

DP-100 Practice Exam Free – 50 Questions to Simulate the Real Exam
Are you getting ready for the DP-100 certification? Take your preparation to the next level with our DP-100 Practice Exam Free – a carefully designed set of 50 realistic exam-style questions to help you evaluate your knowledge and boost your confidence.
Using a DP-100 practice exam free is one of the best ways to:
- Experience the format and difficulty of the real exam
- Identify your strengths and focus on weak areas
- Improve your test-taking speed and accuracy
Below, you will find 50 realistic DP-100 practice exam free questions covering key exam topics. Each question reflects the structure and challenge of the actual exam.
You create a batch inference pipeline by using the Azure ML SDK. You configure the pipeline parameters by executing the following code:You need to obtain the output from the pipeline execution. Where will you find the output?
A. the digit_identification.py script
B. the debug log
C. the Activity Log in the Azure portal for the Machine Learning workspace
D. the Inference Clusters tab in Machine Learning studio
E. a file named parallel_run_step.txt located in the output folder
HOTSPOT - You are analyzing the asymmetry in a statistical distribution. The following image contains two density curves that show the probability distribution of two datasets.Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - A biomedical research company plans to enroll people in an experimental medical treatment trial. You create and train a binary classification model to support selection and admission of patients to the trial. The model includes the following features: Age, Gender, and Ethnicity. The model returns different performance metrics for people from different ethnic groups. You need to use Fairlearn to mitigate and minimize disparities for each category in the Ethnicity feature. Which technique and constraint should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You have an Azure Machine Learning workspace. You plan to use the Azure Machine Learning SDK for Python v1 to submit a job to run a training script. You need to complete the script to ensure that it will execute the training script. How should you complete the script? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


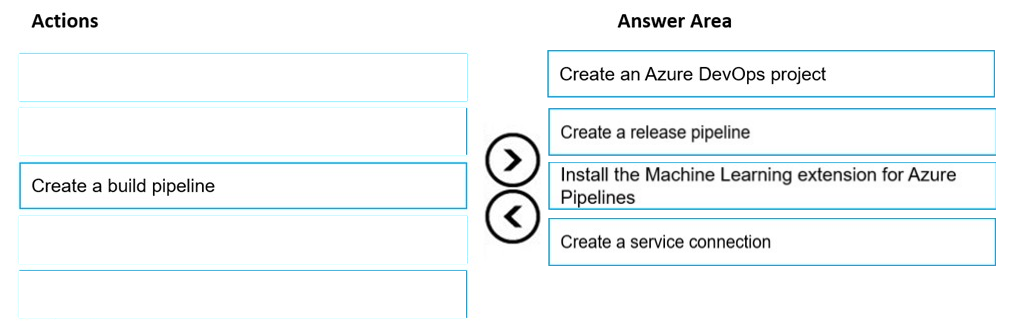
DRAG DROP - You have an Azure Machine Learning workspace. You are running an experiment on your local computer. You need to use MLflow Tracking to store metrics and artifacts from your local experiment runs in the workspace. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


HOTSPOT - You create a new Azure Machine Learning workspace with a compute cluster. You need to create the compute cluster asynchronously by using the Azure Machine Learning Python SDK v2. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


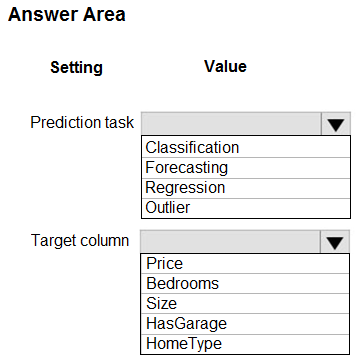
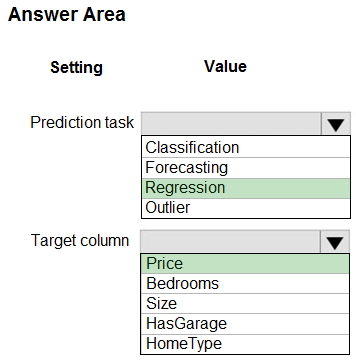
HOTSPOT - You have a dataset that includes home sales data for a city. The dataset includes the following columns.Each row in the dataset corresponds to an individual home sales transaction. You need to use automated machine learning to generate the best model for predicting the sales price based on the features of the house. Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You need to select a feature extraction method. Which method should you use?
