DP-201 Practice Questions Free – 50 Exam-Style Questions to Sharpen Your Skills
Are you preparing for the DP-201 certification exam? Kickstart your success with our DP-201 Practice Questions Free – a carefully selected set of 50 real exam-style questions to help you test your knowledge and identify areas for improvement.
Practicing with DP-201 practice questions free gives you a powerful edge by allowing you to:
Understand the exam structure and question formats
Discover your strong and weak areas
Build the confidence you need for test day success
Below, you will find 50 free DP-201 practice questions designed to match the real exam in both difficulty and topic coverage. They’re ideal for self-assessment or final review. You can click on each Question to explore the details.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You schedule an Azure Databricks job that executes an R notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
You are designing a solution that will use Azure Databricks and Azure Data Lake Storage Gen2.
From Databricks, you need to access Data Lake Storage directly by using a service principal.
What should you include in the solution?
A. shared access signatures (SAS) in Data Lake Storage
B. access keys in Data Lake Storage
C. an organizational relationship in Azure Active Directory (Azure AD)
D. an application registration in Azure Active Directory (Azure AD)
Suggested Answer: D
Create and grant permissions to service principal
If your selected the access method requires a service principal with adequate permissions, and you do not have one, follow these steps:
1. Create an Azure AD application and service principal that can access resources. Note the following properties:
✑ client-id: An ID that uniquely identifies the application.
✑ directory-id: An ID that uniquely identifies the Azure AD instance.
✑ service-credential: A string that the application uses to prove its identity.
2. Register the service principal, granting the correct role assignment, such as Storage Blob Data
3. Contributor, on the Azure Data Lake Storage Gen2 account.
Reference: https://docs.databricks.com/data/data-sources/azure/azure-datalake-gen2.html
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Data Factory instance using Azure PowerShell
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics cloud job using Azure PowerShell
D. Azure Data Factory instance using Microsoft Visual Studio
Suggested Answer: C
Stream Analytics is a cost-effective event processing engine that helps uncover real-time insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and powershell scripting that execute basic Stream Analytics tasks.
Note: Visual Studio 2019 and Visual Studio 2017 also support Stream Analytics Tools.
Reference: https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaming-analytics-data-production-and-workflow-services-to-azure/
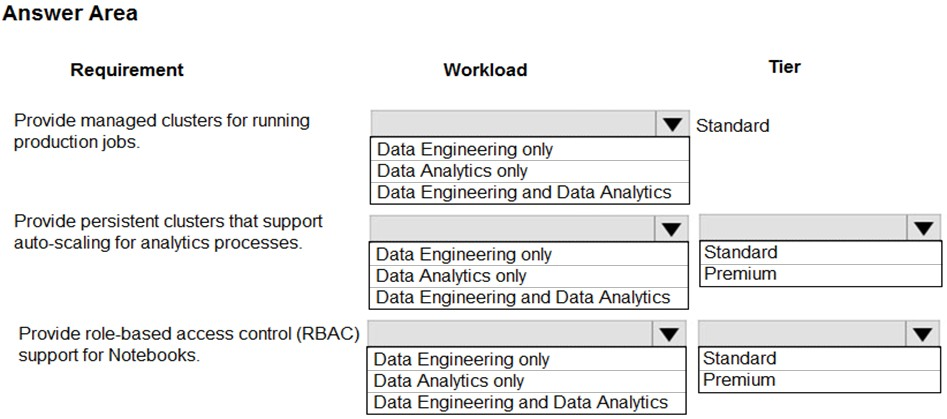
HOTSPOT -
You are designing a solution for a company. You plan to use Azure Databricks.
You need to recommend workloads and tiers to meet the following requirements:
✑ Provide managed clusters for running production jobs.
✑ Provide persistent clusters that support auto-scaling for analytics processes.
✑ Provide role-based access control (RBAC) support for Notebooks.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
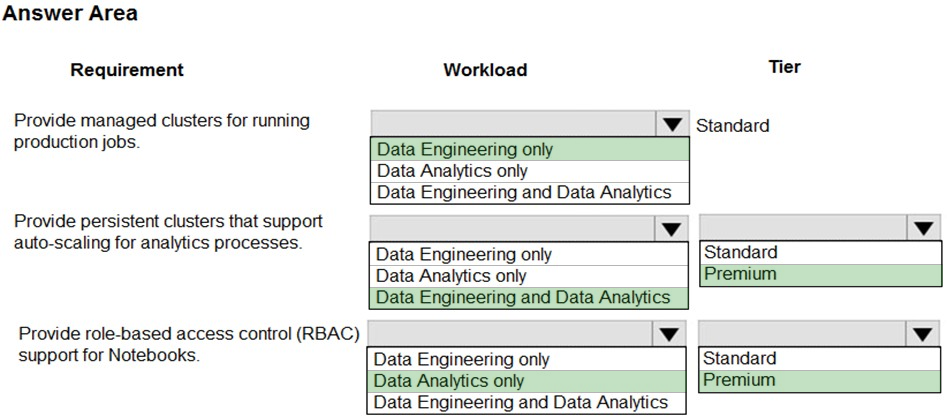
Suggested Answer:
Box 1: Data Engineering Only –
Box 2: Data Engineering and Data Analytics
Box 3: Standard –
Box 4: Data Analytics only –
Box 5: Premium –
Premium required for RBAC. Data Analytics Premium Tier provide interactive workloads to analyze data collaboratively with notebooks
Reference: https://azure.microsoft.com/en-us/pricing/details/databricks/
What should you do to improve high availability of the real-time data processing solution?
A. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
B. Deploy a High Concurrency Databricks cluster.
C. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
D. Set Data Lake Storage to use geo-redundant storage (GRS).
Suggested Answer: A
Guarantee Stream Analytics job reliability during service updates
Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
Design for high availability and disaster recovery
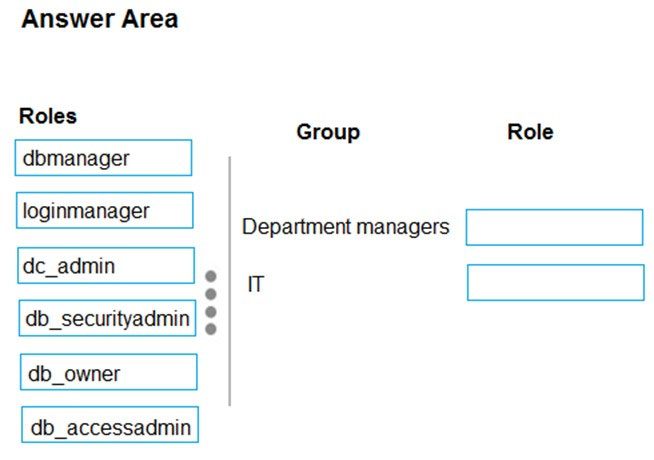
DRAG DROP -
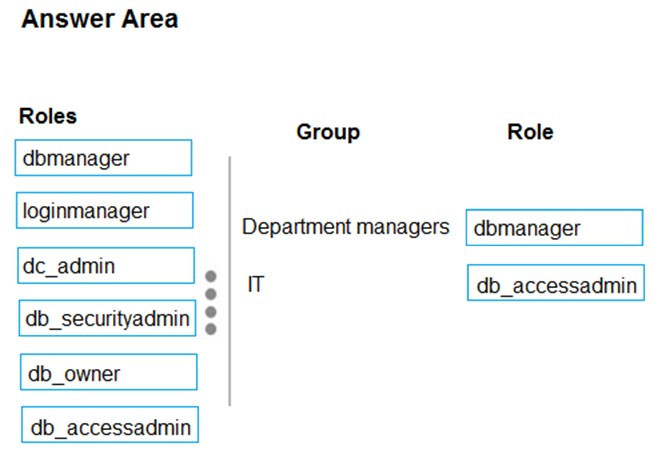
You are designing a data warehouse in Azure Synapse Analytics for a financial services company. Azure Active Directory will be used to authenticate the users.
You need to ensure that the following security requirements are met:
✑ Department managers must be able to create new database.
✑ The IT department must assign users to databases.
✑ Permissions granted must be minimized.
Which role memberships should you recommend? To answer, drag the appropriate roles to the correct groups. Each role may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: dbmanager –
Members of the dbmanager role can create new databases.
Box 2: db_accessadmin –
Members of the db_accessadmin fixed database role can add or remove access to the database for Windows logins, Windows groups, and SQL Server logins.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-manage-logins
HOTSPOT -
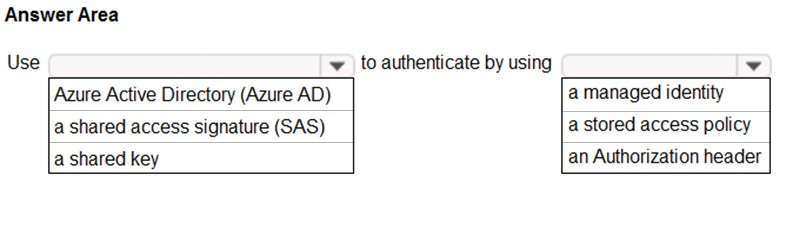
You have an Azure subscription that contains an Azure Data Lake Storage account. The storage account contains a data lake named DataLake1.
You plan to use an Azure data factory to ingest data from a folder in DataLake1, transform the data, and land the data in another folder.
You need to ensure that the data factory can read and write data from any folder in the DataLake1 file system. The solution must meet the following requirements:
✑ Minimize the risk of unauthorized user access.
✑ Use the principle of least privilege.
✑ Minimize maintenance effort.
How should you configure access to the storage account for the data factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area:
Suggested Answer:
Box 1: Azure Active Directory (Azure AD)
On Azure, managed identities eliminate the need for developers having to manage credentials by providing an identity for the Azure resource in Azure AD and using it to obtain Azure Active Directory (Azure AD) tokens.
Box 2: a managed identity –
A data factory can be associated with a managed identity for Azure resources, which represents this specific data factory. You can directly use this managed identity for Data Lake Storage Gen2 authentication, similar to using your own service principal. It allows this designated factory to access and copy data to or from your Data Lake Storage Gen2.
Note: The Azure Data Lake Storage Gen2 connector supports the following authentication types.
✑ Account key authentication
✑ Service principal authentication
✑ Managed identities for Azure resources authentication
Reference: https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
HOTSPOT -
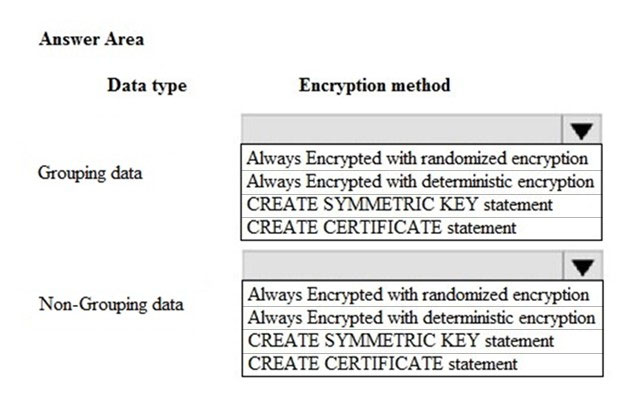
A company plans to use Azure SQL Database to support a line of business application. The application will manage sensitive employee data.
The solution must meet the following requirements:
✑ Encryption must be performed by the application.
✑ Only the client application must have access keys for encrypting and decrypting data.
✑ Data must never appear as plain text in the database.
✑ The strongest possible encryption method must be used.
✑ Grouping must be possible on selected data.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: Always Encrypted with deterministic encryption
Deterministic encryption always generates the same encrypted value for any given plain text value. Using deterministic encryption allows point lookups, equality joins, grouping and indexing on encrypted columns. However, it may also allow unauthorized users to guess information about encrypted values by examining patterns in the encrypted column, especially if there is a small set of possible encrypted values, such as True/False, or North/South/East/West region.
Deterministic encryption must use a column collation with a binary2 sort order for character columns.
Box 2: Always Encrypted with Randomized encryption
✑ Randomized encryption uses a method that encrypts data in a less predictable manner. Randomized encryption is more secure, but prevents searching, grouping, indexing, and joining on encrypted columns.
