

DP-200 Practice Exam Free – 50 Questions to Simulate the Real Exam
Are you getting ready for the DP-200 certification? Take your preparation to the next level with our DP-200 Practice Exam Free – a carefully designed set of 50 realistic exam-style questions to help you evaluate your knowledge and boost your confidence.
Using a DP-200 practice exam free is one of the best ways to:
- Experience the format and difficulty of the real exam
- Identify your strengths and focus on weak areas
- Improve your test-taking speed and accuracy
Below, you will find 50 realistic DP-200 practice exam free questions covering key exam topics. Each question reflects the structure and challenge of the actual exam.
You have to deploy resources on Azure HDInsight for a batch processing job. The batch processing must run daily and must scale to minimize costs. You also be able to monitor cluster performance. You need to decide on a tool that will monitor the clusters and provide information on suggestions on how to scale. You decide on monitoring the cluster load by using the Ambari Web UI. Would this fulfill the requirement?
A. Yes
B. No

You have an Azure subscription the contains the resources shown in the following table:All the resources have the default encryption settings. You need to ensure that all the data stored in the resources is encrypted at rest. What should you do?
A. Enable Azure Storage encryption for storageaccount1.
B. Enable Transparent Data Encryption (TDE) for synapsedb1.
C. Enable Azure Storage encryption for storageaccount2.
D. Enable encryption at rest for cosmosdb1.
You have an Azure subscription that contains an Azure Data Factory version 2 (V2) data factory named df1. Df1 contains a linked service. You have an Azure Key vault named vault1 that contains an encryption key named key1. You need to encrypt df1 by using key1. What should you do first?
A. Disable purge protection on vault1.
B. Create a self-hosted integration runtime.
C. Disable soft delete on vault1.
D. Remove the linked service from df1.
You are developing a data engineering solution for a company. The solution will store a large set of key-value pair data by using Microsoft Azure Cosmos DB. The solution has the following requirements: ✑ Data must be partitioned into multiple containers. ✑ Data containers must be configured separately. ✑ Data must be accessible from applications hosted around the world. ✑ The solution must minimize latency. You need to provision Azure Cosmos DB. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Configure account-level throughput.
B. Provision an Azure Cosmos DB account with the Azure Table API. Enable geo-redundancy.
C. Configure table-level throughput.
D. Replicate the data globally by manually adding regions to the Azure Cosmos DB account.
E. Provision an Azure Cosmos DB account with the Azure Table API. Enable multi-region writes.
An application will use Microsoft Azure Cosmos DB as its data solution. The application will use the Cassandra API to support a column-based database type that uses containers to store items. You need to provision Azure Cosmos DB. Which container name and item name should you use? Each correct answer presents part of the solutions. NOTE: Each correct answer selection is worth one point.
A. collection
B. rows
C. graph
D. entities
E. table


You have an Azure SQL database that has masked columns. You need to identify when a user attempts to infer data from the masked columns. What should you use?
A. Azure Advanced Threat Protection (ATP)
B. custom masking rules
C. Transparent Data Encryption (TDE)
D. auditing
You plan to implement an Azure Cosmos DB database that will write 100,000,000 JSON records every 24 hours. The database will be replicated to three regions. Only one region will be writable. You need to select a consistency level for the database to meet the following requirements: ✑ Guarantee monotonic reads and writes within a session. ✑ Provide the fastest throughput. ✑ Provide the lowest latency. Which consistency level should you select?
A. Strong
B. Bounded Staleness
C. Eventual
D. Session
E. Consistent Prefix
You have a SQL pool in Azure Synapse. A user reports that queries against the pool take longer than expected to complete. You need to add monitoring to the underlying storage to help diagnose the issue. Which two metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Cache used percentage
B. DWU Limit
C. Snapshot Storage Size
D. Active queries
E. Cache hit percentage
DRAG DROP - Your company plans to create an event processing engine to handle streaming data from Twitter. The data engineering team uses Azure Event Hubs to ingest the streaming data. You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs. Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:


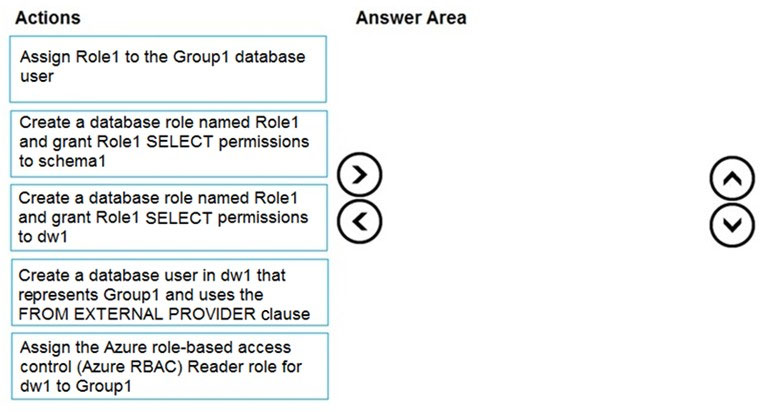
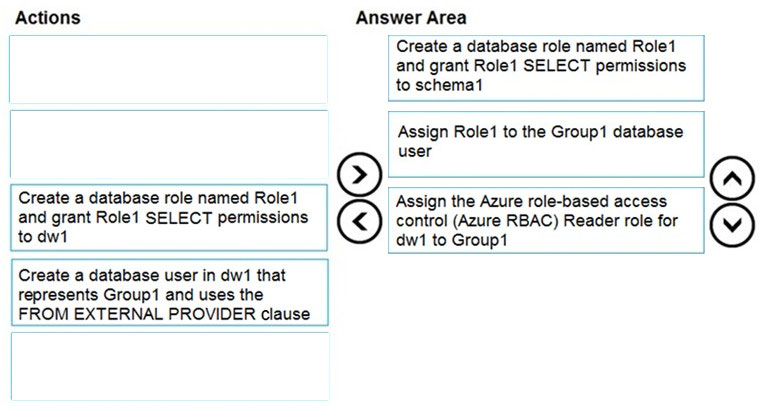
DRAG DROP - You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1. You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data. Which input type should you use for the reference data?