A. Mutual information
B. Mood’s median test
C. Kendall correlation
D. Permutation Feature Importance
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have the following Azure subscriptions and Azure Machine Learning service workspaces:You need to obtain a reference to the ml-project workspace. Solution: Run the following Python code:
Does the solution meet the goal?
A. Yes
B. No
You are developing deep learning models to analyze semi-structured, unstructured, and structured data types. You have the following data available for model building: ✑ Video recordings of sporting events ✑ Transcripts of radio commentary about events ✑ Logs from related social media feeds captured during sporting events You need to select an environment for creating the model. Which environment should you use?
A. Azure Cognitive Services
B. Azure Data Lake Analytics
C. Azure HDInsight with Spark MLib
D. Azure Machine Learning Studio
HOTSPOT - You create a Python script named train.py and save it in a folder named scripts. The script uses the scikit-learn framework to train a machine learning model. You must run the script as an Azure Machine Learning experiment on your local workstation. You need to write Python code to initiate an experiment that runs the train.py script. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


You create a datastore named training_data that references a blob container in an Azure Storage account. The blob container contains a folder named csv_files in which multiple comma-separated values (CSV) files are stored. You have a script named train.py in a local folder named ./script that you plan to run as an experiment using an estimator. The script includes the following code to read data from the csv_files folder:You have the following script.
You need to configure the estimator for the experiment so that the script can read the data from a data reference named data_ref that references the csv_files folder in the training_data datastore. Which code should you use to configure the estimator? A.
B.
C.
D.
E.

HOTSPOT - You are designing a machine learning solution. You have the following requirements: • Use a training script to train a machine learning model. • Build a machine learning proof of concept without the use of code or script. You need to select a development tool for each requirement. Which development tool should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are performing feature engineering on a dataset. You must add a feature named CityName and populate the column value with the text London. You need to add the new feature to the dataset. Which Azure Machine Learning Studio module should you use?
A. Extract N-Gram Features from Text
B. Edit Metadata
C. Preprocess Text
D. Apply SQL Transformation
You have an Azure Machine Learning workspace. You plan to run a job to train a model as an MLflow model output. You need to specify the output mode of the MLflow model. Which three modes can you specify? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. rw_mount
B. ro_mount
C. upload
D. download
E. direct
DRAG DROP - You have an Azure Machine Learning workspace named WS1 and a GitHub account named account1 that hosts a private repository named repo1. You need to clone repo1 to make it available directly from WS1. The configuration must maximize the performance of the repo1 clone. Which four actions should you perform in sequence?


You use the designer to create a training pipeline for a classification model. The pipeline uses a dataset that includes the features and labels required for model training. You create a real-time inference pipeline from the training pipeline. You observe that the schema for the generated web service input is based on the dataset and includes the label column that the model predicts. Client applications that use the service must not be required to submit this value. You need to modify the inference pipeline to meet the requirement. What should you do?
A. Add a Select Columns in Dataset module to the inference pipeline after the dataset and use it to select all columns other than the label.
B. Delete the dataset from the training pipeline and recreate the real-time inference pipeline.
C. Delete the Web Service Input module from the inference pipeline.
D. Replace the dataset in the inference pipeline with an Enter Data Manually module that includes data for the feature columns but not the label column.