Note: With Always Encrypted the Database Engine never operates on plaintext data stored in encrypted columns, but it still supports some queries on encrypted data, depending on the encryption type for the column. Always Encrypted supports two types of encryption: randomized encryption and deterministic encryption.
Use deterministic encryption for columns that will be used as search or grouping parameters, for example a government ID number. Use randomized encryption, for data such as confidential investigation comments, which are not grouped with other records and are not used to join tables.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-database-engine
HOTSPOT -
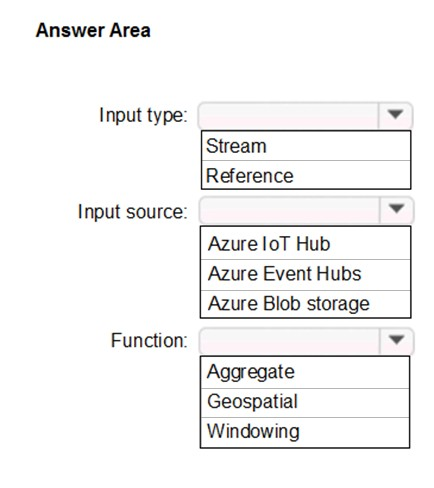
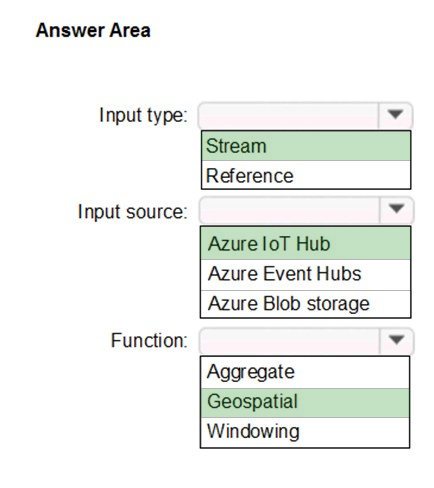
You plan to create a real-time monitoring app that alerts users when a device travels more than 200 meters away from a designated location.
You need to design an Azure Stream Analytics job to process the data for the planned app. The solution must minimize the amount of code developed and the number of technologies used.
What should you include in the Stream Analytics job? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You are designing a storage solution for streaming data that is processed by Azure Databricks. The solution must meet the following requirements:
✑ The data schema must be fluid.
✑ The source data must have a high throughput.
✑ The data must be available in multiple Azure regions as quickly as possible.
What should you include in the solution to meet the requirements?
A. Azure Cosmos DB
B. Azure Synapse Analytics
C. Azure SQL Database
D. Azure Data Lake Storage
Suggested Answer: A
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database. Azure Cosmos DB enables you to elastically and independently scale throughput and storage across any number of Azure’s geographic regions. It offers throughput, latency, availability, and consistency guarantees with comprehensive service level agreements (SLAs).
You can read data from and write data to Azure Cosmos DB using Databricks.
Note on fluid schema:
If you are managing data whose structures are constantly changing at a high rate, particularly if transactions can come from external sources where it is difficult to enforce conformity across the database, you may want to consider a more schema-agnostic approach using a managed NoSQL database service like Azure
Cosmos DB.
Reference: https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html https://docs.microsoft.com/en-us/azure/cosmos-db/relational-nosql
You need to design a backup solution for the processed customer data.
What should you include in the design?
A. AzCopy
B. AdlCopy
C. Geo-Redundancy
D. Geo-Replication
Suggested Answer: C
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9’s) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database that has columns. The columns contain sensitive Personally Identifiable Information (PII) data.
You need to design a solution that tracks and stores all the queries executed against the PII data. You must be able to review the data in Azure Monitor, and the data must be available for at least 45 days.
Solution: You execute a daily stored procedure that retrieves queries from Query Store, looks up the column classifications, and stores the results in a new table in the database.
Does this meet the goal?
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Data Factory instance using the Azure portal
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics Edge application using Microsoft Visual Studio
You are planning a big data solution in Azure.
You need to recommend a technology that meets the following requirements:
✑ Be optimized for batch processing.
✑ Support autoscaling.
✑ Support per-cluster scaling.
Which technology should you recommend?
A. Azure Synapse Analytics
B. Azure HDInsight with Spark
C. Azure Analysis Services
D. Azure Databricks
Suggested Answer: D
Azure Databricks is an Apache Spark-based analytics platform. Azure Databricks supports autoscaling and manages the Spark cluster for you.
Incorrect Answers:
A, B:
<img src=”https://www.examtopics.com/assets/media/exam-media/03774/0025000001.png” alt=”Reference Image” />
You need to design a telemetry data solution that supports the analysis of log files in real time.
Which two Azure services should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Azure Databricks
B. Azure Data Factory
C. Azure Event Hubs
D. Azure Data Lake Storage Gen2
Suggested Answer: AC
You connect a data ingestion system with Azure Databricks to stream data into an Apache Spark cluster in near real-time. You set up data ingestion system using
Azure Event Hubs and then connect it to Azure Databricks to process the messages coming through.
Note: Azure Event Hubs is a highly scalable data streaming platform and event ingestion service, capable of receiving and processing millions of events per second. Event Hubs can process and store events, data, or telemetry produced by distributed software and devices. Data sent to an event hub can be transformed and stored using any real-time analytics provider or batching/storage adapters.
Reference: https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs
You are designing the security for an Azure SQL database.
You have an Azure Active Directory (Azure AD) group named Group1.
You need to recommend a solution to provide Group1 with read access to the database only.
What should you include in the recommendation?
A. a contained database user
B. a SQL login
C. an RBAC role
D. a shared access signature (SAS)
Suggested Answer: A
Create a User for a security group
A best practice for managing your database is to use Windows security groups to manage user access. That way you can simply manage the customer at the
Security Group level in Active Directory granting appropriate permissions. To add a security group to SQL Data Warehouse, you use the Display Name of the security group as the principal in the CREATE USER statement.