A. Azure Cosmos DB
B. Azure Event Hubs
C. Azure Blob storage
D. Azure IoT Hub
HOTSPOT - Which masking functions should you implement for each column to meet the data masking requirements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


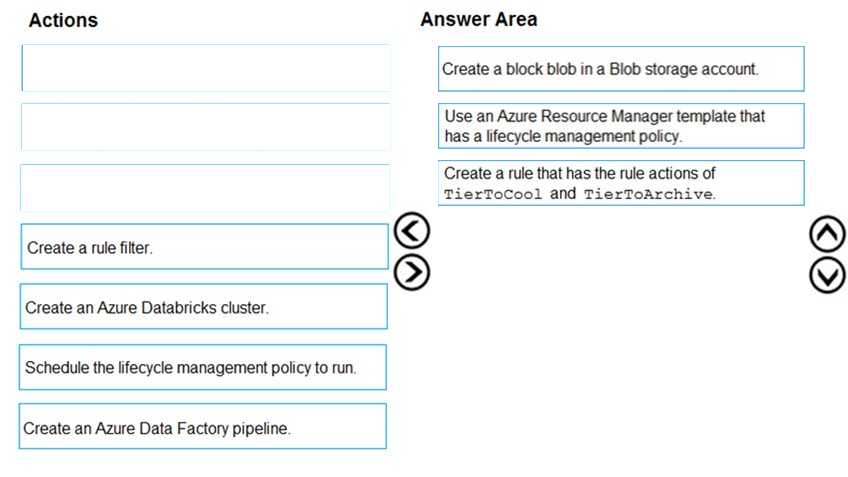
DRAG DROP - You are implementing an Azure Blob storage account for an application that has the following requirements: ✑ Data created during the last 12 months must be readily accessible. ✑ Blobs older than 24 months must use the lowest storage costs. This data will be accessed infrequently. ✑ Data created 12 to 24 months ago will be accessed infrequently but must be readily accessible at the lowest storage costs. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You have an alert on a SQL pool in Azure Synapse that uses the signal logic shown in the exhibit.On the same day, failures occur at the following times: ✑ 08:01 ✑ 08:03 ✑ 08:04 ✑ 08:06 ✑ 08:11 ✑ 08:16 ✑ 08:19 The evaluation period starts on the hour. At which times will alert notifications be sent?
A. 08:15 only
B. 08:10, 08:15, and 08:20
C. 08:05 and 08:10 only
D. 08:10 only
E. 08:05 only
HOTSPOT - You have an Azure Cosmos DB database. You need to use Azure Stream Analytics to check for uneven distributions of queries that can affect performance. Which two settings should you configure? To answer, select the appropriate settings in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
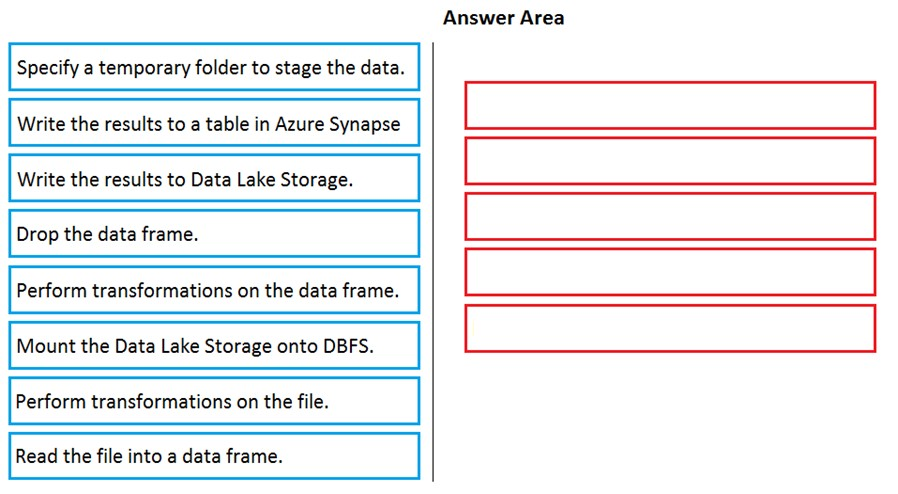
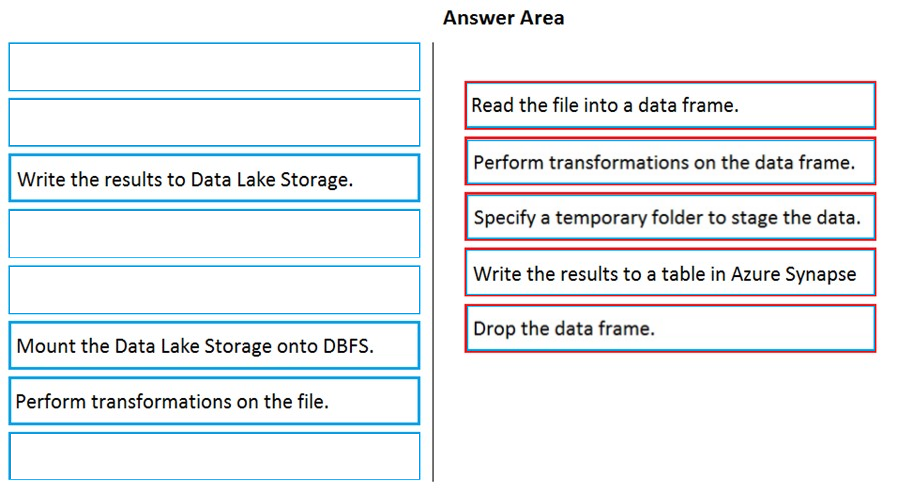
