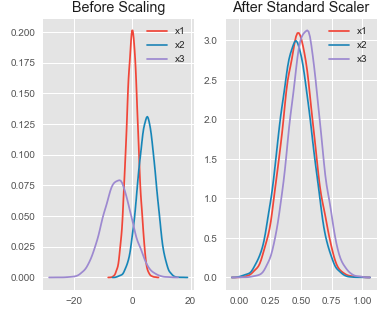
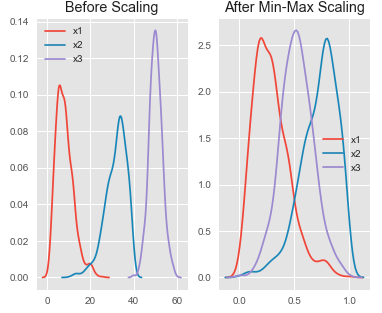
HOTSPOT - You are performing feature scaling by using the scikit-learn Python library for x.1 x2, and x3 features. Original and scaled data is shown in the following image.Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You are working on a classification task. You have a dataset indicating whether a student would like to play soccer and associated attributes. The dataset includes the following columns:You need to classify variables by type. Which variable should you add to each category? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You create an Azure Machine Learning workspace. You use Azure Machine Learning designer to create a pipeline within the workspace. You need to submit a pipeline run from the designer. What should you do first?
A. Create an experiment.
B. Create an attached compute resource.
C. Create a compute cluster.
D. Select a model.
You have an Azure Machine Learning workspace. You plan to tune a model hyperparameter when you train the model. You need to define a search space that returns a normally distributed value. Which parameter should you use?
A. QUniform
B. LogUniform
C. Uniform
D. LogNormal
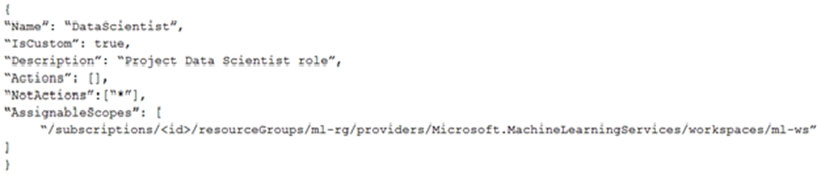
You create an Azure Machine Learning workspace. You must create a custom role named DataScientist that meets the following requirements: ✑ Role members must not be able to delete the workspace. ✑ Role members must not be able to create, update, or delete compute resources in the workspace. ✑ Role members must not be able to add new users to the workspace. You need to create a JSON file for the DataScientist role in the Azure Machine Learning workspace. The custom role must enforce the restrictions specified by the IT Operations team. Which JSON code segment should you use? A.B.
C.
D.
You need to implement a new cost factor scenario for the ad response models as illustrated in the performance curve exhibit. Which technique should you use?
A. Set the threshold to 0.5 and retrain if weighted Kappa deviates +/- 5% from 0.45.
B. Set the threshold to 0.05 and retrain if weighted Kappa deviates +/- 5% from 0.5.
C. Set the threshold to 0.2 and retrain if weighted Kappa deviates +/- 5% from 0.6.
D. Set the threshold to 0.75 and retrain if weighted Kappa deviates +/- 5% from 0.15.
You create an Azure Machine Learning workspace named workspaces. You create a Python SDK v2 notebook to perform custom model training in workspaces. You need to run the notebook from Azure Machine Learning Studio in workspaces. What should you provision first?