CREATE USER [] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA = [<schema>];
In our AD instance, we have a security group called Sales Team with an alias of
salesteam@company.com
. To add this security group to SQL Data Warehouse you simply run the following statement:
CREATE USER [Sales Team] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA = [sales];
Reference: https://blogs.msdn.microsoft.com/sqldw/2017/07/28/adding-ad-users-and-security-groups-to-azure-sql-data-warehouse/
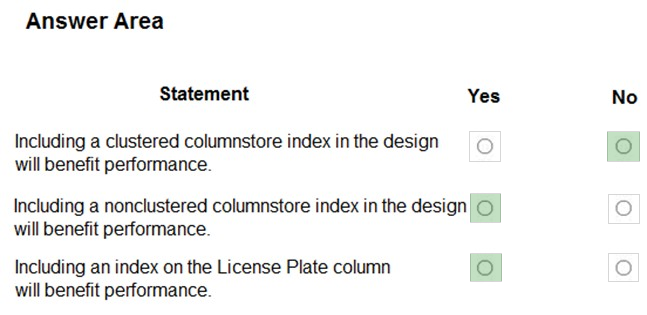
You need to design the storage for the visual monitoring system.
Which storage solution should you recommend?
A. Azure Blob storage
B. Azure Table storage
C. Azure SQL database
D. Azure Cosmos DB
Suggested Answer: A
Azure Blobs: A massively scalable object store for text and binary data.
Azure Cognitive Search supports fuzzy search. You can use Azure Cognitive Search to index blobs.
Scenario:
✑ The visual monitoring system is a network of approximately 1,000 cameras placed near highways that capture images of vehicle traffic every 2 seconds. The cameras record high resolution images. Each image is approximately 3 MB in size.
✑ The solution must allow for searches of vehicle images by license plate to support law enforcement investigations. Searches must be able to be performed using a query language and must support fuzzy searches to compensate for license plate detection errors.
Incorrect Answers:
B: Azure Tables: A NoSQL store for schemaless storage of structured data.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/search/search-howto-indexing-azure-blob-storage#how-azure-cognitive-search-indexes-blobs
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for
CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID.
Proposed Solution: Separate data into shards by using horizontal partitioning.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: A
Horizontal Partitioning – Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier. With this approach, the schema is identical on all participating databases. This approach is also called ג€shardingג€. Sharding can be performed and managed using (1) the elastic database tools libraries or (2) self- sharding. An elastic query is used to query or compile reports across many shards.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
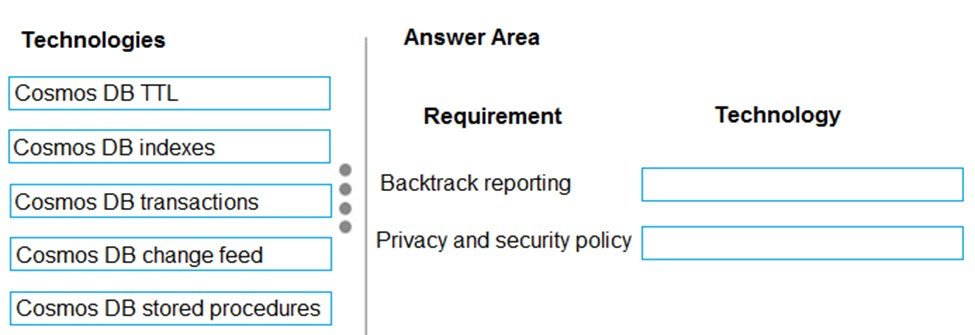
DRAG DROP -
You need to ensure that performance requirements for Backtrack reports are met.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Box 1: Cosmos DB indexes –
The report for Backtrack must execute as quickly as possible.
You can override the default indexing policy on an Azure Cosmos container, this could be useful if you want to tune the indexing precision to improve the query performance or to reduce the consumed storage.
Box 2: Cosmos DB TTL –
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection. Users must be able to filter vehicle data in the following ways:
✑ vehicles on a specific road
✑ vehicles driving above the speed limit
Note: With Time to Live or TTL, Azure Cosmos DB provides the ability to delete items automatically from a container after a certain time period. By default, you can set time to live at the container level and override the value on a per-item basis. After you set the TTL at a container or at an item level, Azure Cosmos DB will automatically remove these items after the time period, since the time they were last modified.
Incorrect Answers:
Cosmos DB stored procedures: Stored procedures are best suited for operations that are write heavy. When deciding where to use stored procedures, optimize around encapsulating the maximum amount of writes possible. Generally speaking, stored procedures are not the most efficient means for doing large numbers of read operations so using stored procedures to batch large numbers of reads to return to the client will not yield the desired benefit.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/index-policy https://docs.microsoft.com/en-us/azure/cosmos-db/time-to-live
You are designing a storage solution to store CSV files.
You need to grant a data scientist access to read all the files in a single container of an Azure Storage account. The solution must use the principle of least privilege and provide the highest level of security.
What are two possible ways to achieve the goal? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provide an access key.
B. Assign the Storage Blob Data Reader role at the container level.
C. Assign the Reader role to the storage account.
D. Provide an account shared access signature (SAS).
E. Provide a user delegation shared access signature (SAS).
Suggested Answer: BE
B: When an Azure role is assigned to an Azure AD security principal, Azure grants access to those resources for that security principal. Access can be scoped to the level of the subscription, the resource group, the storage account, or an individual container or queue.
The built-in Data Reader roles provide read permissions for the data in a container or queue.
Note: Permissions are scoped to the specified resource.
For example, if you assign the Storage Blob Data Reader role to user Mary at the level of a container named sample-container, then Mary is granted read access to all of the blobs in that container.
E: A user delegation SAS is secured with Azure Active Directory (Azure AD) credentials and also by the permissions specified for the SAS. A user delegation SAS applies to Blob storage only.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-auth-aad-rbac-portal https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Data Factory instance using Azure Portal
B. Azure Analysis Services using Microsoft Visual Studio
C. Azure Stream Analytics cloud job using Azure Portal
D. Azure Data Factory instance using Azure Portal
Suggested Answer: C
The Stream Analytics query language allows to perform CEP (Complex Event Processing) by offering a wide array of functions for analyzing streaming data. This query language supports simple data manipulation, aggregation and analytics functions, geospatial functions, pattern matching and anomaly detection. You can edit queries in the portal or using our development tools, and test them using sample data that is extracted from a live stream.
Note: Stream Analytics is a cost-effective event processing engine that helps uncover real-time insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and powershell scripting that execute basic Stream Analytics tasks.
Reference: https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaming-analytics-data-production-and-workflow-services-to-azure/ https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-introduction
You need to design the solution for the government planning department.
