

DP-100 Exam Prep Free – 50 Practice Questions to Get You Ready for Exam Day
Getting ready for the DP-100 certification? Our DP-100 Exam Prep Free resource includes 50 exam-style questions designed to help you practice effectively and feel confident on test day
Effective DP-100 exam prep free is the key to success. With our free practice questions, you can:
- Get familiar with exam format and question style
- Identify which topics you’ve mastered—and which need more review
- Boost your confidence and reduce exam anxiety
Below, you will find 50 realistic DP-100 Exam Prep Free questions that cover key exam topics. These questions are designed to reflect the structure and challenge level of the actual exam, making them perfect for your study routine.
DRAG DROP - You have an Azure Machine Learning workspace that contains a training cluster and an inference cluster. You plan to create a classification model by using the Azure Machine Learning designer. You need to ensure that client applications can submit data as HTTP requests and receive predictions as responses. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You use differential privacy to ensure your reports are private. The calculated value of the epsilon for your data is 1.8. You need to modify your data to ensure your reports are private. Which epsilon value should you accept for your data?
A. between 0 and 1
B. between 2 and 3
C. between 3 and 10
D. more than 10
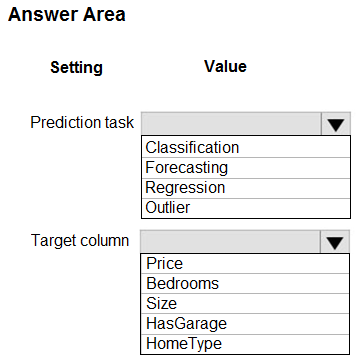
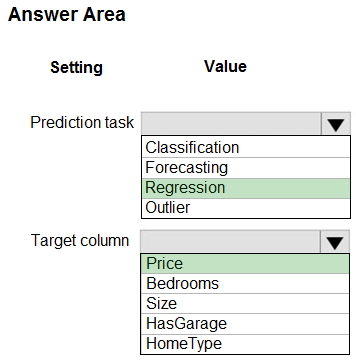
HOTSPOT - You have a dataset that includes home sales data for a city. The dataset includes the following columns.Each row in the dataset corresponds to an individual home sales transaction. You need to use automated machine learning to generate the best model for predicting the sales price based on the features of the house. Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You use the Azure Machine Learning designer to create and run a training pipeline. The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset. You need to publish the pipeline as a REST service that can be used for the nightly inferencing run. What should you do?
A. Create a batch inference pipeline
B. Set the compute target for the pipeline to an inference cluster
C. Create a real-time inference pipeline
D. Clone the pipeline
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register a machine learning model. You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model. You need to deploy the web service. Solution: Create an AciWebservice instance. Set the value of the ssl_enabled property to True. Deploy the model to the service. Does the solution meet the goal?