A. default storage account
B. real-time endpoint
C. Azure Machine Learning compute cluster
D. Azure Machine Learning compute instance
You use the following code to define the steps for a pipeline: from azureml.core import Workspace, Experiment, Run from azureml.pipeline.core import Pipeline from azureml.pipeline.steps import PythonScriptStep ws = Workspace.from_config() . . . step1 = PythonScriptStep(name="step1", ...) step2 = PythonScriptsStep(name="step2", ...) pipeline_steps = [step1, step2] You need to add code to run the steps. Which two code segments can you use to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. experiment = Experiment(workspace=ws, name=’pipeline-experiment’) run = experiment.submit(config=pipeline_steps)
B. run = Run(pipeline_steps)
C. pipeline = Pipeline(workspace=ws, steps=pipeline_steps) experiment = Experiment(workspace=ws, name=’pipeline-experiment’) run = experiment.submit(pipeline)
D. pipeline = Pipeline(workspace=ws, steps=pipeline_steps) run = pipeline.submit(experiment_name=’pipeline-experiment’)
You run a script as an experiment in Azure Machine Learning. You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run. You need to download the log files to a local folder for review. Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. run.get_details()
B. run.get_file_names()
C. run.get_metrics()
D. run.download_files(output_directory=’./runfiles’)
E. run.get_all_logs(destination=’./runlogs’)
You are creating a new experiment in Azure Machine Learning Studio. You have a small dataset that has missing values in many columns. The data does not require the application of predictors for each column. You plan to use the Clean Missing Data. You need to select a data cleaning method. Which method should you use?
A. Replace using Probabilistic PCA
B. Normalization
C. Synthetic Minority Oversampling Technique (SMOTE)
D. Replace using MICE
HOTSPOT - You create a new Azure Machine Learning workspace with a compute cluster. You need to create the compute cluster asynchronously by using the Azure Machine Learning Python SDK v2. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You create an Azure Machine Learning workspace. You plan to write an Azure Machine Learning SDK for Python v2 script that logs an image for an experiment. The logged image must be available from the images tab in Azure Machine Learning Studio. You need to complete the script. Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are performing feature engineering on a dataset. You must add a feature named CityName and populate the column value with the text London. You need to add the new feature to the dataset. Which Azure Machine Learning Studio module should you use?
A. Edit Metadata
B. Filter Based Feature Selection
C. Execute Python Script
D. Latent Dirichlet Allocation
HOTSPOT - You use Azure Machine Learning and SmartNoise Python libraries to implement a differential privacy solution to protect a dataset containing citizen demographics for the city of Seattle in the United States. The solution has the following requirements: • Allow for multiple queries targeting the mean and variance of the citizen’s age. • Ensure full plausible deniability. You need to define the query rate limit to minimize the risk of re-identification. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You create an Azure Machine Learning workspace and a dataset. The dataset includes age values for a large group of diabetes patients. You use the dp_mean function from the SmartNoise library to calculate the mean of the age value. You store the value in a variable named age_mean. You must output the value of the interval rage of released mean values that will be returned 95 percent of the time. You need to complete the code. Which code values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


DRAG DROP - You have been tasked with moving data into Azure Blob Storage for the purpose of supporting Azure Machine Learning. Which of the following can be used to complete your task? Answer by dragging the correct options from the list to the answer area. Select and Place:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create a model to forecast weather conditions based on historical data. You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are using Azure Machine Learning to run an experiment that trains a classification model. You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted. You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric. Solution: Run the following code:
Does the solution meet the goal?
A. Yes
B. No
You have recently concluded the construction of a binary classification machine learning model. You are currently assessing the model. You want to make use of a visualization that allows for precision to be used as the measurement for the assessment. Which of the following actions should you take?
A. You should consider using Venn diagram visualization.
B. You should consider using Receiver Operating Characteristic (ROC) curve visualization.
C. You should consider using Box plot visualization.
D. You should consider using the Binary classification confusion matrix visualization.
HOTSPOT - You use Azure Machine Learning to train a machine learning model. You use the following training script in Python to perform logging: import mlflow mlflow.log_metric(“accuracy", float(vel_accuracy)) You must use a Python script to define a sweep job. You need to provide the primary metric and goal you want hyperparameter tuning to optimize. How should you complete the Python script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are performing a filter-based feature selection for a dataset to build a multi-class classifier by using Azure Machine Learning Studio. The dataset contains categorical features that are highly correlated to the output label column. You need to select the appropriate feature scoring statistical method to identify the key predictors. Which method should you use?
A. Kendall correlation
B. Spearman correlation
C. Chi-squared
D. Pearson correlation
HOTSPOT - You load data from a notebook in an Azure Machine Learning workspace into a pandas dataframe. The data contains 10,000 records. Each record consists of 10 columns. You must identify the number of missing values in each of the columns. You need to complete the Python code that will return the number of missing values in each of the columns. Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You train a model and register it in your Azure Machine Learning workspace. You are ready to deploy the model as a real-time web service. You deploy the model to an Azure Kubernetes Service (AKS) inference cluster, but the deployment fails because an error occurs when the service runs the entry script that is associated with the model deployment. You need to debug the error by iteratively modifying the code and reloading the service, without requiring a re-deployment of the service for each code update. What should you do?