Which services should you include in the design?
A. Azure Synapse Analytics and Elastic Queries
B. Azure SQL Database and Polybase
C. Azure Synapse Analytics and Polybase
D. Azure SQL Database and Elastic Queries
Suggested Answer: C
PolyBase is a new feature in SQL Server 2016. It is used to query relational and non-relational databases (NoSQL) such as CSV files.
Scenario: Traffic data must be made available to the Government Planning Department for the purpose of modeling changes to the highway system. The traffic data will be used in conjunction with other data such as information about events such as sporting events, weather conditions, and population statistics. External data used during the modeling is stored in on-premises SQL Server 2016 databases and CSV files stored in an Azure Data Lake Storage Gen2 storage account.
Reference: https://www.sqlshack.com/sql-server-2016-polybase-tutorial/
A company is evaluating data storage solutions.
You need to recommend a data storage solution that meets the following requirements:
✑ Minimize costs for storing blob objects.
✑ Optimize access for data that is infrequently accessed.
✑ Data must be stored for at least 30 days.
✑ Data availability must be at least 99 percent.
What should you recommend?
A. Premium
B. Cold
C. Hot
D. Archive
Suggested Answer: B
Azure’s cool storage tier, also known as Azure cool Blob storage, is for infrequently-accessed data that needs to be stored for a minimum of 30 days. Typical use cases include backing up data before tiering to archival systems, legal data, media files, system audit information, datasets used for big data analysis and more.
The storage cost for this Azure cold storage tier is lower than that of hot storage tier. Since it is expected that the data stored in this tier will be accessed less frequently, the data access charges are high when compared to hot tier. There are no additional changes required in your applications as these tiers can be accessed using APIs in the same manner that you access Azure storage.
Reference: https://cloud.netapp.com/blog/low-cost-storage-options-on-azure
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script.
Does this meet the goal?
A. Yes
B. No
Suggested Answer: A
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed.
Reference: https://docs.microsoft.com/en-US/azure/data-factory/transform-data
You need to design a sharding strategy for the Planning Assistance database.
What should you recommend?
A. a list mapping shard map on the binary representation of the License Plate column
B. a range mapping shard map on the binary representation of the speed column
C. a list mapping shard map on the location column
D. a range mapping shard map on the time column
Suggested Answer: A
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
A shard typically contains items that fall within a specified range determined by one or more attributes of the data. These attributes form the shard key (sometimes referred to as the partition key). The shard key should be static. It shouldn’t be based on data that might change.
Reference: https://docs.microsoft.com/en-us/azure/architecture/patterns/sharding
DRAG DROP -
You are planning a design pattern based on the Lambda architecture as shown in the exhibit.
Which Azure services should you use for the cold path? To answer, drag the appropriate services to the correct layers. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
DRAG DROP -
You need to design the encryption strategy for the tagging data and customer data.
What should you recommend? To answer, drag the appropriate setting to the correct drop targets. Each source may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the company's data privacy regulations and the users who executed the queries.
Which two components should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. dynamic data masking for columns that contain confidential information
B. sensitivity-classification labels applied to columns that contain confidential information
C. resource tags for databases that contain confidential information
HOTSPOT -
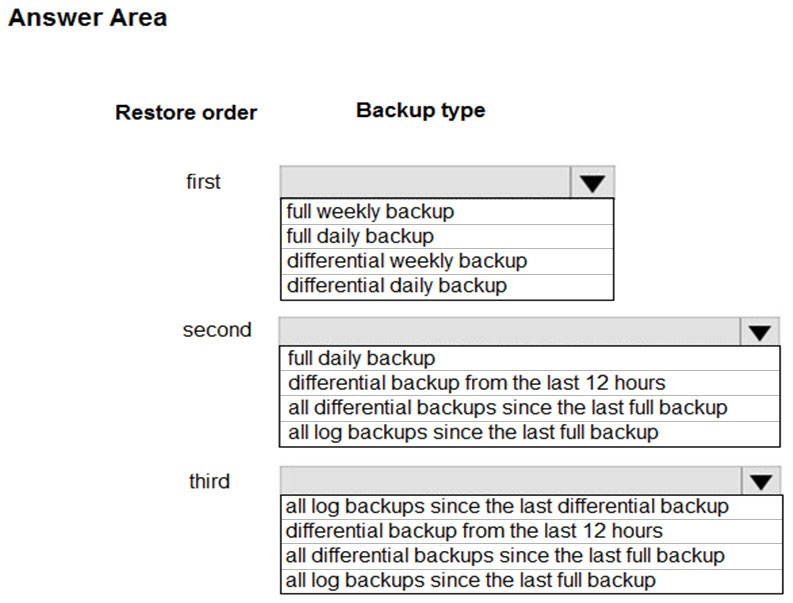
You are designing a recovery strategy for your Azure SQL Databases.
The recovery strategy must use default automated backup settings. The solution must include a Point-in time restore recovery strategy.
You need to recommend which backups to use and the order in which to restore backups.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT -
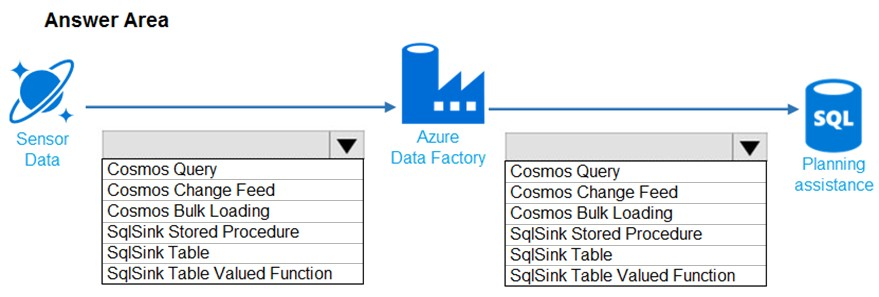
You need to design the data loading pipeline for Planning Assistance.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Hot Area:
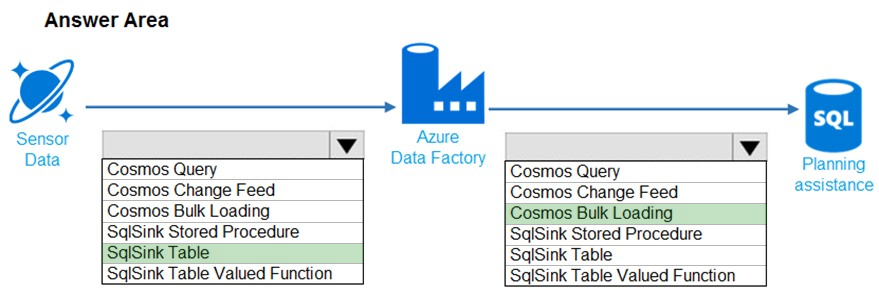
Suggested Answer:
Box 1: SqlSink Table –
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
Box 2: Cosmos Bulk Loading –
Use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
Scenario: Data from the Sensor Data collection will automatically be loaded into the Planning Assistance database once a week by using Azure Data Factory. You must be able to manually trigger the data load process.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
You need to recommend a storage solution to store flat files and columnar optimized files. The solution must meet the following requirements:
✑ Store standardized data that data scientists will explore in a curated folder.