A. Yes
B. No
DRAG DROP - You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. You must register datastores in workspace1 for Azure Blob storage and Azure Files storage to meet the following requirements: • Azure Active Directory (Azure AD) authentication must be used for access to storage when possible. • Credentials and secrets stored in workspace1 must be valid for a specified time period when accessing Azure Files storage. You need to configure a security access method used to register the Azure Blob and Azure Files storage in workspace1. Which security access method should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


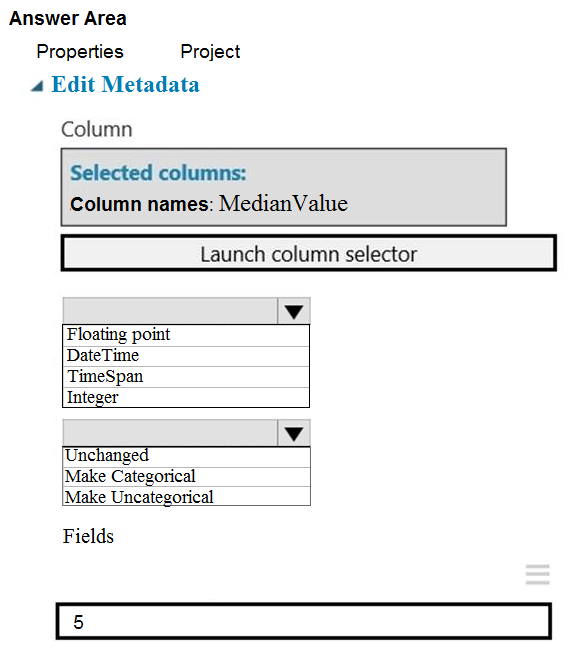
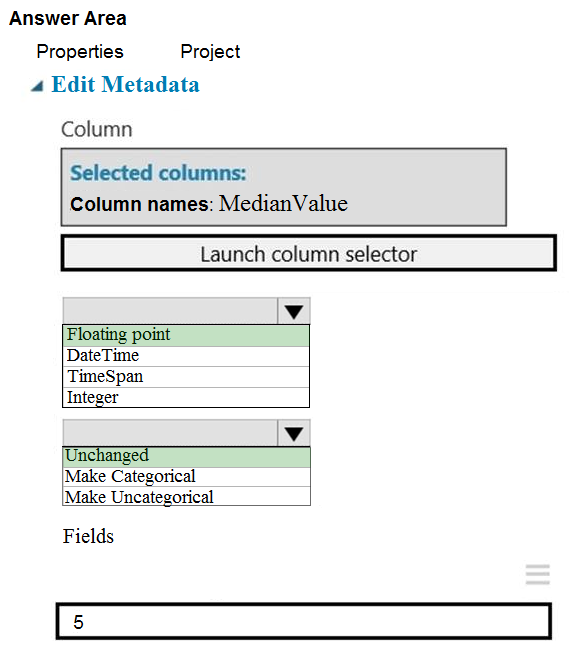
HOTSPOT - You need to configure the Edit Metadata module so that the structure of the datasets match. Which configuration options should you select? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:The experiment must record the unique labels in the data as metrics for the run that can be reviewed later. You must add code to the script to record the unique label values as run metrics at the point indicated by the comment. Solution: Replace the comment with the following code: for label_val in label_vals: run.log('Label Values', label_val) Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a model to predict the price of a student's artwork depending on the following variables: the student's length of education, degree type, and art form. You start by creating a linear regression model. You need to evaluate the linear regression model. Solution: Use the following metrics: Relative Squared Error, Coefficient of Determination, Accuracy, Precision, Recall, F1 score, and AUC. Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are a data scientist using Azure Machine Learning Studio. You need to normalize values to produce an output column into bins to predict a target column. Solution: Apply an Equal Width with Custom Start and Stop binning mode. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - Complete the sentence by selecting the correct option in the answer area. Hot Area:


You use the Azure Machine Learning Python SDK to define a pipeline to train a model. The data used to train the model is read from a folder in a datastore. You need to ensure the pipeline runs automatically whenever the data in the folder changes. What should you do?
A. Set the regenerate_outputs property of the pipeline to True
B. Create a ScheduleRecurrance object with a Frequency of auto. Use the object to create a Schedule for the pipeline
C. Create a PipelineParameter with a default value that references the location where the training data is stored
D. Create a Schedule for the pipeline. Specify the datastore in the datastore property, and the folder containing the training data in the path_on_datastore property
You must store data in Azure Blob Storage to support Azure Machine Learning. You need to transfer the data into Azure Blob Storage. What are three possible ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Bulk Insert SQL Query
B. AzCopy
C. Python script
D. Azure Storage Explorer
E. Bulk Copy Program (BCP)
HOTSPOT - You manage an Azure Machine Learning workspace. You create a training script named sample_training_script.py. The script is used to train a predictive model in the conda environment defined by a file named environment.yml. You need to run the script as an experiment. How should you complete the following code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are creating a new experiment in Azure Machine Learning Studio. One class has a much smaller number of observations than the other classes in the training set. You need to select an appropriate data sampling strategy to compensate for the class imbalance. Solution: You use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode. Does the solution meet the goal?