HOTSPOT - You are preparing to build a deep learning convolutional neural network model for image classification. You create a script to train the model using CUDA devices. You must submit an experiment that runs this script in the Azure Machine Learning workspace. The following compute resources are available: ✑ a Microsoft Surface device on which Microsoft Office has been installed. Corporate IT policies prevent the installation of additional software ✑ a Compute Instance named ds-workstation in the workspace with 2 CPUs and 8 GB of memory ✑ an Azure Machine Learning compute target named cpu-cluster with eight CPU-based nodes ✑ an Azure Machine Learning compute target named gpu-cluster with four CPU and GPU-based nodes You need to specify the compute resources to be used for running the code to submit the experiment, and for running the script in order to minimize model training time. Which resources should the data scientist use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You use an Azure Machine Learning workspace. The default datastore contains comma-separated values (CSV) files. The CSV files must be made available for use in experiments and data processing pipelines. The files must be loaded directly into pandas dataframes. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


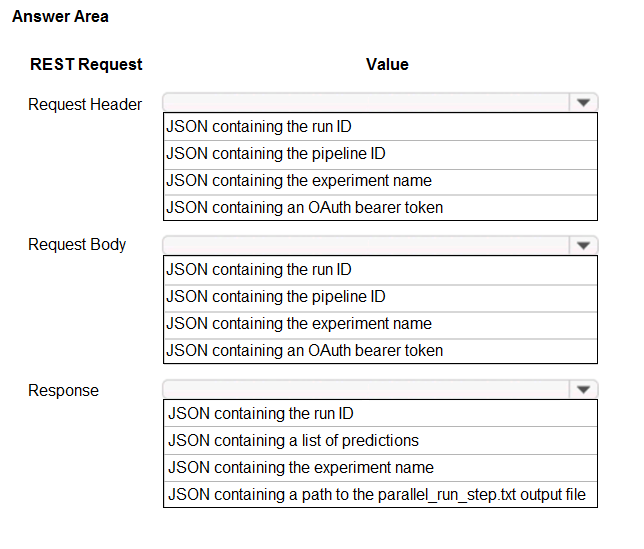
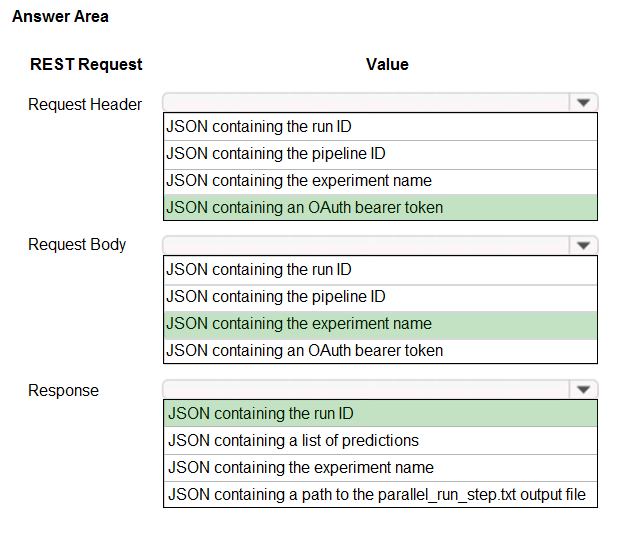
HOTSPOT - You publish a batch inferencing pipeline that will be used by a business application. The application developers need to know which information should be submitted to and returned by the REST interface for the published pipeline. You need to identify the information required in the REST request and returned as a response from the published pipeline. Which values should you use in the REST request and to expect in the response? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are analyzing a numerical dataset which contains missing values in several columns. You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set. You need to analyze a full dataset to include all values. Solution: Use the Last Observation Carried Forward (LOCF) method to impute the missing data points. Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are using Azure Machine Learning to run an experiment that trains a classification model. You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted. You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric. Solution: Run the following code:
Does the solution meet the goal?
A. Yes
B. No
You use the Azure Machine Learning SDK to run a training experiment that trains a classification model and calculates its accuracy metric. The model will be retrained each month as new data is available. You must register the model for use in a batch inference pipeline. You need to register the model and ensure that the models created by subsequent retraining experiments are registered only if their accuracy is higher than the currently registered model. What are two possible ways to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Specify a different name for the model each time you register it.
B. Register the model with the same name each time regardless of accuracy, and always use the latest version of the model in the batch inferencing pipeline.
C. Specify the model framework version when registering the model, and only register subsequent models if this value is higher.
D. Specify a property named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy property value of the currently registered model.
E. Specify a tag named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy tag value of the currently registered model.