✑ Ensure that applications cannot access the curated folder.
✑ Store staged data for import to applications in a raw folder.
✑ Provide data scientists with access to specific folders in the raw folder and all the content the curated folder.
Which storage solution should you recommend?
A. Azure Synapse Analytics
B. Azure Blob storage
C. Azure Data Lake Storage Gen2
D. Azure SQL Database
Suggested Answer: B
Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Incorrect Answers:
C: Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Reference: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/data-storage
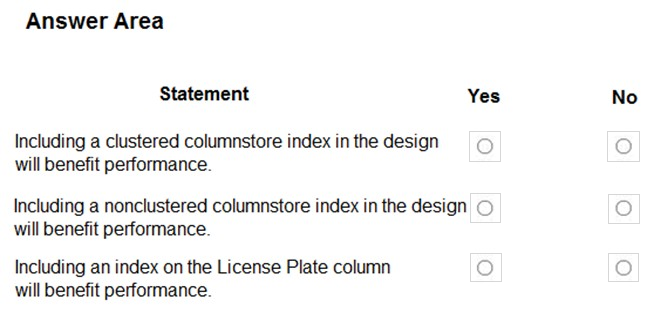
HOTSPOT -
You need to design the Planning Assistance database.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Suggested Answer:
Box 1: No –
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Box 2: Yes –
Box 3: Yes –
Planning Assistance database will include reports tracking the travel of a single vehicle
Design Azure data storage solutions
A company stores sensitive information about customers and employees in Azure SQL Database.
You need to ensure that the sensitive data remains encrypted in transit and at rest.
What should you recommend?
You have an Azure subscription that contains an Azure virtual machine and an Azure Storage account. The virtual machine will access the storage account.
You are planning the security design for the storage account.
You need to ensure that only the virtual machine can access the storage account.
Which two actions should you include in the design? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Select Allow trusted Microsoft services to access this storage account.
B. Select Allow read access to storage logging from any network.
C. Enable a virtual network service endpoint.
D. Set the Allow access from setting to Selected networks.
Suggested Answer: AC
C: Virtual Network (VNet) service endpoint provides secure and direct connectivity to Azure services over an optimized route over the Azure backbone network.
Endpoints allow you to secure your critical Azure service resources to only your virtual networks. Service Endpoints enables private IP addresses in the VNet to reach the endpoint of an Azure service without needing a public IP address on the VNet.
A: You must have Allow trusted Microsoft services to access this storage account turned on under the Azure Storage account Firewalls and Virtual networks settings menu.
Incorrect Answers:
D: Virtual Network (VNet) service endpoint policies allow you to filter egress virtual network traffic to Azure Storage accounts over service endpoint, and allow data exfiltration to only specific Azure Storage accounts. Endpoint policies provide granular access control for virtual network traffic to Azure Storage when connecting over service endpoint.
Reference: https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-service-endpoints-overview
HOTSPOT -
You have an Azure Storage account that generates 200,000 new files daily. The file names have a format of {YYYY}/{MM}/{DD}/{HH}/{CustomerID}.csv.
You need to design an Azure Data Factory solution that will load new data from the storage account to an Azure Data Lake once hourly. The solution must minimize load times and costs.
How should you configure the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area:
Suggested Answer:
Box 1: Incremental load –
When you start to build the end to end data integration flow the first challenge is to extract data from different data stores, where incrementally (or delta) loading data after an initial full load is widely used at this stage. Now, ADF provides a new capability for you to incrementally copy new or changed files only by
LastModifiedDate from a file-based store. By using this new feature, you do not need to partition the data by time-based folder or file name. The new or changed file will be automatically selected by its metadata LastModifiedDate and copied to the destination store.
Box 2: Tumbling window –
Tumbling window triggers are a type of trigger that fires at a periodic time interval from a specified start time, while retaining state. Tumbling windows are a series of fixed-sized, non-overlapping, and contiguous time intervals. A tumbling window trigger has a one-to-one relationship with a pipeline and can only reference a singular pipeline.
Reference: https://azure.microsoft.com/en-us/blog/incrementally-copy-new-files-by-lastmodifieddate-with-azure-data-factory/ https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-tumbling-window-trigger
You are planning a solution that combines log data from multiple systems. The log data will be downloaded from an API and stored in a data store.
You plan to keep a copy of the raw data as well as some transformed versions of the data. You expect that there will be at least 2 TB of log files. The data will be used by data scientists and applications.
You need to recommend a solution to store the data in Azure. The solution must minimize costs.
What storage solution should you recommend?
A. Azure Data Lake Storage Gen2
B. Azure Synapse Analytics
C. Azure SQL Database
D. Azure Cosmos DB
Suggested Answer: A
To land the data in Azure storage, you can move it to Azure Blob storage or Azure Data Lake Store Gen2. In either location, the data should be stored in text files.
PolyBase and the COPY statement can load from either location.
Incorrect Answers:
B: Azure Synapse Analytics, uses distributed query processing architecture that takes advantage of the scalability and flexibility of compute and storage resources. Use Azure Synapse Analytics transform and move the data.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-elt-data-loading
You plan to implement an Azure Data Lake Gen2 storage account.