DRAG DROP - You have an Azure Data Lake Storage Gen2 account that contains JSON files for customers. The files contain two attributes named FirstName and LastName. You need to copy the data from the JSON files to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values. You create the following components: ✑ A destination table in Azure Synapse ✑ An Azure Blob storage container ✑ A service principal Which five actions should you perform in sequence next in a Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
HOTSPOT - Which masking functions should you implement for each column to meet the data masking requirements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You have an Azure Storage account named storage1 that is configured as shown in the following exhibit.You need to ensure that all calls to an Azure Storage REST API operation on storage1 are made over HTTPS. What should you do?
A. Set Secure transfer required to Enabled.
B. Set Allow Blob public access to Disabled.
C. For the Blob service, create a shared access signature (SAS) that allows HTTPS only.
D. Set Minimum TLS version to Version 1.2.
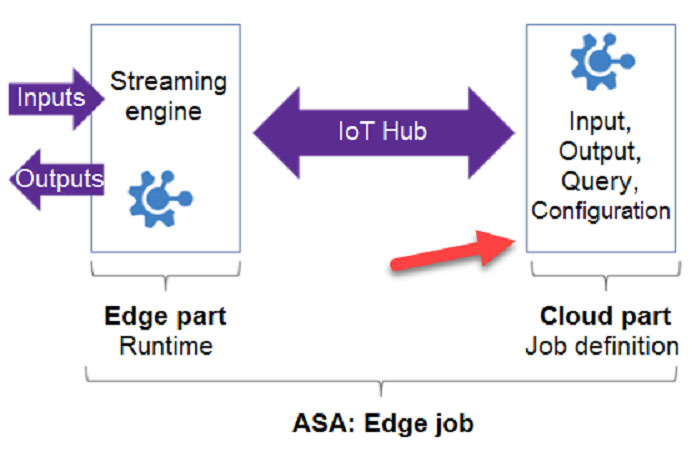
You need to deploy a Microsoft Azure Stream Analytics job for an IoT based solution. The solution must minimize latency. The solution must also minimize the bandwidth usage between the job and the IoT device. Which of the following actions must you perform for this requirement? (Choose four.)
A. Ensure to configure routes
B. Create an Azure Blob storage container
C. Configure Streaming Units
D. Create an IoT Hub and add the Azure Stream Analytics modules to the IoT Hub namespace
E. Create an Azure Stream Analytics edge job and configure job definition save location
F. Create an Azure Stream Analytics cloud job and configure job definition save location

After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Use information stored in Azure Active Directory reports. Does the solution meet the goal?