A. Modify the AKS service deployment configuration to enable application insights and re-deploy to AKS.
B. Create an Azure Container Instances (ACI) web service deployment configuration and deploy the model on ACI.
C. Add a breakpoint to the first line of the entry script and redeploy the service to AKS.
D. Create a local web service deployment configuration and deploy the model to a local Docker container.
E. Register a new version of the model and update the entry script to load the new version of the model from its registered path.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register a machine learning model. You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model. You need to deploy the web service. Solution: Create an AciWebservice instance. Set the value of the ssl_enabled property to True. Deploy the model to the service. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You create an Azure Machine Learning compute target named ComputeOne by using the STANDARD_D1 virtual machine image. ComputeOne is currently idle and has zero active nodes. You define a Python variable named ws that references the Azure Machine Learning workspace. You run the following Python code:For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


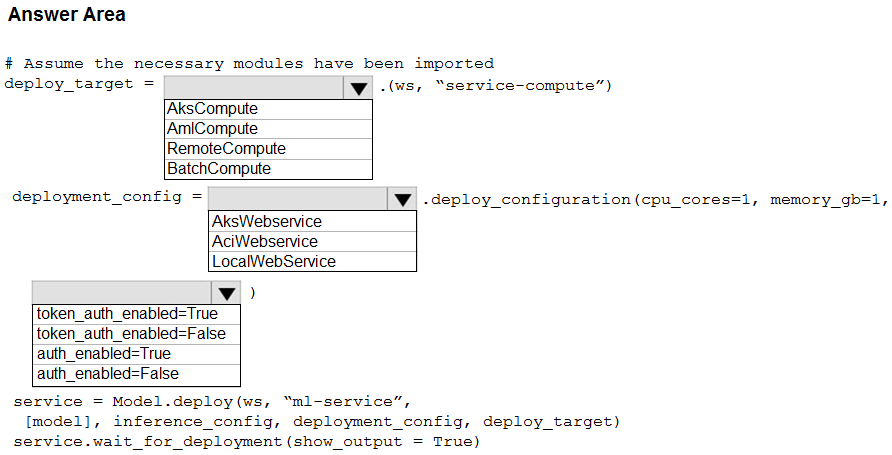
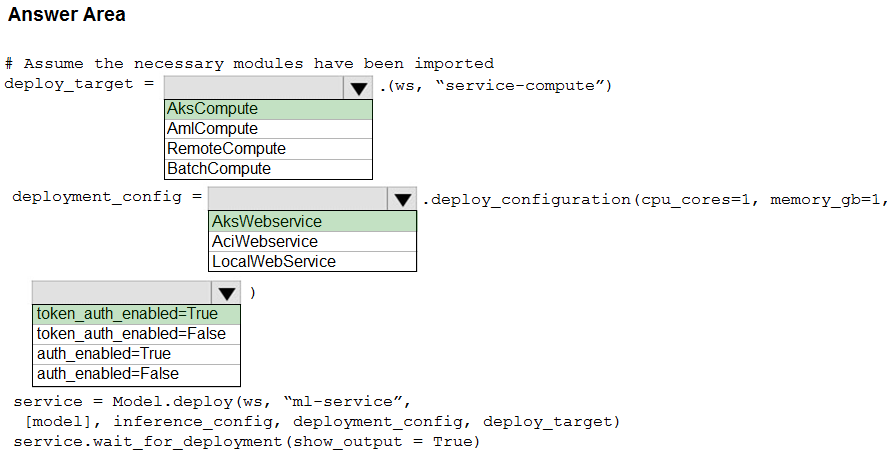
HOTSPOT - You use Azure Machine Learning to train and register a model. You must deploy the model into production as a real-time web service to an inference cluster named service-compute that the IT department has created in the Azure Machine Learning workspace. Client applications consuming the deployed web service must be authenticated based on their Azure Active Directory service principal. You need to write a script that uses the Azure Machine Learning SDK to deploy the model. The necessary modules have been imported. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You are developing deep learning models to analyze semi-structured, unstructured, and structured data types. You have the following data available for model building: ✑ Video recordings of sporting events ✑ Transcripts of radio commentary about events ✑ Logs from related social media feeds captured during sporting events You need to select an environment for creating the model. Which environment should you use?
