

DP-100 Mock Test Free – 50 Realistic Questions to Prepare with Confidence.
Getting ready for your DP-100 certification exam? Start your preparation the smart way with our DP-100 Mock Test Free – a carefully crafted set of 50 realistic, exam-style questions to help you practice effectively and boost your confidence.
Using a mock test free for DP-100 exam is one of the best ways to:
- Familiarize yourself with the actual exam format and question style
- Identify areas where you need more review
- Strengthen your time management and test-taking strategy
Below, you will find 50 free questions from our DP-100 Mock Test Free resource. These questions are structured to reflect the real exam’s difficulty and content areas, helping you assess your readiness accurately.
You create a binary classification model by using Azure Machine Learning Studio. You must tune hyperparameters by performing a parameter sweep of the model. The parameter sweep must meet the following requirements: ✑ iterate all possible combinations of hyperparameters ✑ minimize computing resources required to perform the sweep You need to perform a parameter sweep of the model. Which parameter sweep mode should you use?
A. Random sweep
B. Sweep clustering
C. Entire grid
D. Random grid
You need to implement a model development strategy to determine a user's tendency to respond to an ad. Which technique should you use?
A. Use a Relative Expression Split module to partition the data based on centroid distance.
B. Use a Relative Expression Split module to partition the data based on distance travelled to the event.
C. Use a Split Rows module to partition the data based on distance travelled to the event.
D. Use a Split Rows module to partition the data based on centroid distance.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Machine Learning workspace. You connect to a terminal session from the Notebooks page in Azure Machine Learning studio. You plan to add a new Jupyter kernel that will be accessible from the same terminal session. You need to perform the task that must be completed before you can add the new kernel. Solution: Create an environment. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - Complete the sentence by selecting the correct option in the answer area. Hot Area:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a new experiment in Azure Machine Learning Studio. One class has a much smaller number of observations than the other classes in the training set. You need to select an appropriate data sampling strategy to compensate for the class imbalance. Solution: You use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode. Does the solution meet the goal?
A. Yes
B. No
You create a batch inference pipeline by using the Azure ML SDK. You run the pipeline by using the following code: from azureml.pipeline.core import Pipeline from azureml.core.experiment import Experiment pipeline = Pipeline(workspace=ws, steps=[parallelrun_step]) pipeline_run = Experiment(ws, 'batch_pipeline').submit(pipeline) You need to monitor the progress of the pipeline execution. What are two possible ways to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Run the following code in a notebook:

B. Use the Inference Clusters tab in Machine Learning Studio.
C. Use the Activity log in the Azure portal for the Machine Learning workspace.
D. Run the following code in a notebook:

E. Run the following code and monitor the console output from the PipelineRun object:

You use the Azure Machine Learning designer to create and run a training pipeline. The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset. You need to publish the pipeline as a REST service that can be used for the nightly inferencing run. What should you do?
A. Create a batch inference pipeline
B. Set the compute target for the pipeline to an inference cluster
C. Create a real-time inference pipeline
D. Clone the pipeline
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder. You must run the script as an Azure ML experiment on a compute cluster named aml-compute. You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml- compute that references the target compute cluster. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
DRAG DROP - You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. You must register datastores in workspace1 for Azure Blob storage and Azure Files storage to meet the following requirements: • Azure Active Directory (Azure AD) authentication must be used for access to storage when possible. • Credentials and secrets stored in workspace1 must be valid for a specified time period when accessing Azure Files storage. You need to configure a security access method used to register the Azure Blob and Azure Files storage in workspace1. Which security access method should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. You create a General Purpose v2 Azure storage account named mlstorage1. The storage account includes a publicly accessible container named mlcontainer1. The container stores 10 blobs with files in the CSV format. You must develop Python SDK v2 code to create a data asset referencing all blobs in the container named mlcontainer1. You need to complete the Python SDK v2 code. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


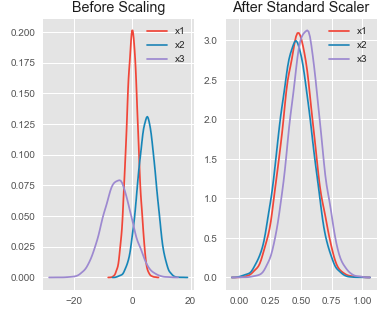
HOTSPOT - You are analyzing the asymmetry in a statistical distribution. The following image contains two density curves that show the probability distribution of two datasets.Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


