

DP-100 Dump Free – 50 Practice Questions to Sharpen Your Exam Readiness.
Looking for a reliable way to prepare for your DP-100 certification? Our DP-100 Dump Free includes 50 exam-style practice questions designed to reflect real test scenarios—helping you study smarter and pass with confidence.
Using an DP-100 dump free set of questions can give you an edge in your exam prep by helping you:
- Understand the format and types of questions you’ll face
- Pinpoint weak areas and focus your study efforts
- Boost your confidence with realistic question practice
Below, you will find 50 free questions from our DP-100 Dump Free collection. These cover key topics and are structured to simulate the difficulty level of the real exam, making them a valuable tool for review or final prep.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a model to predict the price of a student's artwork depending on the following variables: the student's length of education, degree type, and art form. You start by creating a linear regression model. You need to evaluate the linear regression model. Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Accuracy, Precision, Recall, F1 score, and AUC. Does the solution meet the goal?
A. Yes
B. No
You use Azure Machine Learning designer to create a training pipeline for a regression model. You need to prepare the pipeline for deployment as an endpoint that generates predictions asynchronously for a dataset of input data values. What should you do?
A. Clone the training pipeline.
B. Create a batch inference pipeline from the training pipeline.
C. Create a real-time inference pipeline from the training pipeline.
D. Replace the dataset in the training pipeline with an Enter Data Manually module.
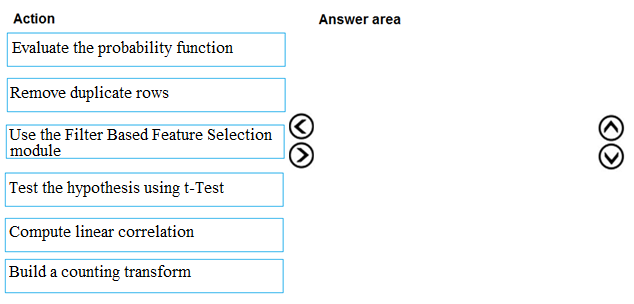
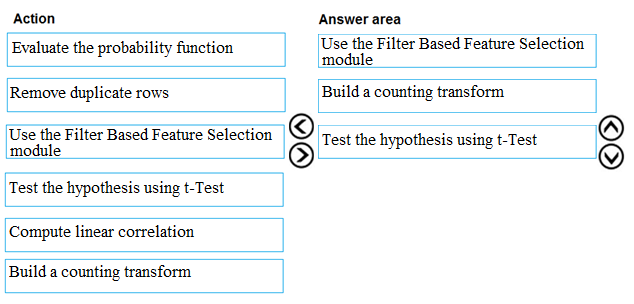