A. Yes
B. No
Which two metrics should you use to identify the appropriate RU/s for the telemetry data? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Number of requests
B. Number of requests exceeded capacity
C. End to end observed read latency at the 99 th percentile
D. Session consistency
E. Data + Index storage consumed
F. Avg Throughput/s
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure storage account 2. Create a workload group using the Azure storage account name as the pool name 3. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
DRAG DROP - You have an Azure Stream Analytics job that is a Stream Analytics project solution in Microsoft Visual Studio. The job accepts data generated by IoT devices in the JSON format. You need to modify the job to accept data generated by the IoT devices in the Protobuf format. Which three actions should you perform from Visual Studio in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

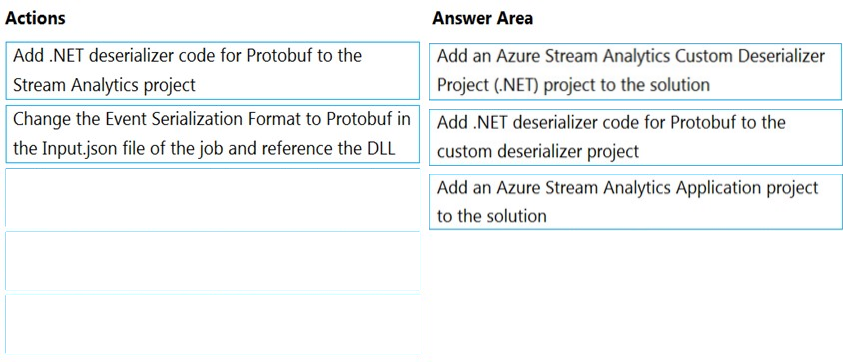
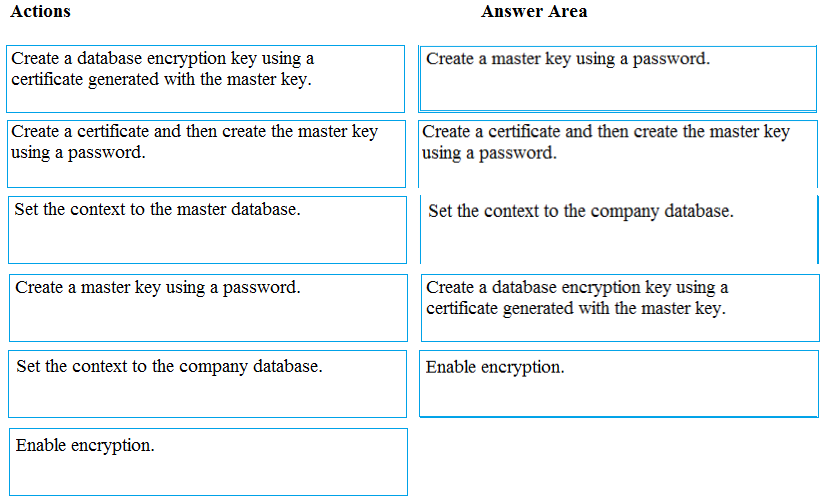
DRAG DROP - You manage security for a database that supports a line of business application. Private and personal data stored in the database must be protected and encrypted. You need to configure the database to use Transparent Data Encryption (TDE). Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Use Azure Data Factory to convert the parquet files to CSV files 2. Create an external data source pointing to the Azure Data Lake Gen 2 storage account 3. Create an external file format and external table using the external data source 4. Load the data using the CREATE TABLE AS SELECT statement Does the solution meet the goal?
A. Yes
B. No
You create an Azure Databricks cluster and specify an additional library to install. When you attempt to load the library to a notebook, the library is not found. You need to identify the cause of the issue. What should you review?
A. workspace logs
B. notebook logs
C. global init scripts logs
D. cluster event logs
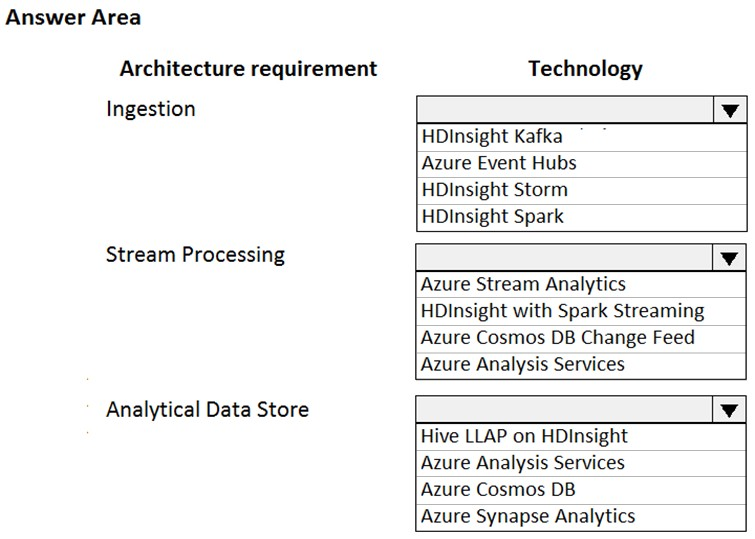
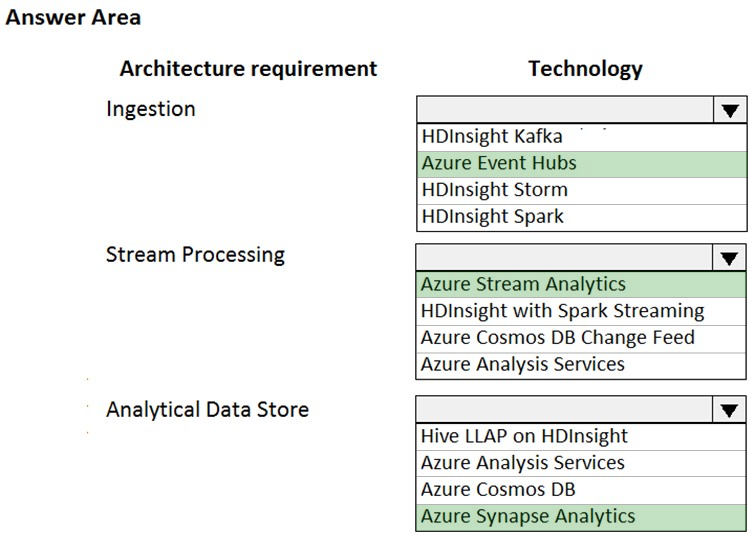