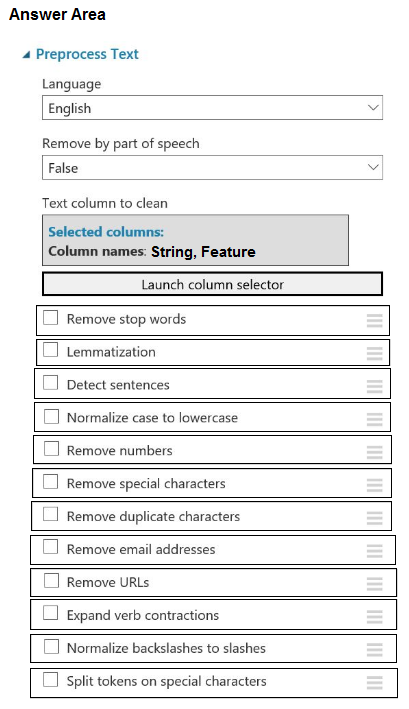
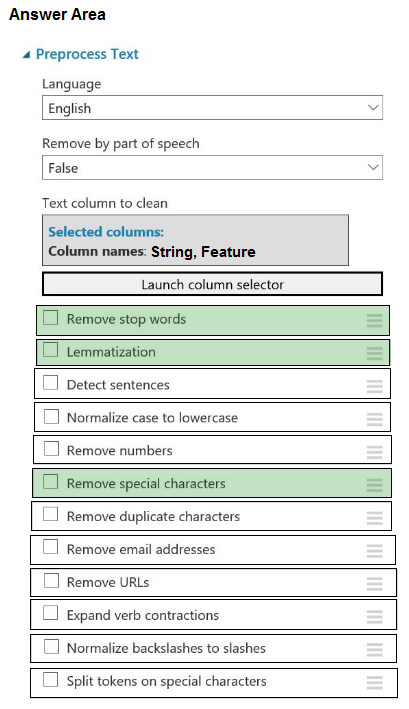
HOTSPOT - You plan to preprocess text from CSV files. You load the Azure Machine Learning Studio default stop words list. You need to configure the Preprocess Text module to meet the following requirements: ✑ Ensure that multiple related words from a single canonical form. ✑ Remove pipe characters from text. Remove words to optimize information retrieval.Which three options should you select? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
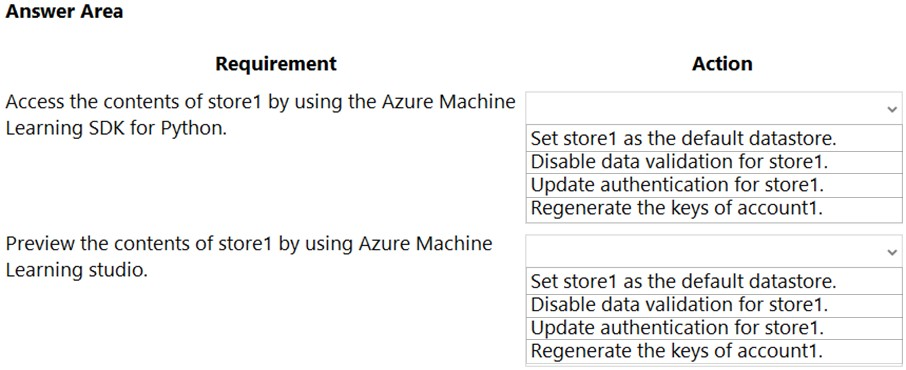
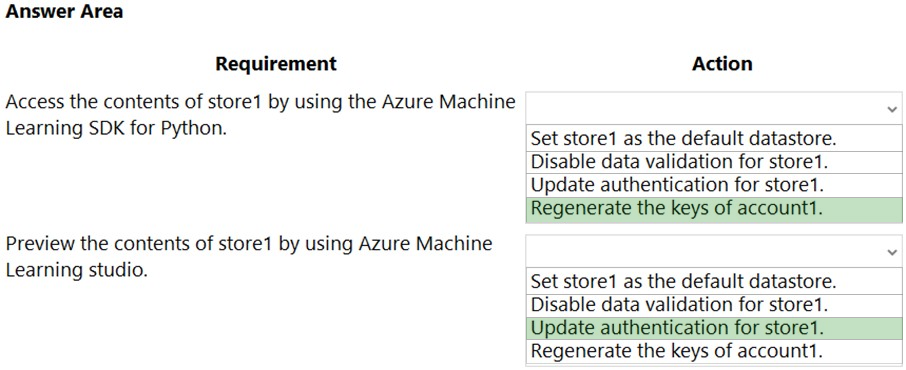
HOTSPOT - You have an Azure Machine Learning workspace named workspace1 that is accessible from a public endpoint. The workspace contains an Azure Blob storage datastore named store1 that represents a blob container in an Azure storage account named account1. You configure workspace1 and account1 to be accessible by using private endpoints in the same virtual network. You must be able to access the contents of store1 by using the Azure Machine Learning SDK for Python. You must be able to preview the contents of store1 by using Azure Machine Learning studio. You need to configure store1. What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have a dataset that contains salary information for users. You plan to generate an aggregate salary report that shows average salaries by city. Privacy of individuals must be preserved without impacting accuracy, completeness, or reliability of the data. The aggregation must be statistically consistent with the distribution of the original data. You must return an approximation of the data instead of the raw data. You need to apply a differential privacy approach. What should you do?
A. Add noise to the salary data during the analysis
B. Encrypt the salary data before analysis
C. Remove the salary data
D. Convert the salary data to the average column value
You run Azure Machine Learning training experiments. The training scripts directory contains 100 files that includes a file named .amlignore. The directory also contains subdirectories named ./outputs and ./logs. There are 20 files in the training scripts directory that must be excluded from the snapshot to the compute targets. You create a file named .gitignore in the root of the directory. You add the names of the 20 files to the .gitignore file. These 20 files continue to be copied to the compute targets. You need to exclude the 20 files. What should you do?
A. Copy the contents of the file named .gitignore to the file named .amlignore.
B. Move the file named .gitignore to the ./outputs directory.