A. Yes
B. No
You create an Azure Machine Learning workspace. You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log a list of numeral metrics. You need to implement a method to log a list of numeral metrics. Which method should you use?
A. mlflow.log_metric()
B. mlflow.log.batch()
C. mlflow.log_image()
D. mlflow.log_artifact()
DRAG DROP - You create an Azure Machine Learning workspace. You must implement dedicated compute for model training in the workspace by using Azure Synapse compute resources. The solution must attach the dedicated compute and start an Azure Synapse session. You need to implement the computer resources. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You use Azure Machine Learning studio to analyze a dataset containing a decimal column named column1. You need to verify that the column1 values are normally distributed. Which statistic should you use?
A. Max
B. Type
C. Profile
D. Mean
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create an Azure Machine Learning pipeline named pipeline1 with two steps that contain Python scripts. Data processed by the first step is passed to the second step. You must update the content of the downstream data source of pipeline1 and run the pipeline again. You need to ensure the new run of pipeline1 fully processes the updated content. Solution: Set the allow_reuse parameter of the PythonScriptStep object of both steps to False. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You load data from a notebook in an Azure Machine Learning workspace into a pandas dataframe named df. The data contains 10,000 patient records. Each record includes the Age property for the corresponding patient. You must identify the mean age value from the differentially private data generated by SmartNoise SDK. You need to complete the Python code that will generate the mean age value from the differentially private data. Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You manage an Azure Machine Learning workspace named workspace1. You must develop Python SDK v2 code to add a compute instance to workspace1. The code must import all required modules and call the constructor of the ComputeInstance class. You need to add the instantiated compute instance to workspace1. What should you use?
A. constructor of the azure.ai.ml.ComputeSchedule class
B. constructor of the azure.ai.ml.ComputePowerAction enum
C. begin_create_or_update method of an instance of the azure.ai.ml.MLCIient class
D. set_resources method of an instance of the azure.ai.ml.Command class
DRAG DROP - You are analyzing a raw dataset that requires cleaning. You must perform transformations and manipulations by using Azure Machine Learning Studio. You need to identify the correct modules to perform the transformations. Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


You have an Azure Machine Learning workspace named WS1. You plan to use Azure Machine Learning SDK v2 to register a model as an asset in WS1 from an artifact generated by an MLflow run. The artifact resides in a named output of a job used for the model training. You need to identify the syntax of the path to reference the model when you register it. Which syntax should you use?
A. t//model/
B. azureml://registries
C. mlflow-model/
D. azureml://jobs/
DRAG DROP - You create machine learning models by using Azure Machine Learning. You plan to train and score models by using a variety of compute contexts. You also plan to create a new compute resource in Azure Machine Learning studio. You need to select the appropriate compute types. Which compute types should you select? To answer, drag the appropriate compute types to the correct requirements. Each compute type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have an Azure Machine Learning workspace. You connect to a terminal session from the Notebooks page in Azure Machine Learning studio. You plan to add a new Jupyter kernel that will be accessible from the same terminal session. You need to perform the task that must be completed before you can add the new kernel. Solution: Delete the Python 3.8 – AzureML kernel. Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You must use an Azure Data Science Virtual Machine (DSVM) as a compute target. You need to attach an existing DSVM to the workspace by using the Azure Machine Learning SDK for Python. How should you complete the following code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You register a model that you plan to use in a batch inference pipeline. The batch inference pipeline must use a ParallelRunStep step to process files in a file dataset. The script has the ParallelRunStep step runs must process six input files each time the inferencing function is called. You need to configure the pipeline. Which configuration setting should you specify in the ParallelRunConfig object for the PrallelRunStep step?