You are planning to host practical training to acquaint learners with data visualization creation using Python. Learner devices are able to connect to the internet. Learner devices are currently NOT configured for Python development. Also, learners are unable to install software on their devices as they lack administrator permissions. Furthermore, they are unable to access Azure subscriptions. It is imperative that learners are able to execute Python-based data visualization code. Which of the following actions should you take?
A. You should consider configuring the use of Azure Container Instance.
B. You should consider configuring the use of Azure BatchAI.
C. You should consider configuring the use of Azure Notebooks.
D. You should consider configuring the use of Azure Kubernetes Service.
HOTSPOT - You have an Azure blob container that contains a set of TSV files. The Azure blob container is registered as a datastore for an Azure Machine Learning service workspace. Each TSV file uses the same data schema. You plan to aggregate data for all of the TSV files together and then register the aggregated data as a dataset in an Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python. You run the following code.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


You manage an Azure Machine Learning workspace by using the Azure CLI ml extension v2. You need to define a YAML schema to create a compute cluster. Which schema should you use?
A. https://azuremlschemas.azureedge.net/latest/computeInstance.schema.json
B. https://azuremlschemas.azureedge.net/latest/amlCompute.schema.json
C. https://azuremlschemas.azureedge.net/latest/vmCompute.schema.json
D. https://azuremlschemas.azureedge.net/latest/kubernetesCompute.schema.json
You create an Azure Machine Learning workspace. You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics. You need to implement the method to log the string metrics. Which method should you use?
A. mlflow.log_artifact()
B. mlflow.log.dict()
C. mlflow.log_metric()
D. mlflow.log_text()
DRAG DROP - You create an Azure Machine Learning workspace. You must implement dedicated compute for model training in the workspace by using Azure Synapse compute resources. The solution must attach the dedicated compute and start an Azure Synapse session. You need to implement the computer resources. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You create a binary classification model. You need to evaluate the model performance. Which two metrics can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. relative absolute error
B. precision
C. accuracy
D. mean absolute error
E. coefficient of determination
You create an Azure Machine Learning workspace named workspace1. The workspace contains a Python SDK v2 notebook that uses MLflow to collect model training metrics and artifacts from your local computer. You must reuse the notebook to run on Azure Machine Learning compute instance in workspace1. You need to continue to log metrics and artifacts from your data science code. What should you do?
A. Instantiate the job class.
B. Instantiate the MLCIient class.
C. Log in to workspace1.
D. Configure the tracking URL.
HOTSPOT - You manage an Azure Machine Learning workspace by using the Python SDK v2. You must create a compute cluster in the workspace. The compute cluster must run workloads and property handle interruptions. You start by calculating the maximum amount of compute resources required by the workloads and size the cluster to match the calculations. The cluster definition includes the following properties and values: • names=“mlcluster” • size=“STANDARD_DS3_v2” • min_instances=1 • max_instances=4 • tier=“dedicated“ The cost of the compute resources must be minimized when a workload is active or idle. Cluster property changes must not affect the maximum amount of compute resources available to the workloads run on the cluster. You need to modify the cluster properties to minimize the cost of compute resources. Which properties should you modify? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You are using Azure Machine Learning to monitor a trained and deployed model. You implement Event Grid to respond to Azure Machine Learning events. Model performance has degraded due to model input data changes. You need to trigger a remediation ML pipeline based on an Azure Machine Learning event. Which event should you use?
A. RunStatusChanged
B. RunCompleted
C. DatasetDriftDetected
D. ModelDeployed
HOTSPOT - You plan to use Hyperdrive to optimize the hyperparameters selected when training a model. You create the following code to define options for the hyperparameter experiment:For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are a data scientist using Azure Machine Learning Studio. You need to normalize values to produce an output column into bins to predict a target column. Solution: Apply a Quantiles binning mode with a PQuantile normalization. Does the solution meet the goal?