C. Move the file named .gitignore to the ./logs directory.
D. Add the contents of the file named .amlignore to the file named .gitignore.
You use Azure Machine Learning studio to analyze a dataset containing a decimal column named column1. You need to verify that the column1 values are normally distributed. Which statistic should you use?
A. Max
B. Type
C. Profile
D. Mean
You use the following code to run a script as an experiment in Azure Machine Learning:You must identify the output files that are generated by the experiment run. You need to add code to retrieve the output file names. Which code segment should you add to the script?
A. files = run.get_properties()
B. files= run.get_file_names()
C. files = run.get_details_with_logs()
D. files = run.get_metrics()
E. files = run.get_details()
DRAG DROP - You create a multi-class image classification deep learning model. The model must be retrained monthly with the new image data fetched from a public web portal. You create an Azure Machine Learning pipeline to fetch new data, standardize the size of images, and retrain the model. You need to use the Azure Machine Learning Python SDK v2 to configure the schedule for the pipeline. The schedule should be defined by using the frequency and interval properties, with frequency set to “month" and interval set to "1". Which three classes should you instantiate in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You are solving a classification task. You must evaluate your model on a limited data sample by using k-fold cross-validation. You start by configuring a k parameter as the number of splits. You need to configure the k parameter for the cross-validation. Which value should you use?
A. k=0.5
B. k=0.01
C. k=5
D. k=1
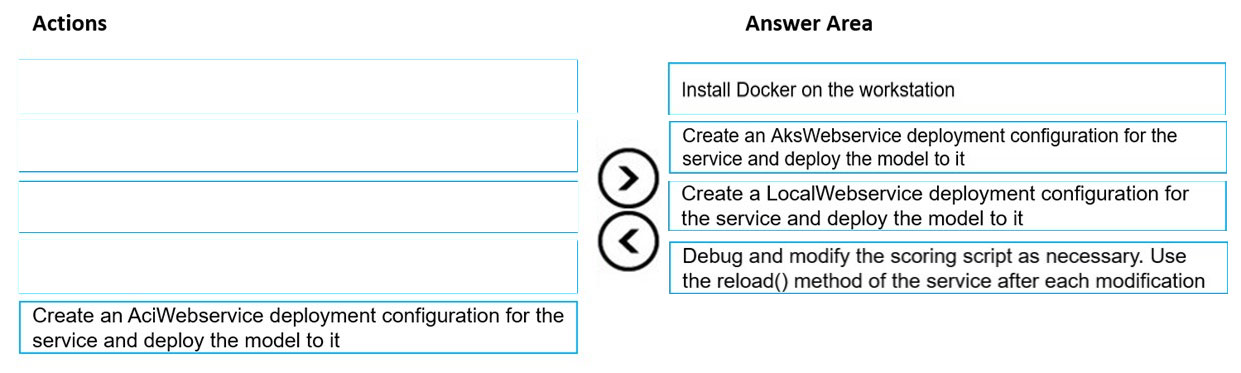
DRAG DROP - You train and register a model by using the Azure Machine Learning SDK on a local workstation. Python 3.6 and Visual Studio Code are installed on the workstation. When you try to deploy the model into production as an Azure Kubernetes Service (AKS)-based web service, you experience an error in the scoring script that causes deployment to fail. You need to debug the service on the local workstation before deploying the service to production. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
You need to implement a scaling strategy for the local penalty detection data. Which normalization type should you use?
A. Streaming
B. Weight
C. Batch
D. Cosine