HOTSPOT - You are designing a new Lambda architecture on Microsoft Azure. The real-time processing layer must meet the following requirements: Ingestion: ✑ Receive millions of events per second ✑ Act as a fully managed Platform-as-a-Service (PaaS) solution ✑ Integrate with Azure Functions Stream processing: ✑ Process on a per-job basis ✑ Provide seamless connectivity with Azure services ✑ Use a SQL-based query language Analytical data store: ✑ Act as a managed service ✑ Use a document store ✑ Provide data encryption at rest You need to identify the correct technologies to build the Lambda architecture using minimal effort. Which technologies should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
HOTSPOT - You have an Azure data factory that has two pipelines named PipelineA and PipelineB. PipelineA has four activities as shown in the following exhibit.PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings: ✑ Operator: Greater than ✑ Aggregation type: Total ✑ Threshold value: 2 ✑ Aggregation granularity (Period): 5 minutes ✑ Frequency of evaluation: Every 5 minutes Data Factory monitoring records the failures shown in the following table.
For each of the following statements, select yes if the statement is true. Otherwise, select no. NOTE: Each correct answer selection is worth one point. Hot Area:


HOTSPOT - A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row. You need to create the input stream. How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


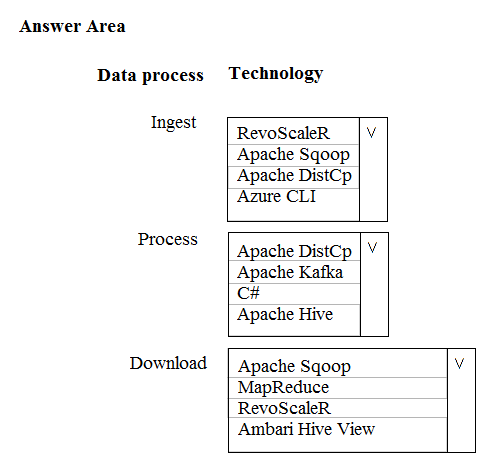
HOTSPOT - A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements: ✑ Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service ✑ Use an Azure Data Lake Storage account to store processed data ✑ Allow users to download processed data You need to recommend technologies for the solution. Which technologies should you use? To answer, select the appropriate options in the answer area. Hot Area:
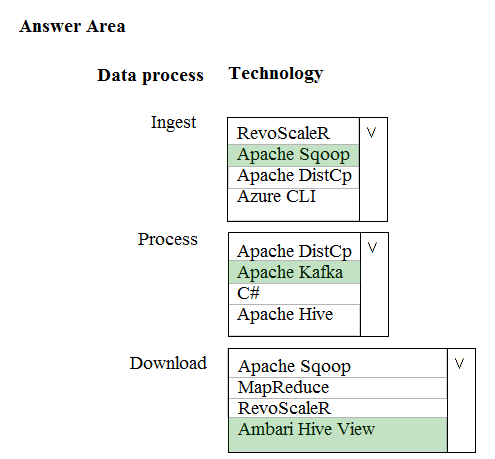
You are creating a new notebook in Azure Databricks that will support R as the primary language but will also support Scala and SQL. Which switch should you use to switch between languages?