DRAG DROP - You are producing a multiple linear regression model in Azure Machine Learning Studio. Several independent variables are highly correlated. You need to select appropriate methods for conducting effective feature engineering on all the data. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files: ✑ /data/2018/Q1.csv ✑ /data/2018/Q2.csv ✑ /data/2018/Q3.csv ✑ /data/2018/Q4.csv ✑ /data/2019/Q1.csv All files store data in the following format: id,f1,f2,I 1,1,2,0 2,1,1,1 3,2,1,0 4,2,2,1 You run the following code:You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
Solution: Run the following code:
Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You are designing a machine learning solution. You have the following requirements: • Use a training script to train a machine learning model. • Build a machine learning proof of concept without the use of code or script. You need to select a development tool for each requirement. Which development tool should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You are analyzing the asymmetry in a statistical distribution. The following image contains two density curves that show the probability distribution of two datasets.Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


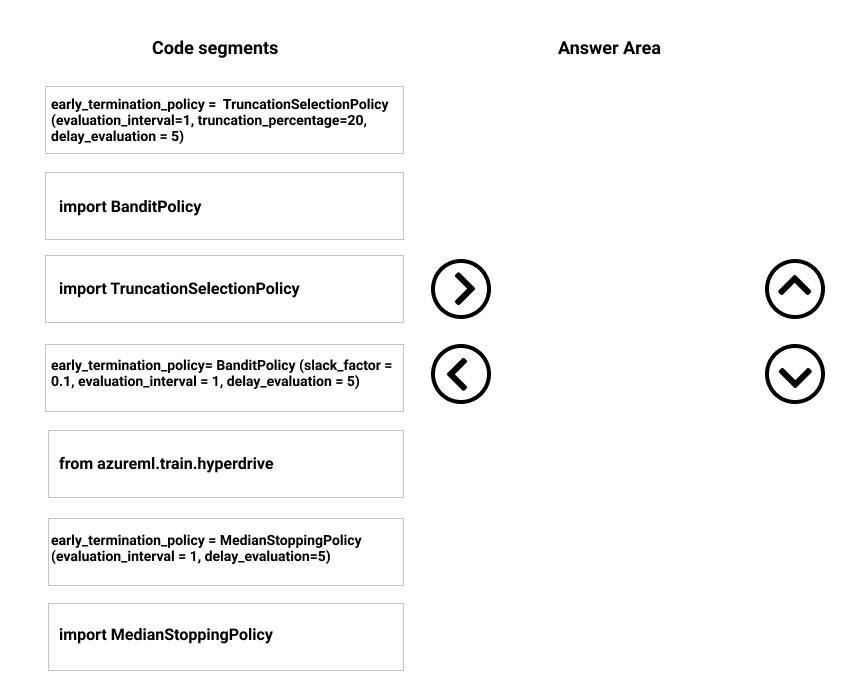
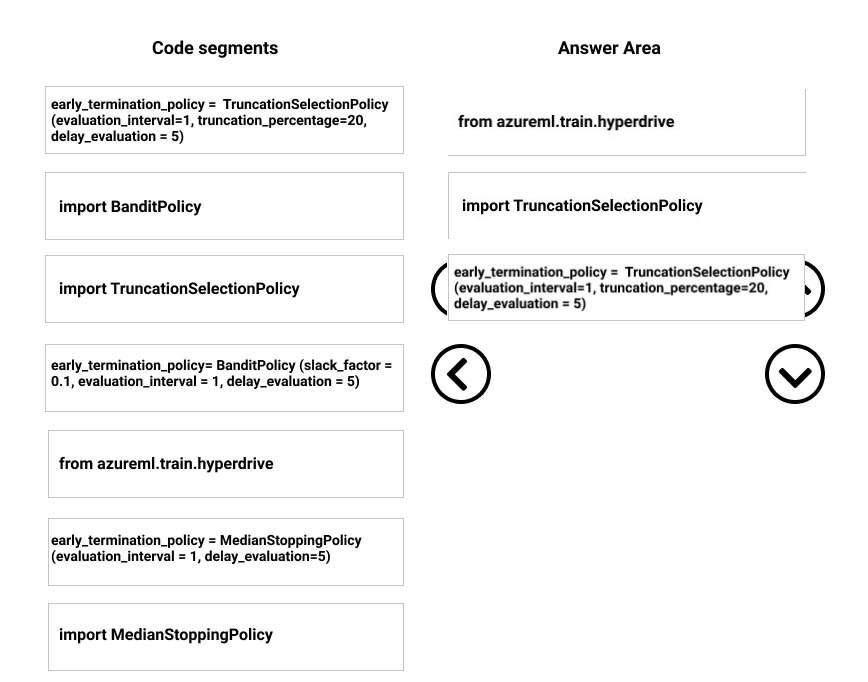
DRAG DROP - You need to implement early stopping criteria as stated in the model training requirements. Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive the credit for any of the correct orders you select. Select and Place:
DRAG DROP - You have an Azure Machine Learning workspace named WS1 and a GitHub account named account1 that hosts a private repository named repo1. You need to clone repo1 to make it available directly from WS1. The configuration must maximize the performance of the repo1 clone. Which four actions should you perform in sequence?