A. Yes
B. No
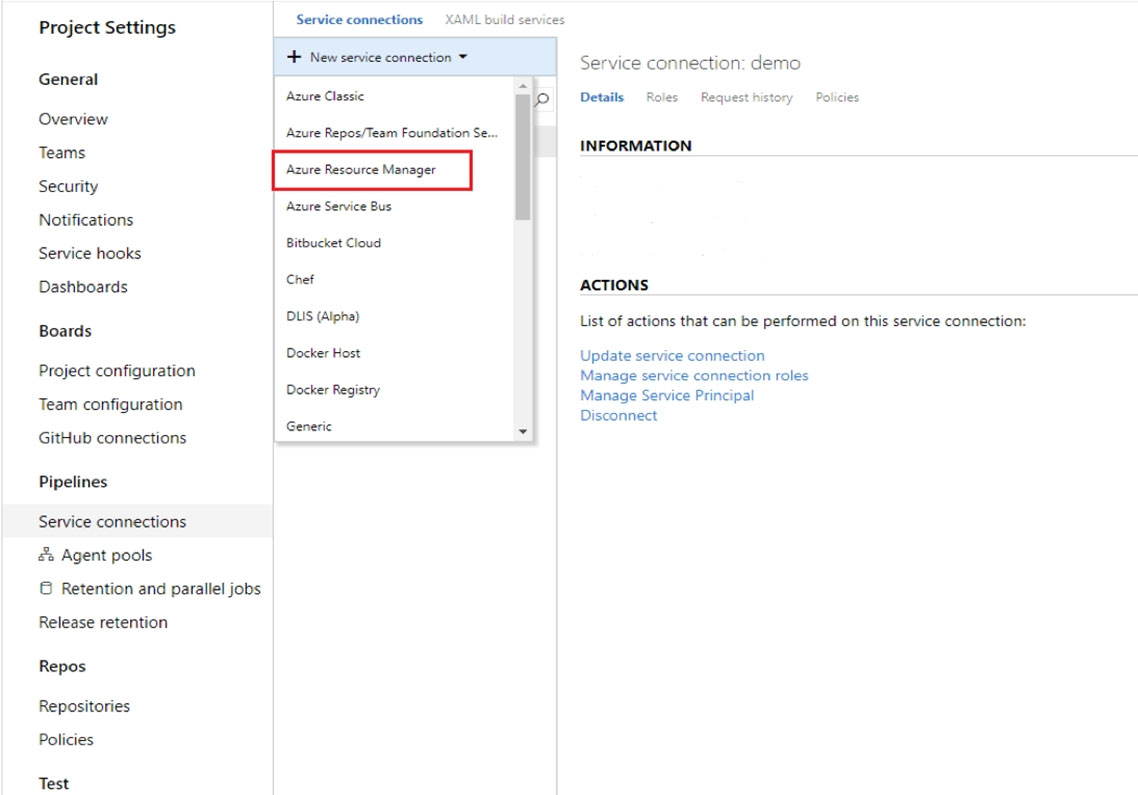
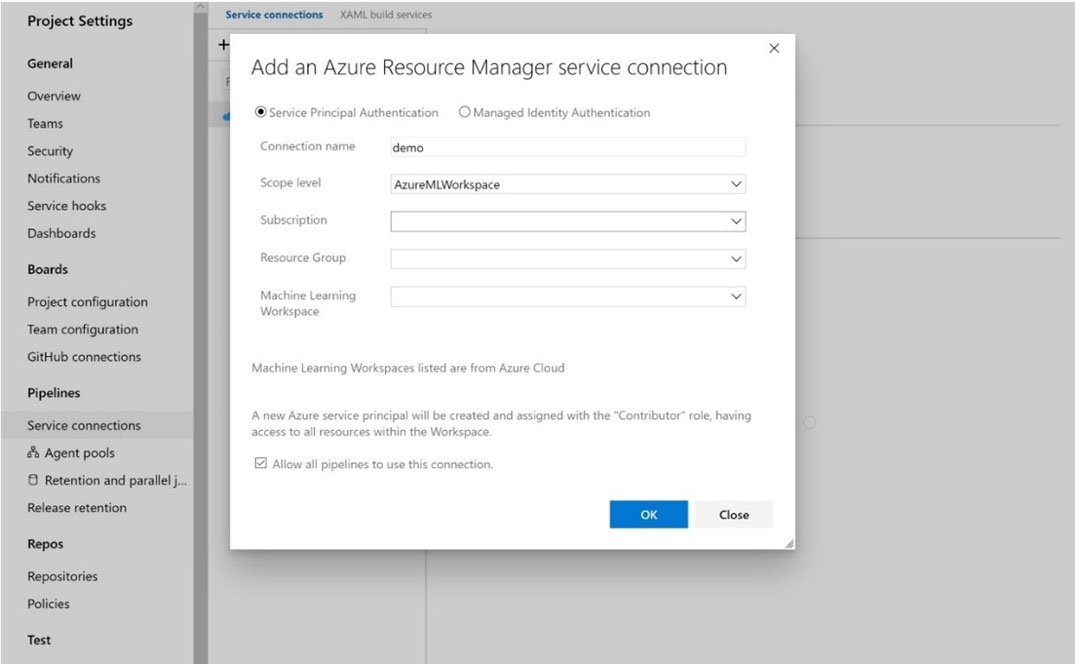
DRAG DROP - You create an Azure Machine Learning workspace and a new Azure DevOps organization. You register a model in the workspace and deploy the model to the target environment. All new versions of the model registered in the workspace must automatically be deployed to the target environment. You need to configure Azure Pipelines to deploy the model. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder. You must run the script as an Azure ML experiment on a compute cluster named aml-compute. You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml- compute that references the target compute cluster. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
You use the Azure Machine Learning designer to create and run a training pipeline. The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset. You need to publish the pipeline as a REST service that can be used for the nightly inferencing run. What should you do?
A. Create a batch inference pipeline
B. Set the compute target for the pipeline to an inference cluster
C. Create a real-time inference pipeline
D. Clone the pipeline
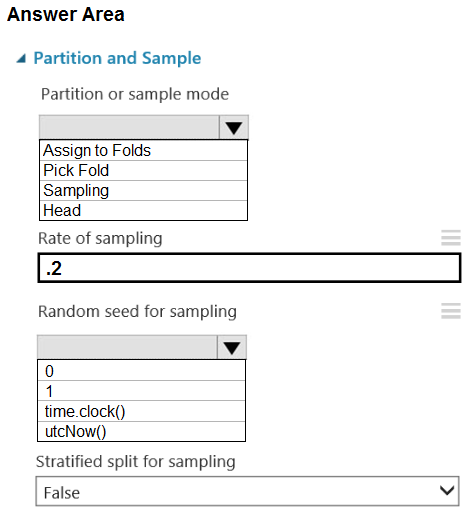
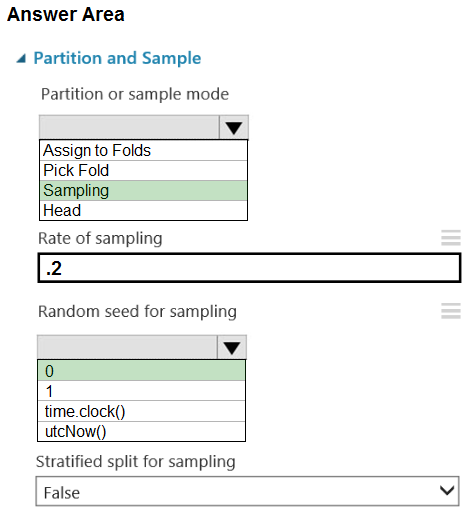