A. %
B. []
C. ()
D. @
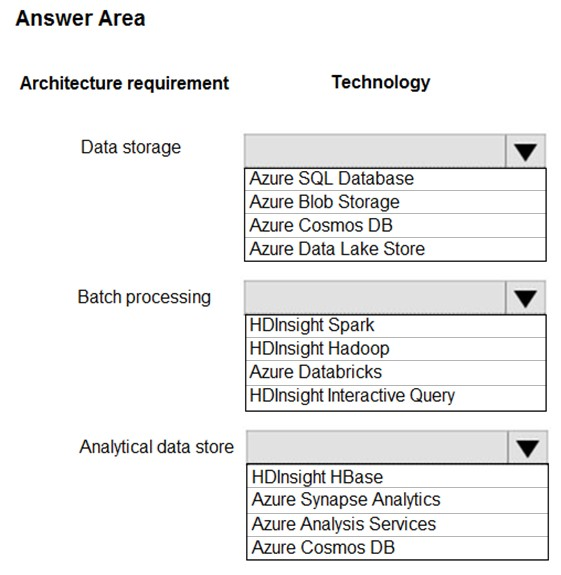
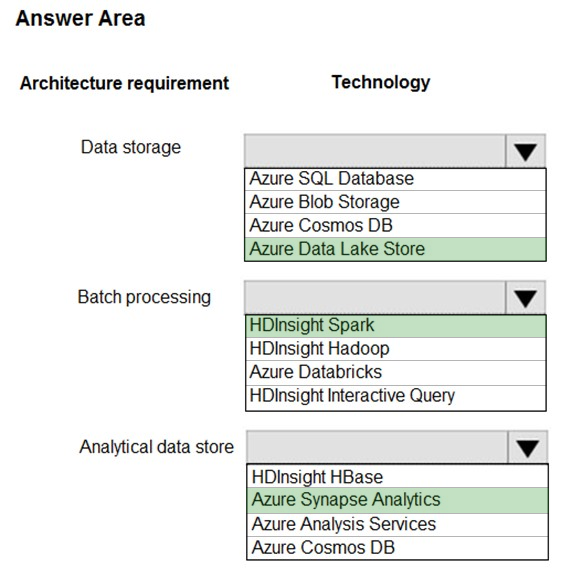
HOTSPOT - You are developing a solution using a Lambda architecture on Microsoft Azure. The data at rest layer must meet the following requirements: Data storage: ✑ Serve as a repository for high volumes of large files in various formats. ✑ Implement optimized storage for big data analytics workloads. ✑ Ensure that data can be organized using a hierarchical structure. Batch processing: ✑ Use a managed solution for in-memory computation processing. ✑ Natively support Scala, Python, and R programming languages. ✑ Provide the ability to resize and terminate the cluster automatically. Analytical data store: ✑ Support parallel processing. ✑ Use columnar storage. ✑ Support SQL-based languages. You need to identify the correct technologies to build the Lambda architecture. Which technologies should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
HOTSPOT - You have a SQL pool in Azure Synapse. You plan to load data from Azure Blob storage to a staging table. Approximately 1 million rows of data will be loaded daily. The table will be truncated before each daily load. You need to create the staging table. The solution must minimize how long it takes to load the data to the staging table. How should you configure the table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


DRAG DROP - You plan to create a new single database instance of Microsoft Azure SQL Database. The database must only allow communication from the data engineer's workstation. You must connect directly to the instance by using Microsoft SQL Server Management Studio. You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order. Select and Place:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account. Does the solution meet the goal?
A. Yes
B. No
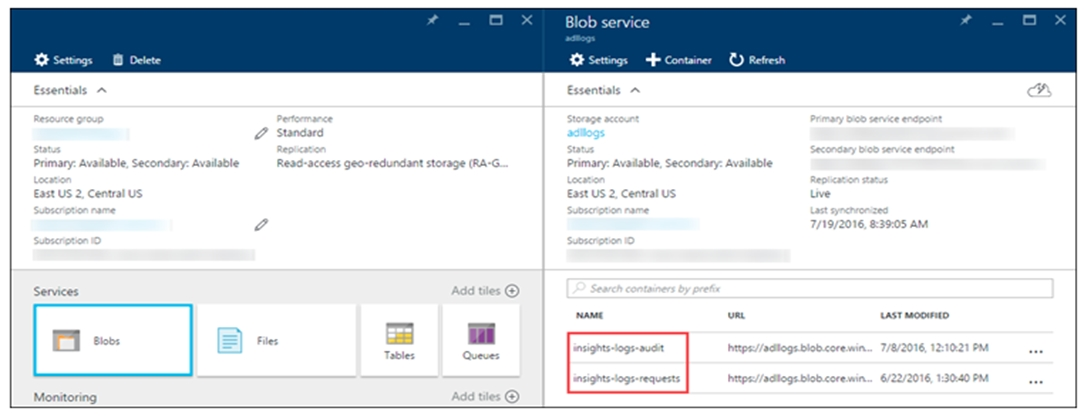
You need to implement event processing by using Stream Analytics to produce consistent JSON documents. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Define an output to Cosmos DB.
B. Define a query that contains a JavaScript user-defined aggregates (UDA) function.
C. Define a reference input.
D. Define a transformation query.
E. Define an output to Azure Data Lake Storage Gen2.
F. Define a stream input.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
A. Yes
B. No
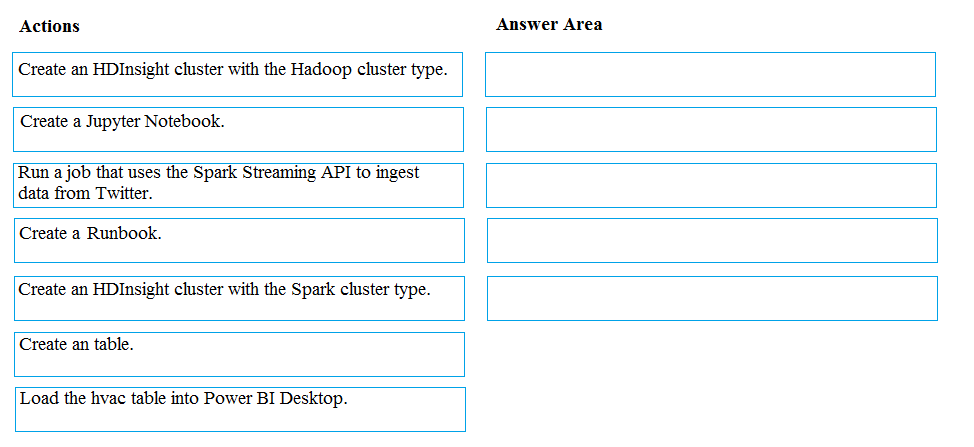
DRAG DROP - You develop data engineering solutions for a company. A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution. Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

Your company uses Azure Stream Analytics to monitor devices. The company plans to double the number of devices that are monitored. You need to monitor a Stream Analytics job to ensure that there are enough processing resources to handle the additional load. Which metric should you monitor?