HOTSPOT - You build a data pipeline in an Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python. You create a data preparation step in the data pipeline. You create the following code fragment in Python:For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


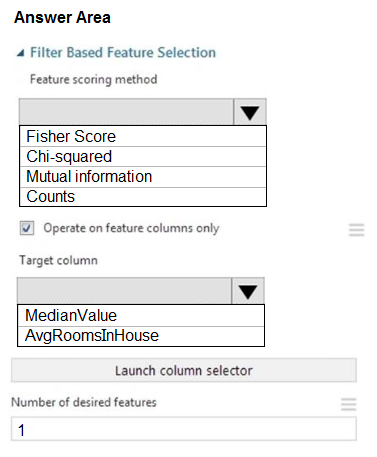
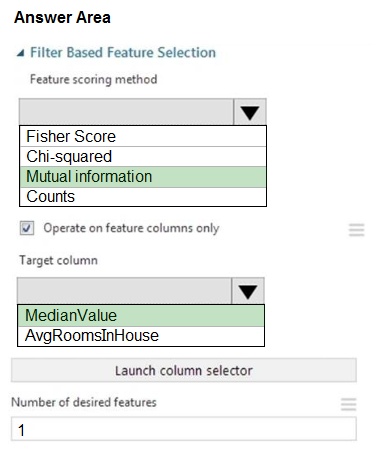
HOTSPOT - You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets. How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You create an Azure Machine Learning workspace. You use Azure Machine Learning designer to create a pipeline within the workspace. You need to submit a pipeline run from the designer. What should you do first?
A. Create an experiment.
B. Create an attached compute resource.
C. Create a compute cluster.
D. Select a model.
You use the Azure Machine Learning SDK to run a training experiment that trains a classification model and calculates its accuracy metric. The model will be retrained each month as new data is available. You must register the model for use in a batch inference pipeline. You need to register the model and ensure that the models created by subsequent retraining experiments are registered only if their accuracy is higher than the currently registered model. What are two possible ways to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Specify a different name for the model each time you register it.
B. Register the model with the same name each time regardless of accuracy, and always use the latest version of the model in the batch inferencing pipeline.
C. Specify the model framework version when registering the model, and only register subsequent models if this value is higher.
D. Specify a property named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy property value of the currently registered model.
E. Specify a tag named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy tag value of the currently registered model.
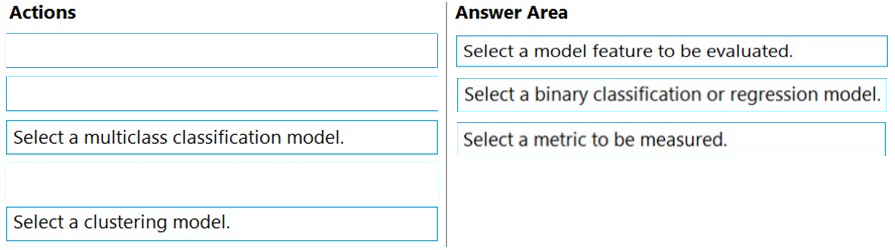
HOTSPOT - You create multiple machine learning models by using automated machine learning. You need to configure a primary metric for each use case. Which metrics should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You must use an Azure Data Science Virtual Machine (DSVM) as a compute target. You need to attach an existing DSVM to the workspace by using the Azure Machine Learning SDK for Python. How should you complete the following code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Machine Learning workspace named WS1. You plan to use the Responsible AI dashboard to assess MLflow models that you will register in WS1. You need to identify the library you should use to register the MLflow models. Which library should you use?
A. PyTorch
B. mlpy
C. TensorFlow
D. scikit-learn
HOTSPOT - You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. The default datastore of workspace1 contains a folder named sample_data. The folder structure contains the following content: |— sample_data |— MLTable |— file1.txt |— file2.txt |— file3.txt You write Python SDK v2 code to materialize the data from the files in the sample_data folder into a Pandas data frame. You need to complete the Python SDK v2 code to use the MLTable folder as the materialization blueprint. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT - You create an Azure Machine Learning workspace. You are developing a Python SDK v2 noteboot to perform custom model training in the workspace. The notebook code imports all required packages. You need to complete the Python SDK v2 code to include a training script, environment, and compute information. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You plan to build a team data science environment. Data for training models in machine learning pipelines will be over 20 GB in size. You have the following requirements: ✑ Models must be built using Caffe2 or Chainer frameworks. ✑ Data scientists must be able to use a data science environment to build the machine learning pipelines and train models on their personal devices in both connected and disconnected network environments. Personal devices must support updating machine learning pipelines when connected to a network. You need to select a data science environment. Which environment should you use?