You need to ensure that the data lake will remain available if a data center fails in the primary Azure region. The solution must minimize costs.
Which type of replication should you use for the storage account?
A. geo-redundant storage (GRS)
B. zone-redundant storage (ZRS)
C. locally-redundant storage (LRS)
D. geo-zone-redundant storage (GZRS)
Suggested Answer: A
Geo-redundant storage (GRS) copies your data synchronously three times within a single physical location in the primary region using LRS. It then copies your data asynchronously to a single physical location in the secondary region.
Incorrect Answers:
B: Zone-redundant storage (ZRS) copies your data synchronously across three Azure availability zones in the primary region. For applications requiring high availability, Microsoft recommends using ZRS in the primary region, and also replicating to a secondary region.
C: Locally redundant storage (LRS) copies your data synchronously three times within a single physical location in the primary region. LRS is the least expensive replication option, but is not recommended for applications requiring high availability.
D: GZRS is more expensive compared to GRS.
Reference: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure Synapse Analytics as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure Synapse Analytics and set retention to 10 days.
Does the solution meet the goal?
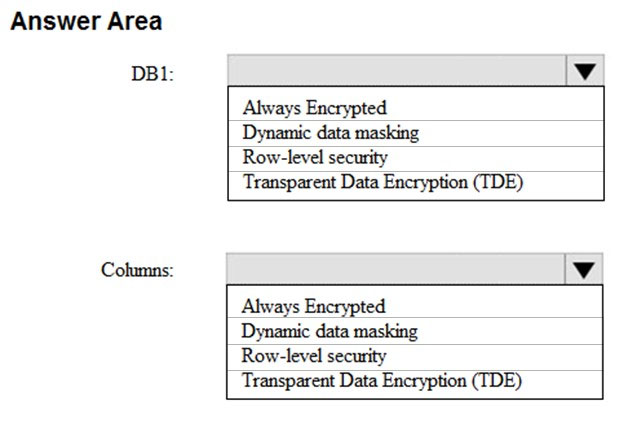
HOTSPOT -
You are designing the security for a mission critical Azure SQL database named DB1. DB1 contains several columns that store Personally Identifiable Information
(PII) data
You need to recommend a security solution that meets the following requirements:
✑ Ensures that DB1 is encrypted at rest
✑ Ensures that data from the columns containing PII data is encrypted in transit
Which security solution should you recommend for DB1 and the columns? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
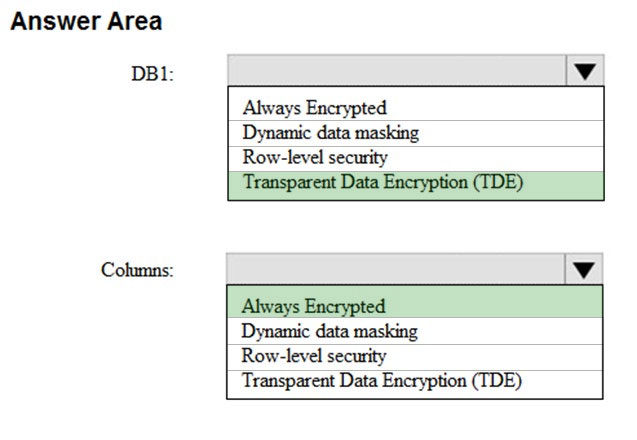
Suggested Answer:
DB1: Transparent Data Encryption
Azure SQL Database currently supports encryption at rest for Microsoft-managed service side and client-side encryption scenarios.
Support for server encryption is currently provided through the SQL feature called Transparent Data Encryption.
Columns: Always encrypted –
Always Encrypted is a feature designed to protect sensitive data stored in Azure SQL Database or SQL Server databases. Always Encrypted allows clients to encrypt sensitive data inside client applications and never reveal the encryption keys to the database engine (SQL Database or SQL Server).
Note: Most data breaches involve the theft of critical data such as credit card numbers or personally identifiable information. Databases can be treasure troves of sensitive information. They can contain customers’ personal data (like national identification numbers), confidential competitive information, and intellectual property. Lost or stolen data, especially customer data, can result in brand damage, competitive disadvantage, and serious fines–even lawsuits.
Reference: https://docs.microsoft.com/en-us/azure/security/fundamentals/encryption-atrest https://docs.microsoft.com/en-us/azure/security/fundamentals/database-security-overview
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database that has columns. The columns contain sensitive Personally Identifiable Information (PII) data.
You need to design a solution that tracks and stores all the queries executed against the PII data. You must be able to review the data in Azure Monitor, and the data must be available for at least 45 days.
Solution: You add classifications to the columns that contain sensitive data. You turn on Auditing and set the audit log destination to use Azure Blob storage.
Does this meet the goal?
A. Yes
B. No
Suggested Answer: A
Auditing has been enhanced to log sensitivity classifications or labels of the actual data that were returned by the query. This would enable you to gain insights on who is accessing sensitive data.
Note: You now have multiple options for configuring where audit logs will be written. You can write logs to an Azure storage account, to a Log Analytics workspace for consumption by Azure Monitor logs, or to event hub for consumption using event hub. You can configure any combination of these options, and audit logs will be written to each.