HOTSPOT - You are retrieving data from a large datastore by using Azure Machine Learning Studio. You must create a subset of the data for testing purposes using a random sampling seed based on the system clock. You add the Partition and Sample module to your experiment. You need to select the properties for the module. Which values should you select? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
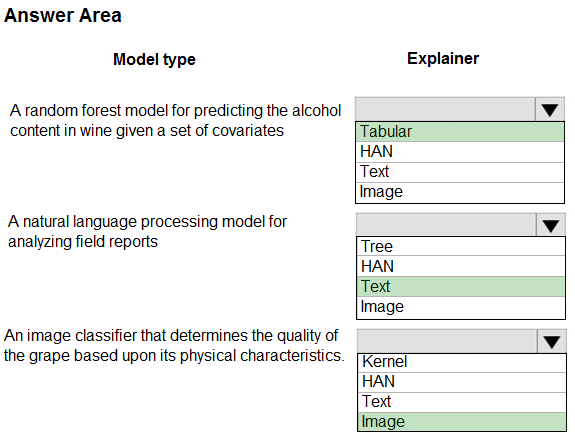
HOTSPOT - You are hired as a data scientist at a winery. The previous data scientist used Azure Machine Learning. You need to review the models and explain how each model makes decisions. Which explainer modules should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

You train and register a model in your Azure Machine Learning workspace. You must publish a pipeline that enables client applications to use the model for batch inferencing. You must use a pipeline with a single ParallelRunStep step that runs a Python inferencing script to get predictions from the input data. You need to create the inferencing script for the ParallelRunStep pipeline step. Which two functions should you include? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. run(mini_batch)
B. main()
C. batch()
D. init()
E. score(mini_batch)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder. You must run the script as an Azure ML experiment on a compute cluster named aml-compute. You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml- compute that references the target compute cluster. Solution: Run the following code:Does the solution meet the goal?