A. Azure Machine Learning Service
B. Azure Machine Learning Studio
C. Azure Databricks
D. Azure Kubernetes Service (AKS)
HOTSPOT - You create an Azure Machine Learning dataset. You use the Azure Machine Learning designer to transform the dataset by using an Execute Python Script component and custom code. You must upload the script and associated libraries as a script bundle. You need to configure the Execute Python Script component. Which configurations should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You create an Azure Machine learning workspace. You must use the Azure Machine Learning Python SDK v2 to define the search space for discrete hyperparameters. The hyperparameters must consist of a list of predetermined, comma-separated integer values. You need to import the class from the azure.ai.ml.sweep package used to create the list of values. Which class should you import?
A. Choice
B. Randint
C. Uniform
D. Normal
You use Azure Machine Learning studio to analyze a dataset containing a decimal column named column1. You need to verify that the column1 values are normally distributed. Which statistic should you use?
A. Max
B. Type
C. Profile
D. Mean
HOTSPOT - You have a binary classifier that predicts positive cases of diabetes within two separate age groups. The classifier exhibits a high degree of disparity between the age groups. You need to modify the output of the classifier to maximize its degree of fairness across the age groups and meet the following requirements: • Eliminate the need to retrain the model on which the classifier is based. • Minimize the disparity between true positive rates and false positive rates across age groups. Which algorithm and parity constraint should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


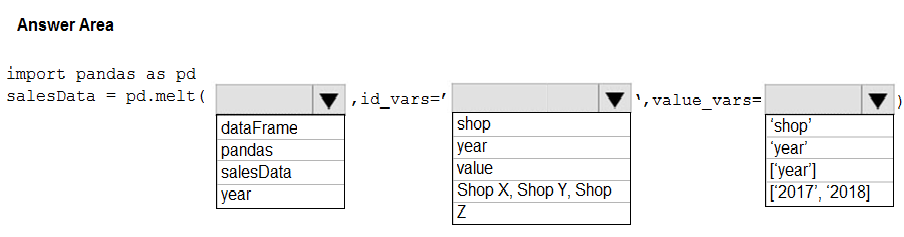
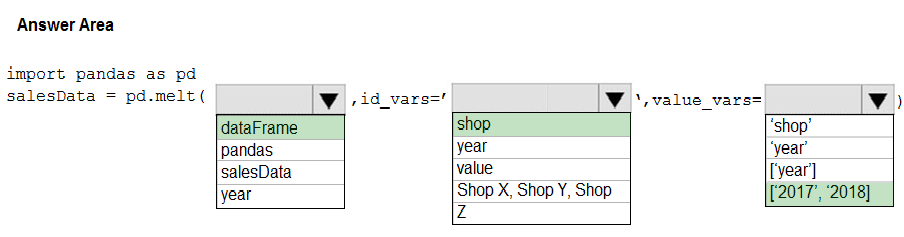
HOTSPOT - You have a Python data frame named salesData in the following format:The data frame must be unpivoted to a long data format as follows:
You need to use the pandas.melt() function in Python to perform the transformation. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register a machine learning model. You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model. You need to deploy the web service. Solution: Create an AciWebservice instance. Set the value of the ssl_enabled property to True. Deploy the model to the service. Does the solution meet the goal?
A. Yes
B. No
You plan to use automated machine learning to train a regression model. You have data that has features which have missing values, and categorical features with few distinct values. You need to configure automated machine learning to automatically impute missing values and encode categorical features as part of the training task. Which parameter and value pair should you use in the AutoMLConfig class?