A. Input Deserialization Errors
B. Early Input Events
C. Late Input Events
D. Watermark delay
You need to implement complex stateful business logic within an Azure Stream Analytics service. Which type of function should you create in the Stream Analytics topology?
A. JavaScript user-define functions (UDFs)
B. Azure Machine Learning
C. JavaScript user-defined aggregates (UDA)
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data. The analytical data store performs poorly. You must implement a solution that meets the following requirements: ✑ Provide data warehousing ✑ Reduce ongoing management activities ✑ Deliver SQL query responses in less than one second You need to create an HDInsight cluster to meet the requirements. Which type of cluster should you create?
A. Interactive Query
B. Apache Hadoop
C. Apache HBase
D. Apache Spark
You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU% Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Watermark Delay
B. Late Input Events
C. Out of order Events
D. Backlogged Input Events
E. Function Events
You have an Azure Blob storage account. The storage account has an alert that is configured to indicate when the Availability metric falls below 100 percent. You receive an alert for the Availability metric. The logs for the storage account show that requests are failing because of a ServerTimeoutError error. What does ServerTimeoutError indicate?
A. Read and write storage requests exceeded capacity.
B. A transient server timeout occurred while the service was moved to a different partition to load balance requests.
C. A client application attempted to perform an operation and did not have valid credentials.
D. There was excessive network latency between a client application and the storage account.
HOTSPOT - You need to build a solution to collect the telemetry data for Race Central. What should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


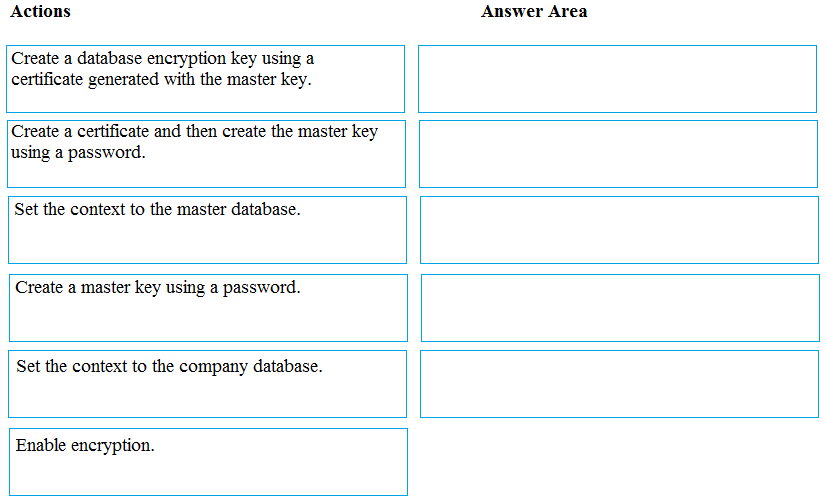
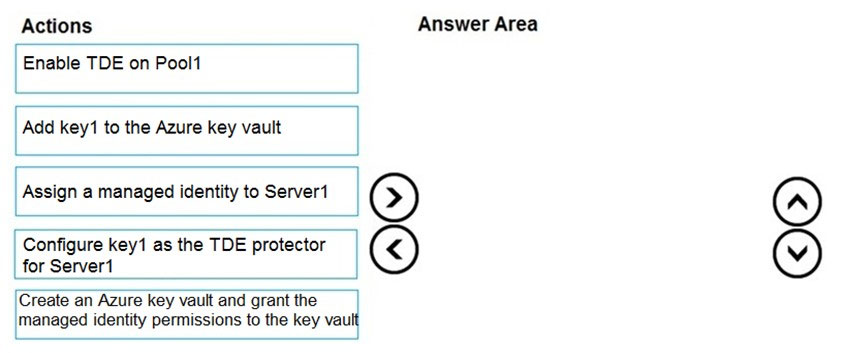