HOTSPOT - You are running a training experiment on remote compute in Azure Machine Learning (ML) by using Azure ML SDK v2 for Python. The experiment is configured to use a conda environment that includes all required packages. You must track metrics generated in the experiment. You need to complete the script for the experiment. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Machine Learning workspace named WS1. You plan to use Azure Machine Learning SDK v2 to register a model as an asset in WS1 from an artifact generated by an MLflow run. The artifact resides in a named output of a job used for the model training. You need to identify the syntax of the path to reference the model when you register it. Which syntax should you use?
A. t//model/
B. azureml://registries
C. mlflow-model/
D. azureml://jobs/
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register an Azure Machine Learning model. You plan to deploy the model to an online endpoint. You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model. Solution: Create a managed online endpoint with the default authentication settings. Deploy the model to the online endpoint. Does the solution meet the goal?
A. Yes
B. No
You develop a machine learning project on a local machine. The project uses the Azure Machine Learning SDK for Python. You use Git as version control for scripts. You submit a training run that returns a Run object. You need to retrieve the active Git branch for the training run. Which two code segments should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. details = run.get_environment()
B. details.properties[‘azureml.git.branch’]
C. details.properties[‘azureml.git.commit’]
D. details = run.get_details()
HOTSPOT - You create an Azure Machine Learning model to include model files and a scoring script. You must deploy the model. The deployment solution must meet the following requirements: • Provide near real-time inferencing. • Enable endpoint and deployment level cost estimates. • Support logging to Azure Log Analytics. You need to configure the deployment solution. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You plan to run a Python script as an Azure Machine Learning experiment. The script must read files from a hierarchy of folders. The files will be passed to the script as a dataset argument. You must specify an appropriate mode for the dataset argument. Which two modes can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. to_pandas_dataframe()
B. as_download()
C. as_upload()
D. as_mount()
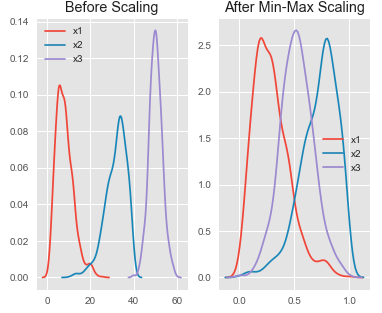
HOTSPOT - You are performing feature scaling by using the scikit-learn Python library for x.1 x2, and x3 features. Original and scaled data is shown in the following image.Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