A. process_count_per_node= “6”
B. node_count= “6”
C. mini_batch_size= “6”
D. error_threshold= “6”
HOTSPOT - You have a multi-class image classification deep learning model that uses a set of labeled photographs. You create the following code to select hyperparameter values when training the model.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You download a .csv file from a notebook in an Azure Machine Learning workspace to a data/sample.csv folder on a compute instance. The file contains 10,000 records. You must generate the summary statistics for the data in the file. The statistics must include the following for each numerical column: • number of non-empty values • average value • standard deviation • minimum and maximum values • 25th, 50th, and 75th percentiles You need to complete the Python code that will generate the summary statistics. Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


DRAG DROP - You have an Azure Machine Learning workspace. You are running an experiment on your local computer. You need to ensure that you can use MLflow Tracking with Azure Machine Learning Python SDK v2 to store metrics and artifacts from your local experiment runs m the workspace. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


You create a binary classification model. You use the Fairlearn package to assess model fairness. You must eliminate the need to retrain the model. You need to implement the Fairlearn package. Which algorithm should you use?
A. fairlearn.reductions.ExponentiatedGradient
B. fairlearn.postprocessing.ThresholdOptimizer
C. fairlearnpreprocessing.CorrelationRemover
D. fairlearn.reductions.GridSearch
You are a data scientist building a deep convolutional neural network (CNN) for image classification. The CNN model you build shows signs of overfitting. You need to reduce overfitting and converge the model to an optimal fit. Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add an additional dense layer with 512 input units.
B. Add L1/L2 regularization.
C. Use training data augmentation.
D. Reduce the amount of training data.
E. Add an additional dense layer with 64 input units.
HOTSPOT - You use Azure Machine Learning to train a machine learning model. You use the following training script in Python to perform logging: import mlflow mlflow.log_metric(“accuracy", float(vel_accuracy)) You must use a Python script to define a sweep job. You need to provide the primary metric and goal you want hyperparameter tuning to optimize. How should you complete the Python script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Machine Learning workspace. You plan to tune a model hyperparameter when you train the model. You need to define a search space that returns a normally distributed value. Which parameter should you use?
A. QUniform
B. LogUniform
C. Uniform
D. LogNormal
You are creating a binary classification by using a two-class logistic regression model. You need to evaluate the model results for imbalance. Which evaluation metric should you use?
A. Relative Absolute Error
B. AUC Curve
C. Mean Absolute Error
D. Relative Squared Error
E. Accuracy
F. Root Mean Square Error
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register an Azure Machine Learning model. You plan to deploy the model to an online endpoint. You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model. Solution: Create a managed online endpoint and set the value of its auth_mode parameter to aml_token. Deploy the model to the online endpoint. Does the solution meet the goal?
A. Yes
B. No
You need to select a feature extraction method. Which method should you use?