A. Yes
B. No
You have an Azure Machine Learning workspace. You are connecting an Azure Data Lake Storage Gen2 account to the workspace as a data store. You need to authorize access from the workspace to the Azure Data Lake Storage Gen2 account. What should you use?
A. Service principal
B. SAS token
C. Managed identity
D. Account key
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You train and register a machine learning model. You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model. You need to deploy the web service. Solution: Create an AciWebservice instance. Set the value of the auth_enabled property to False. Set the value of the token_auth_enabled property to True. Deploy the model to the service. Does the solution meet the goal?
A. Yes
B. No
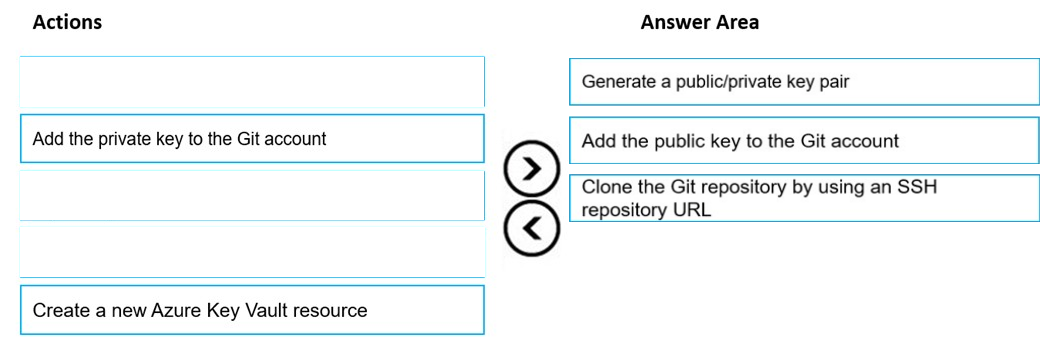
DRAG DROP - You are using a Git repository to track work in an Azure Machine Learning workspace. You need to authenticate a Git account by using SSH. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:

You plan to run a Python script as an Azure Machine Learning experiment. The script must read files from a hierarchy of folders. The files will be passed to the script as a dataset argument. You must specify an appropriate mode for the dataset argument. Which two modes can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. to_pandas_dataframe()
B. as_download()
C. as_upload()
D. as_mount()
HOTSPOT - Complete the sentence by selecting the correct option in the answer area. Hot Area:


You create an Azure Machine Learning workspace named workspaces. You create a Python SDK v2 notebook to perform custom model training in workspaces. You need to run the notebook from Azure Machine Learning Studio in workspaces. What should you provision first?
A. default storage account
B. real-time endpoint
C. Azure Machine Learning compute cluster
D. Azure Machine Learning compute instance
Free Access Full DP-100 Practice Exam Free
Looking for additional practice? Click here to access a full set of DP-100 practice exam free questions and continue building your skills across all exam domains.
Our question sets are updated regularly to ensure they stay aligned with the latest exam objectives—so be sure to visit often!
Good luck with your DP-100 certification journey!