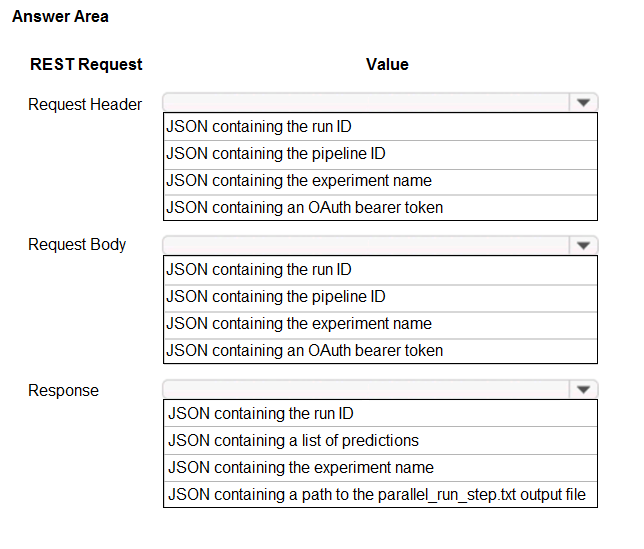
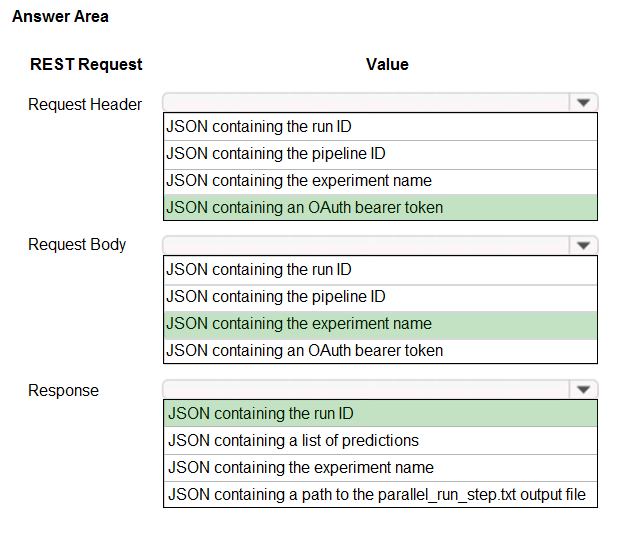
HOTSPOT - You publish a batch inferencing pipeline that will be used by a business application. The application developers need to know which information should be submitted to and returned by the REST interface for the published pipeline. You need to identify the information required in the REST request and returned as a response from the published pipeline. Which values should you use in the REST request and to expect in the response? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
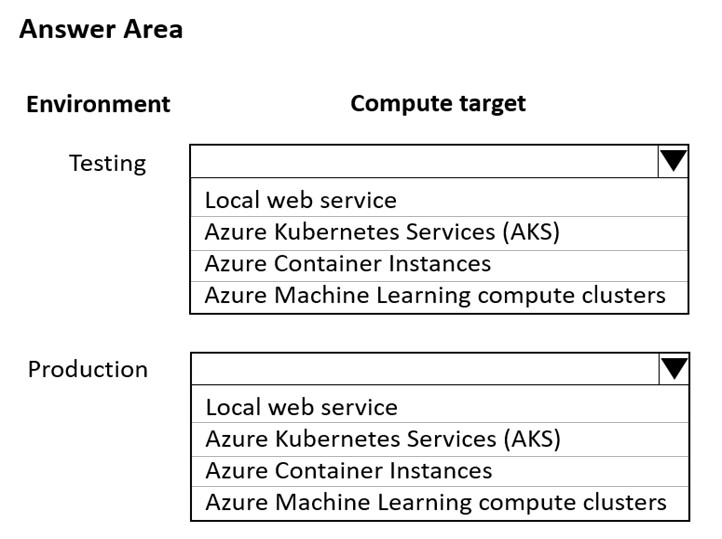
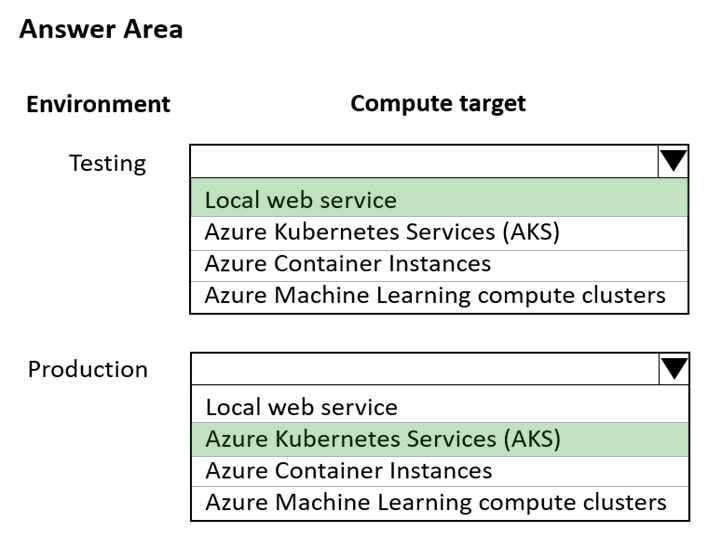
HOTSPOT - You are using an Azure Machine Learning workspace. You set up an environment for model testing and an environment for production. The compute target for testing must minimize cost and deployment efforts. The compute target for production must provide fast response time, autoscaling of the deployed service, and support real-time inferencing. You need to configure compute targets for model testing and production. Which compute targets should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You write five Python scripts that must be processed in the order specified in Exhibit A `" which allows the same modules to run in parallel, but will wait for modules with dependencies. You must create an Azure Machine Learning pipeline using the Python SDK, because you want to script to create the pipeline to be tracked in your version control system. You have created five PythonScriptSteps and have named the variables to match the module names.You need to create the pipeline shown. Assume all relevant imports have been done. Which Python code segment should you use? A.
B.
C.
D.