A. Mutual information
B. Mood’s median test
C. Kendall correlation
D. Permutation Feature Importance
HOTSPOT - You have an Azure Machine learning workspace. The workspace contains a dataset with data in a tabular form. You plan to use the Azure Machine Learning SDK for Python v1 to create a control script that will load the dataset into a pandas dataframe in preparation for model training. The script will accept a parameter designating the dataset. You need to complete the script. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


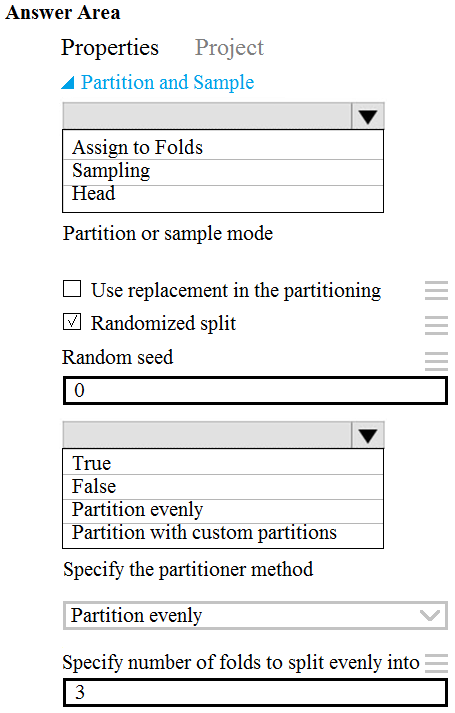
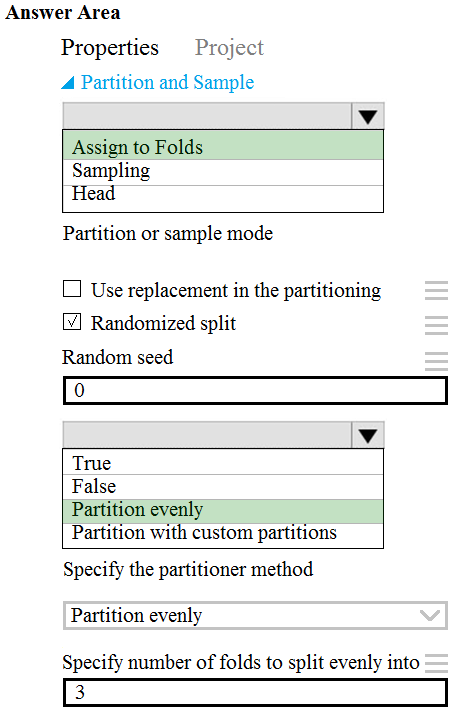
HOTSPOT - You need to identify the methods for dividing the data according to the testing requirements. Which properties should you select? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
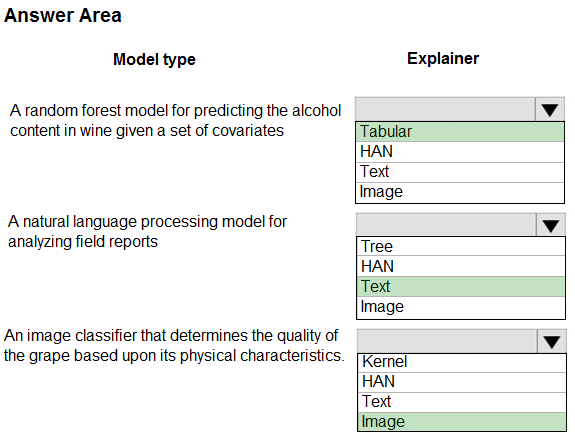
HOTSPOT - You are hired as a data scientist at a winery. The previous data scientist used Azure Machine Learning. You need to review the models and explain how each model makes decisions. Which explainer modules should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

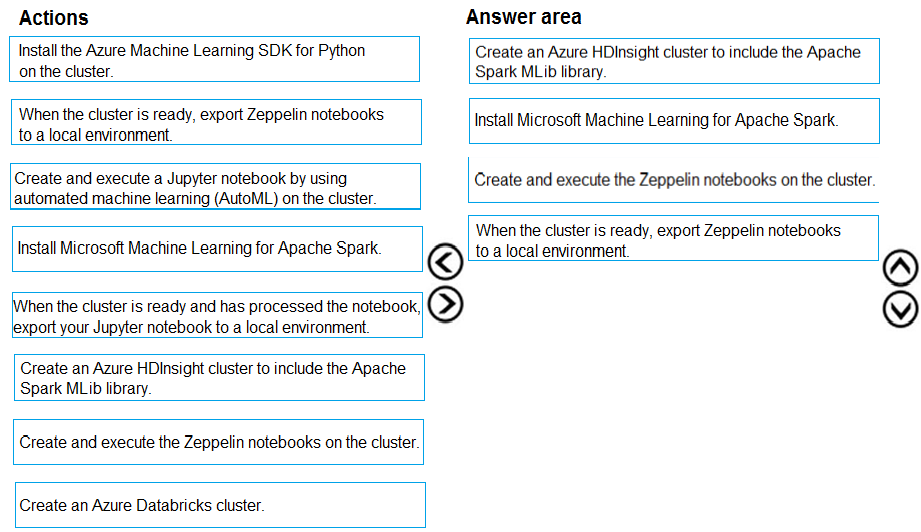
DRAG DROP - You are building an intelligent solution using machine learning models. The environment must support the following requirements: ✑ Data scientists must build notebooks in a cloud environment ✑ Data scientists must use automatic feature engineering and model building in machine learning pipelines. ✑ Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation. ✑ Notebooks must be exportable to be version controlled locally. You need to create the environment. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You create a workspace to include a compute instance by using Azure Machine Learning Studio. You are developing a Python SDK v2 notebook in the workspace. You need to use Intellisense in the notebook. What should you do?