DRAG DROP - You have an Azure Synapse Analytics SQL pool named Pool1 on a logical Microsoft SQL server named Server1. You need to implement Transparent Data Encryption (TDE) on Pool1 by using a custom key named key1. Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

HOTSPOT - You are implementing automatic tuning mode for Azure SQL databases. Automatic tuning mode is configured as shown in the following table.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


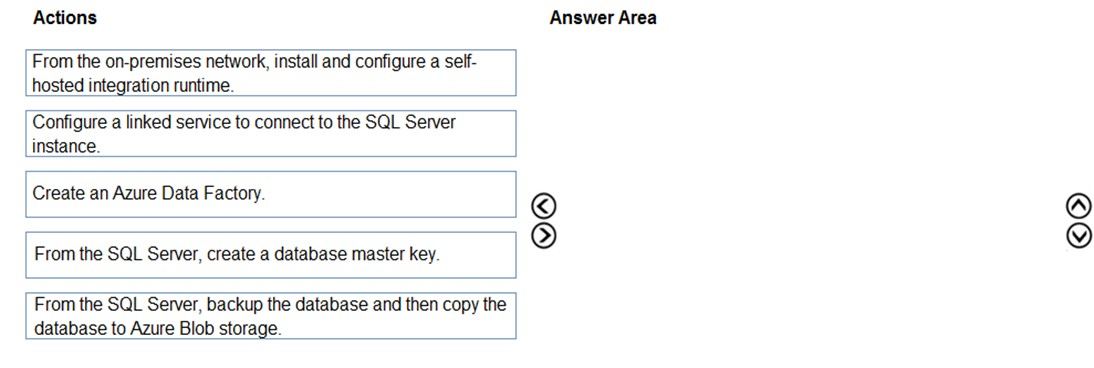
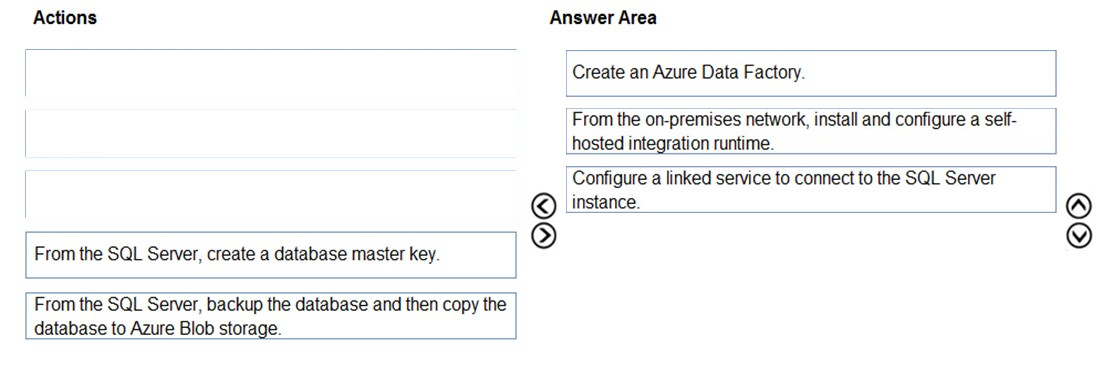
DRAG DROP - Your company has an on-premises Microsoft SQL Server instance. The data engineering team plans to implement a process that copies data from the SQL Server instance to Azure Blob storage once a day. The process must orchestrate and manage the data lifecycle. You need to create Azure Data Factory to connect to the SQL Server instance. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
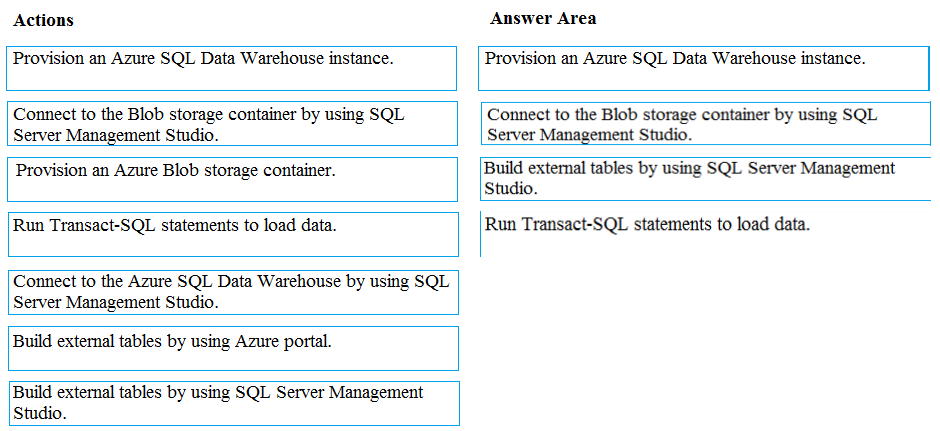
DRAG DROP - You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You need to develop a pipeline for processing data. The pipeline must meet the following requirements: ✑ Scale up and down resources for cost reduction ✑ Use an in-memory data processing engine to speed up ETL and machine learning operations. ✑ Use streaming capabilities ✑ Provide the ability to code in SQL, Python, Scala, and R Integrate workspace collaboration with GitWhat should you use?
A. HDInsight Spark Cluster
B. Azure Stream Analytics
C. HDInsight Hadoop Cluster
D. Azure SQL Data Warehouse
E. HDInsight Kafka Cluster
F. HDInsight Storm Cluster
Free Access Full DP-200 Practice Exam Free
Looking for additional practice? Click here to access a full set of DP-200 practice exam free questions and continue building your skills across all exam domains.
Our question sets are updated regularly to ensure they stay aligned with the latest exam objectives—so be sure to visit often!
Good luck with your DP-200 certification journey!