HOTSPOT - You manage an Azure Machine Learning workspace. You must define the execution environments for your jobs and encapsulate the dependencies for your code. You need to configure the environment from a Docker build context. How should you complete the code segment? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You have a feature set containing the following numerical features: X, Y, and Z. The Poisson correlation coefficient (r-value) of X, Y, and Z features is shown in the following image:Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


You are analyzing a dataset containing historical data from a local taxi company. You are developing a regression model. You must predict the fare of a taxi trip. You need to select performance metrics to correctly evaluate the regression model. Which two metrics can you use? Each correct answer presents a complete solution? NOTE: Each correct selection is worth one point.
A. a Root Mean Square Error value that is low
B. an R-Squared value close to 0
C. an F1 score that is low
D. an R-Squared value close to 1
E. an F1 score that is high
F. a Root Mean Square Error value that is high
You create an Azure Machine learning workspace. You must use the Azure Machine Learning Python SDK v2 to define the search space for discrete hyperparameters. The hyperparameters must consist of a list of predetermined, comma-separated integer values. You need to import the class from the azure.ai.ml.sweep package used to create the list of values. Which class should you import?
A. Choice
B. Randint
C. Uniform
D. Normal
HOTSPOT - You manage an Azure Machine Learning workspace named workspace1 with a compute instance named compute1. You must remove a kernel named kernel1 from compute1. You connect to compute1 by using a terminal window from workspace1. You need to enter a command in the terminal window to remove kernel. Which command should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You manage an Azure Machine Learning workspace. You develop a machine learning model. You must deploy the model to use a low-priority VM with a pricing discount. You need to deploy the model. Which compute target should you use?
A. Azure Kubernetes Service (AKS)
B. Azure Machine Learning compute clusters
C. Azure Container Instances (ACI)
D. Local deployment
You create a machine learning model by using the Azure Machine Learning designer. You publish the model as a real-time service on an Azure Kubernetes Service (AKS) inference compute cluster. You make no changes to the deployed endpoint configuration. You need to provide application developers with the information they need to consume the endpoint. Which two values should you provide to application developers? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. The name of the AKS cluster where the endpoint is hosted.
B. The name of the inference pipeline for the endpoint.
C. The URL of the endpoint.
D. The run ID of the inference pipeline experiment for the endpoint.
E. The key for the endpoint.
DRAG DROP - You provision an Azure Machine Learning workspace in a new Azure subscription. You need to attach Azure Databricks as a compute resource from the Azure Machine Learning workspace. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