A. Stop the compute instance.
B. Start the compute instance.
C. Run a %pip magic function on the compute instance.
D. Run a !pip magic function on the compute instance.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have the following Azure subscriptions and Azure Machine Learning service workspaces:You need to obtain a reference to the ml-project workspace. Solution: Run the following Python code:
Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You create an Azure Machine Learning model to include model files and a scoring script. You must deploy the model. The deployment solution must meet the following requirements: • Provide near real-time inferencing. • Enable endpoint and deployment level cost estimates. • Support logging to Azure Log Analytics. You need to configure the deployment solution. What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You create an Azure Machine Learning workspace. You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics. You need to implement the method to log the string metrics. Which method should you use?
A. mlflow.log_artifact()
B. mlflow.log.dict()
C. mlflow.log_metric()
D. mlflow.log_text()
You have recently concluded the construction of a binary classification machine learning model. You are currently assessing the model. You want to make use of a visualization that allows for precision to be used as the measurement for the assessment. Which of the following actions should you take?
A. You should consider using Venn diagram visualization.
B. You should consider using Receiver Operating Characteristic (ROC) curve visualization.
C. You should consider using Box plot visualization.
D. You should consider using the Binary classification confusion matrix visualization.
You have a dataset that contains salary information for users. You plan to generate an aggregate salary report that shows average salaries by city. Privacy of individuals must be preserved without impacting accuracy, completeness, or reliability of the data. The aggregation must be statistically consistent with the distribution of the original data. You must return an approximation of the data instead of the raw data. You need to apply a differential privacy approach. What should you do?
A. Add noise to the salary data during the analysis
B. Encrypt the salary data before analysis
C. Remove the salary data
D. Convert the salary data to the average column value
HOTSPOT - You create an Azure Machine learning workspace. The workspace contains a folder named src. The folder contains a Python script named script1.py. You use the Azure Machine Learning Python SDK v2 to create a control script. You must use the control script to run script1.py as part of a training job. You need to complete the section of script that defines the job parameters. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You register a file dataset named csv_folder that references a folder. The folder includes multiple comma-separated values (CSV) files in an Azure storage blob container. You plan to use the following code to run a script that loads data from the file dataset. You create and instantiate the following variables:You have the following code:
You need to pass the dataset to ensure that the script can read the files it references. Which code segment should you insert to replace the code comment?
A. inputs=[file_dataset.as_named_input(‘training_files’)],
B. inputs=[file_dataset.as_named_input(‘training_files’).as_mount()],
C. inputs=[file_dataset.as_named_input(‘training_files’).to_pandas_dataframe()],
D. script_params={‘–training_files’: file_dataset},
Access Full DP-100 Exam Prep Free
Want to go beyond these 50 questions? Click here to unlock a full set of DP-100 exam prep free questions covering every domain tested on the exam.
We continuously update our content to ensure you have the most current and effective prep materials.
Good luck with your DP-100 certification journey!