A. Azure Cognitive Services
B. Azure Data Lake Analytics
C. Azure HDInsight with Spark MLib
D. Azure Machine Learning Studio
You are solving a classification task. The dataset is imbalanced. You need to select an Azure Machine Learning Studio module to improve the classification accuracy. Which module should you use?
A. Permutation Feature Importance
B. Filter Based Feature Selection
C. Fisher Linear Discriminant Analysis
D. Synthetic Minority Oversampling Technique (SMOTE)
You are authoring a notebook in Azure Machine Learning studio. You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only. You need to install the packages. Which magic function should you use?
A. !pip
B. %pip
C. !conda
D. %load
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are using Azure Machine Learning to run an experiment that trains a classification model. You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted. You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric. Solution: Run the following code:
Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You are using the Azure Machine Learning designer to transform a dataset by using an Execute Python Script component and custom code. You need to define the method signature for the Execute Python Script component and return value type. What should you define? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You are the owner of an Azure Machine Learning workspace. You must prevent the creation or deletion of compute resources by using a custom role. You must allow all other operations inside the workspace. You need to configure the custom role. How should you complete the configuration? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - Complete the sentence by selecting the correct option in the answer area. Hot Area:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a model to predict the price of a student's artwork depending on the following variables: the student's length of education, degree type, and art form. You start by creating a linear regression model. You need to evaluate the linear regression model. Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Accuracy, Precision, Recall, F1 score, and AUC. Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You use Azure Machine Learning designer to load the following datasets into an experiment: Dataset1 -Dataset2 -
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets. Solution: Use the Execute Python Script module. Does the solution meet the goal?
A. Yes
B. No
You use the Azure Machine Learning service to create a tabular dataset named training_data. You plan to use this dataset in a training script.
You create a variable that references the dataset using the following code: training_ds = workspace.datasets.get("training_data")
You define an estimator to run the script.
You need to set the correct property of the estimator to ensure that your script can access the training_data dataset.
Which property should you set?
A. environment_definition = {“training_data”:training_ds}
B. inputs = [training_ds.as_named_input(‘training_ds’)]
C. script_params = {“–training_ds”:training_ds}
D. source_directory = training_ds
DRAG DROP - You create a multi-class image classification deep learning model. The model must be retrained monthly with the new image data fetched from a public web portal. You create an Azure Machine Learning pipeline to fetch new data, standardize the size of images, and retrain the model. You need to use the Azure Machine Learning Python SDK v2 to configure the schedule for the pipeline. The schedule should be defined by using the frequency and interval properties, with frequency set to “month" and interval set to "1". Which three classes should you instantiate in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You create a binary classification model. You need to evaluate the model performance. Which two metrics can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. relative absolute error
B. precision
C. accuracy
D. mean absolute error
E. coefficient of determination
You use the following code to run a script as an experiment in Azure Machine Learning:You must identify the output files that are generated by the experiment run. You need to add code to retrieve the output file names. Which code segment should you add to the script?
A. files = run.get_properties()
B. files= run.get_file_names()
C. files = run.get_details_with_logs()
D. files = run.get_metrics()
E. files = run.get_details()
You use the Azure Machine Learning SDK for Python v1 and notebooks to train a model. You create a compute target, an environment, and a training script by using Python code. You need to prepare information to submit a training run. Which class should you use?
A. ScriptRun
B. ScriptRunConfig
C. RunConfiguration
D. Run
You retrain an existing model. You need to register the new version of a model while keeping the current version of the model in the registry. What should you do?