HOTSPOT - You write code to retrieve an experiment that is run from your Azure Machine Learning workspace. The run used the model interpretation support in Azure Machine Learning to generate and upload a model explanation. Business managers in your organization want to see the importance of the features in the model. You need to print out the model features and their relative importance in an output that looks similar to the following.How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


DRAG DROP - You have been tasked with moving data into Azure Blob Storage for the purpose of supporting Azure Machine Learning. Which of the following can be used to complete your task? Answer by dragging the correct options from the list to the answer area. Select and Place:


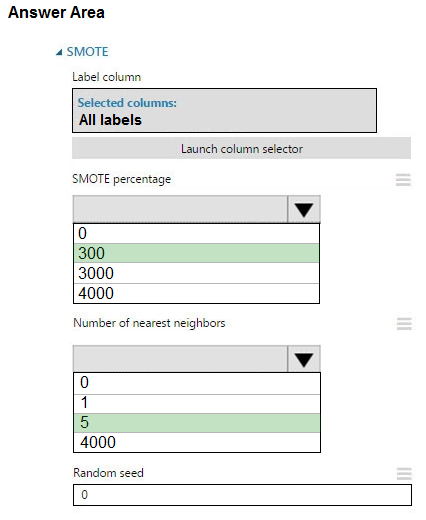
HOTSPOT - You create an experiment in Azure Machine Learning Studio. You add a training dataset that contains 10,000 rows. The first 9,000 rows represent class 0 (90 percent). The remaining 1,000 rows represent class 1 (10 percent). The training set is imbalances between two classes. You must increase the number of training examples for class 1 to 4,000 by using 5 data rows. You add the Synthetic Minority Oversampling Technique (SMOTE) module to the experiment. You need to configure the module. Which values should you use? To answer, select the appropriate options in the dialog box in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
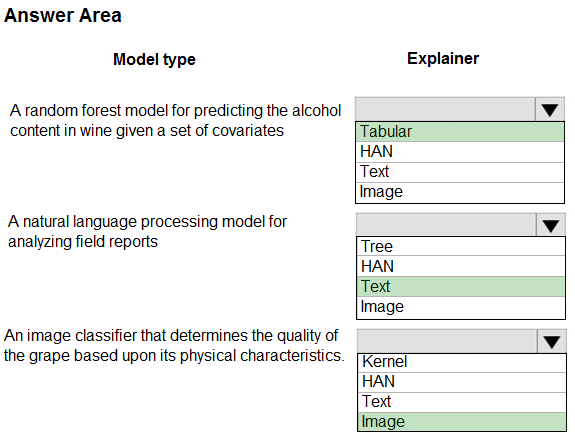
HOTSPOT - You are hired as a data scientist at a winery. The previous data scientist used Azure Machine Learning. You need to review the models and explain how each model makes decisions. Which explainer modules should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

HOTSPOT - You are using the Azure Machine Learning Service to automate hyperparameter exploration of your neural network classification model. You must define the hyperparameter space to automatically tune hyperparameters using random sampling according to following requirements: ✑ The learning rate must be selected from a normal distribution with a mean value of 10 and a standard deviation of 3. ✑ Batch size must be 16, 32 and 64. ✑ Keep probability must be a value selected from a uniform distribution between the range of 0.05 and 0.1. You need to use the param_sampling method of the Python API for the Azure Machine Learning Service. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a model to predict the price of a student's artwork depending on the following variables: the student's length of education, degree type, and art form. You start by creating a linear regression model. You need to evaluate the linear regression model. Solution: Use the following metrics: Accuracy, Precision, Recall, F1 score, and AUC. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. The default datastore of workspace1 contains a folder named sample_data. The folder structure contains the following content: |— sample_data |— MLTable |— file1.txt |— file2.txt |— file3.txt You write Python SDK v2 code to materialize the data from the files in the sample_data folder into a Pandas data frame. You need to complete the Python SDK v2 code to use the MLTable folder as the materialization blueprint. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace. You must configure a grid sampling method over the search space for the num_hidden_layers and batch_size hyperparameters. You need to identify the hyperparameters for the grid sampling. Which hyperparameter sampling approach should you use?
A. uniform
B. qlognormal
C. choice
D. normal
You use the Azure Machine Learning SDK in a notebook to run an experiment using a script file in an experiment folder. The experiment fails. You need to troubleshoot the failed experiment. What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
A. Use the get_metrics() method of the run object to retrieve the experiment run logs.
B. Use the get_details_with_logs() method of the run object to display the experiment run logs.
C. View the log files for the experiment run in the experiment folder.
D. View the logs for the experiment run in Azure Machine Learning studio.
E. Use the get_output() method of the run object to retrieve the experiment run logs.
HOTSPOT - You use Azure Machine Learning and SmartNoise Python libraries to implement a differential privacy solution to protect a dataset containing citizen demographics for the city of Seattle in the United States. The solution has the following requirements: • Allow for multiple queries targeting the mean and variance of the citizen’s age. • Ensure full plausible deniability. You need to define the query rate limit to minimize the risk of re-identification. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You register a model that you plan to use in a batch inference pipeline. The batch inference pipeline must use a ParallelRunStep step to process files in a file dataset. The script has the ParallelRunStep step runs must process six input files each time the inferencing function is called. You need to configure the pipeline. Which configuration setting should you specify in the ParallelRunConfig object for the PrallelRunStep step?
A. process_count_per_node= “6”
B. node_count= “6”
C. mini_batch_size= “6”
D. error_threshold= “6”
Access Full DP-100 Mock Test Free
Want a full-length mock test experience? Click here to unlock the complete DP-100 Mock Test Free set and get access to hundreds of additional practice questions covering all key topics.
We regularly update our question sets to stay aligned with the latest exam objectives—so check back often for fresh content!
Start practicing with our DP-100 mock test free today—and take a major step toward exam success!