A. featurization = ‘auto’
B. enable_voting_ensemble = True
C. task = ‘classification’
D. exclude_nan_labels = True
E. enable_tf = True
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have the following Azure subscriptions and Azure Machine Learning service workspaces:You need to obtain a reference to the ml-project workspace. Solution: Run the following Python code:
Does the solution meet the goal?
A. Yes
B. No
You have an Azure Machine Learning workspace named WS1. You plan to use Azure Machine Learning SDK v2 to register a model as an asset in WS1 from an artifact generated by an MLflow run. The artifact resides in a named output of a job used for the model training. You need to identify the syntax of the path to reference the model when you register it. Which syntax should you use?
A. t//model/
B. azureml://registries
C. mlflow-model/
D. azureml://jobs/
You use differential privacy to ensure your reports are private. The calculated value of the epsilon for your data is 1.8. You need to modify your data to ensure your reports are private. Which epsilon value should you accept for your data?
A. between 0 and 1
B. between 2 and 3
C. between 3 and 10
D. more than 10
You are a data scientist building a deep convolutional neural network (CNN) for image classification. The CNN model you build shows signs of overfitting. You need to reduce overfitting and converge the model to an optimal fit. Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add an additional dense layer with 512 input units.
B. Add L1/L2 regularization.
C. Use training data augmentation.
D. Reduce the amount of training data.
E. Add an additional dense layer with 64 input units.
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data visualizations using Python. Each student will use a device that has internet access. Student devices are not configured for Python development. Students do not have administrator access to install software on their devices. Azure subscriptions are not available for students. You need to ensure that students can run Python-based data visualization code. Which Azure tool should you use?
A. Anaconda Data Science Platform
B. Azure BatchAI
C. Azure Notebooks
D. Azure Machine Learning Service
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have the following Azure subscriptions and Azure Machine Learning service workspaces:You need to obtain a reference to the ml-project workspace. Solution: Run the following Python code:
Does the solution meet the goal?
A. Yes
B. No
You plan to create a compute instance as part of an Azure Machine Learning development workspace. You must interactively debug code running on the compute instance by using Visual Studio Code Remote. You need to provision the compute instance. What should you do?
A. Enable Remote Desktop Protocol (RDP) access.
B. Modify role-based access control (RBAC) settings at the workspace level.
C. Enable Secure Shell Protocol (SSH) access.
D. Modify role-based access control (RBAC) settings at the compute instance level.
You are creating a new Azure Machine Learning pipeline using the designer. The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a website. You have not created a dataset for this file. You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort. Which module should you add to the pipeline in Designer?
A. Convert to CSV
B. Enter Data Manually
C. Import Data
D. Dataset
HOTSPOT - You manage an Azure Machine Learning workspace named workspace1 with a compute instance named compute1. You must remove a kernel named kernel1 from compute1. You connect to compute1 by using a terminal window from workspace1. You need to enter a command in the terminal window to remove kernel. Which command should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are authoring a notebook in Azure Machine Learning studio. You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only. You need to install the packages. Which magic function should you use?
A. !pip
B. %pip
C. !conda
D. %load
You use the Azure Machine Learning Python SDK to define a pipeline that consists of multiple steps. When you run the pipeline, you observe that some steps do not run. The cached output from a previous run is used instead. You need to ensure that every step in the pipeline is run, even if the parameters and contents of the source directory have not changed since the previous run. What are two possible ways to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Use a PipelineData object that references a datastore other than the default datastore.
B. Set the regenerate_outputs property of the pipeline to True.
C. Set the allow_reuse property of each step in the pipeline to False.
D. Restart the compute cluster where the pipeline experiment is configured to run.
E. Set the outputs property of each step in the pipeline to True.
You have the following code. The code prepares an experiment to run a script:The experiment must be run on local computer using the default environment. You need to add code to start the experiment and run the script. Which code segment should you use?