A. Register a model with a different name from the existing model and a custom property named version with the value 2.
B. Register the model with the same name as the existing model.
C. Save the new model in the default datastore with the same name as the existing model. Do not register the new model.
D. Delete the existing model and register the new one with the same name.
HOTSPOT - You have an Azure Machine Learning workspace. You run the following code in a Python environment in which the configuration file for your workspace has been downloaded.Instructions: For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


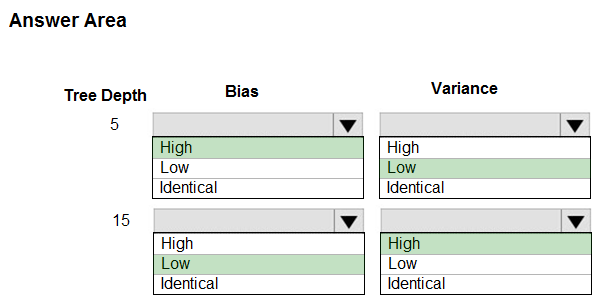
HOTSPOT - You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10. You need to select the bias and variance properties of the model with varying tree depth values. Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area. Hot Area:
You use Azure Machine Learning studio to analyze a dataset containing a decimal column named column1. You need to verify that the column1 values are normally distributed. Which statistic should you use?
A. Max
B. Type
C. Profile
D. Mean
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have the following Azure subscriptions and Azure Machine Learning service workspaces:You need to obtain a reference to the ml-project workspace. Solution: Run the following Python code:
Does the solution meet the goal?
A. Yes
B. No
You train a machine learning model. You must deploy the model as a real-time inference service for testing. The service requires low CPU utilization and less than 48 MB of RAM. The compute target for the deployed service must initialize automatically while minimizing cost and administrative overhead. Which compute target should you use?
A. Azure Container Instance (ACI)
B. attached Azure Databricks cluster
C. Azure Kubernetes Service (AKS) inference cluster
D. Azure Machine Learning compute cluster
HOTSPOT - You create an Azure Machine Learning workspace. You use the Azure Machine Learning Python SDK v2 to create a compute cluster. The compute cluster must run a training script. Costs associated with running the training script must be minimized. You need to complete the Python script to create the compute cluster. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


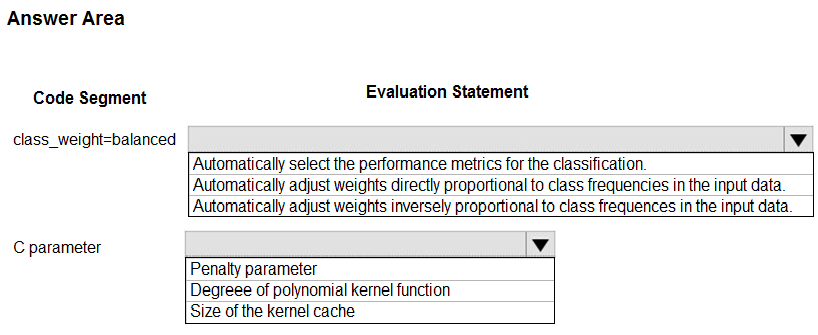
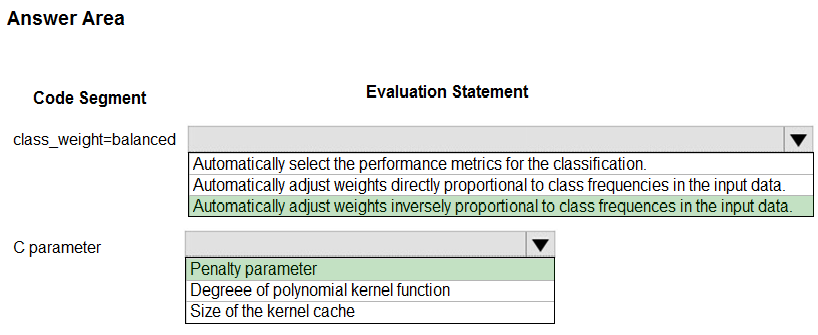
HOTSPOT - You are using C-Support Vector classification to do a multi-class classification with an unbalanced training dataset. The C-Support Vector classification using Python code shown below:You need to evaluate the C-Support Vector classification code. Which evaluation statement should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Free Access Full DP-100 Practice Questions Free
Want more hands-on practice? Click here to access the full bank of DP-100 practice questions free and reinforce your understanding of all exam objectives.
We update our question sets regularly, so check back often for new and relevant content.
Good luck with your DP-100 certification journey!