A. run = script_experiment.start_logging()
B. run = Run(experiment=script_experiment)
C. ws.get_run(run_id=experiment.id)
D. run = script_experiment.submit(config=script_config)
HOTSPOT - You plan to use a curated environment to run Azure Machine Learning training experiments in a workspace. You need to display all curated environments and their respective packages in the workspace. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train a classification model by using a logistic regression algorithm. You must be able to explain the model's predictions by calculating the importance of each feature, both as an overall global relative importance value and as a measure of local importance for a specific set of predictions. You need to create an explainer that you can use to retrieve the required global and local feature importance values. Solution: Create a MimicExplainer. Does the solution meet the goal?
A. Yes
B. No
You create a binary classification model. The model is registered in an Azure Machine Learning workspace. You use the Azure Machine Learning Fairness SDK to assess the model fairness. You develop a training script for the model on a local machine. You need to load the model fairness metrics into Azure Machine Learning studio. What should you do?
A. Implement the download_dashboard_by_upload_id function
B. Implement the create_group_metric_set function
C. Implement the upload_dashboard_dictionary function
D. Upload the training script
You create a workspace by using Azure Machine Learning Studio. You must run a Python SDK v2 notebook in the workspace by using Azure Machine Learning Studio. You need to reset the state of the notebook. Which three actions should you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Stop the current kernel.
B. Change the compute.
C. Reset the compute.
D. Navigate to another section of the workspace.
E. Change the current kernel.
HOTSPOT - You are developing code to analyze a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0. You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted. You need to complete the code. Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are analyzing a dataset by using Azure Machine Learning Studio. You need to generate a statistical summary that contains the p-value and the unique count for each feature column. Which two modules can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Computer Linear Correlation
B. Export Count Table
C. Execute Python Script
D. Convert to Indicator Values
E. Summarize Data
DRAG DROP - An organization uses Azure Machine Learning service and wants to expand their use of machine learning. You have the following compute environments. The organization does not want to create another compute environment.You need to determine which compute environment to use for the following scenarios. Which compute types should you use? To answer, drag the appropriate compute environments to the correct scenarios. Each compute environment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


HOTSPOT - You have a feature set containing the following numerical features: X, Y, and Z. The Poisson correlation coefficient (r-value) of X, Y, and Z features is shown in the following image:Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


DRAG DROP - You have several machine learning models registered in an Azure Machine Learning workspace. You must use the Fairlearn dashboard to assess fairness in a selected model. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
You plan to run a script as an experiment. The script uses modules from the SciPy library and several Python packages that are not typically installed in a default conda environment. You plan to run the experiment on your local workstation for small datasets and scale out the experiment by running it on more powerful remote compute dusters for larger datasets. You need to ensure that the experiment runs successfully on local and remote compute with the least administrative effort. What should you do?
A. Leave the environment unspecified for the experiment. Run the expenment by using the default environment.
B. Create a config.yaml file that defines the required conda packages and save the file in the experiment folder.
C. Create and register an environment that includes the required packages. Use this environment for all experiment jobs.
D. Create a virtual machine (VM) by using the required Python configuration and attach the VM as a compute target. Use this compute target for all experiment runs.
You retrain an existing model. You need to register the new version of a model while keeping the current version of the model in the registry. What should you do?
A. Register a model with a different name from the existing model and a custom property named version with the value 2.
B. Register the model with the same name as the existing model.
C. Save the new model in the default datastore with the same name as the existing model. Do not register the new model.
D. Delete the existing model and register the new one with the same name.
HOTSPOT - You create an Azure Machine Learning workspace. You use the Azure Machine Learning Python SDK v2 to create a compute cluster. The compute cluster must run a training script. Costs associated with running the training script must be minimized. You need to complete the Python script to create the compute cluster. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Access Full DP-100 Dump Free
Looking for even more practice questions? Click here to access the complete DP-100 Dump Free collection, offering hundreds of questions across all exam objectives.
We regularly update our content to ensure accuracy and relevance—so be sure to check back for new material.
Begin your certification journey today with our DP-100 dump free questions — and get one step closer to exam success!