Reference: https://azure.microsoft.com/en-us/blog/announcing-public-preview-of-data-discovery-classification-for-microsoft-azure-sql-data-warehouse/
DRAG DROP -
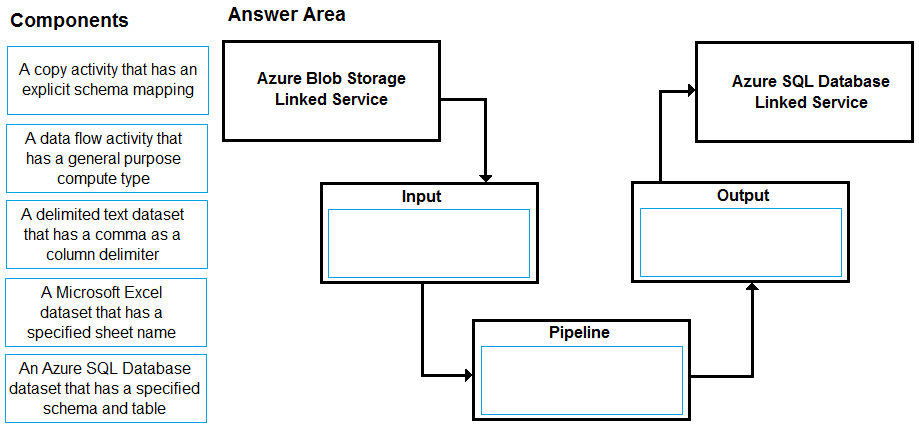
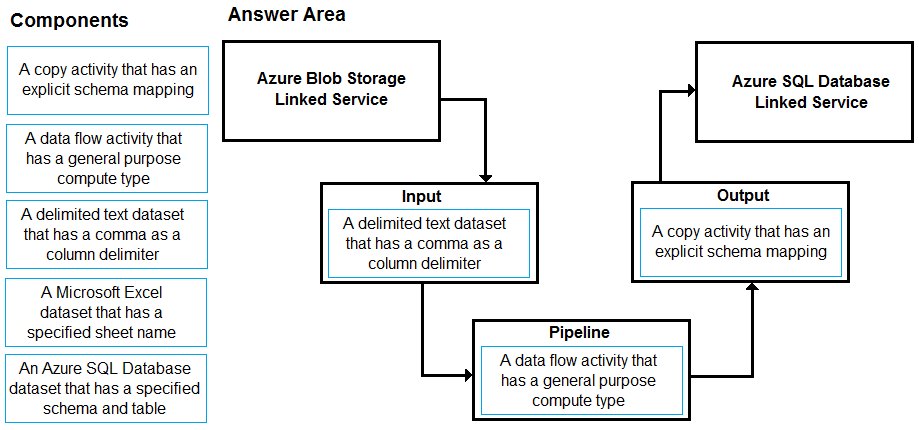
You have a CSV file in Azure Blob storage. The file does NOT have a header row.
You need to use Azure Data Factory to copy the file to an Azure SQL database. The solution must minimize how long it takes to copy the file.
How should you configure the copy process? To answer, drag the appropriate components to the correct locations. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Suggested Answer:
Input: A delimited text dataset that has a comma a column delimiter columnDelimiter: The character(s) used to separate columns in a file.
The default value is comma ,. When the column delimiter is defined as empty string, which means no delimiter, the whole line is taken as a single column.
Pipeline: A data flow activity that has a general purpose compute type
When you’re transforming data in mapping data flows, you can read and write files from Azure Blob storage.
Output: A copy activity that has an explicit schema mapping
Use Copy Activity in Azure Data Factory to copy data from and to Azure SQL Database, and use Data Flow to transform data in Azure SQL Database.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/format-delimited-text https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-database
You are planning an Azure solution that will aggregate streaming data.
The input data will be retrieved from tab-separated values (TSV) files in Azure Blob storage.
You need to output the maximum value from a specific column for every two-minute period in near real-time. The output must be written to Blob storage as a
Parquet file.
What should you use?
A. Azure Data Factory and mapping data flows
B. Azure Data Factory and wrangling data flows
C. Azure Stream Analytics window functions
D. Azure Databricks and Apache Spark SQL window functions
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have streaming data that is received by Azure Event Hubs and stored in Azure Blob storage. The data contains social media posts that relate to a keyword of
Contoso.
You need to count how many times the Contoso keyword and a keyword of Litware appear in the same post every 30 seconds. The data must be available to
Microsoft Power BI in near real-time.
Solution: You create an Azure Stream Analytics job that uses an input from Event Hubs to count the posts that have the specified keywords, and then send the data to an Azure SQL database. You consume the data in Power BI by using DirectQuery mode.
Does the solution meet the goal?
You are designing a data store that will store organizational information for a company. The data will be used to identify the relationships between users. The data will be stored in an Azure Cosmos DB database and will contain several million objects.
You need to recommend which API to use for the database. The API must minimize the complexity to query the user relationships. The solution must support fast traversals.
Which API should you recommend?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are smaller than 250MB.
Does the solution meet the goal?
A. Yes
B. No
Suggested Answer: B
Ensure that files stored are larger, not smaller than 250MB.
You can have a separate compaction job that combines these files into larger ones.
Note: The file POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
✑ Lowering the authentication checks across multiple files
✑ Reduced open file connections
✑ Faster copying/replication
✑ Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database that has columns. The columns contain sensitive Personally Identifiable Information (PII) data.
You need to design a solution that tracks and stores all the queries executed against the PII data. You must be able to review the data in Azure Monitor, and the data must be available for at least 45 days.
Solution: You add classifications to the columns that contain sensitive data. You turn on Auditing and set the audit log destination to use Azure Log Analytics.
Does this meet the goal?
You are designing a real-time stream solution based on Azure Functions. The solution will process data uploaded to Azure Blob Storage.
The solution requirements are as follows:
✑ Support up to 1 million blobs.
✑ Scaling must occur automatically.
✑ Costs must be minimized.
What should you recommend?
A. Deploy the Azure Function in an App Service plan and use a Blob trigger.
B. Deploy the Azure Function in a Consumption plan and use an Event Grid trigger.
C. Deploy the Azure Function in a Consumption plan and use a Blob trigger.
D. Deploy the Azure Function in an App Service plan and use an Event Grid trigger.
Suggested Answer: C
Create a function, with the help of a blob trigger template, which is triggered when files are uploaded to or updated in Azure Blob storage.
You use a consumption plan, which is a hosting plan that defines how resources are allocated to your function app. In the default Consumption Plan, resources are added dynamically as required by your functions. In this serverless hosting, you only pay for the time your functions run. When you run in an App Service plan, you must manage the scaling of your function app.
Reference: https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-storage-blob-triggered-function
You manage a solution that uses Azure HDInsight clusters.
You need to implement a solution to monitor cluster performance and status.
Which technology should you use?
A. Azure HDInsight.NET SDK
B. Azure HDInsight REST API
C. Ambari REST API
D. Azure Log Analytics
E. Ambari Web UI
Suggested Answer: E
Ambari is the recommended tool for monitoring utilization across the whole cluster. The Ambari dashboard shows easily glanceable widgets that display metrics such as CPU, network, YARN memory, and HDFS disk usage. The specific metrics shown depend on cluster type. The “Hosts” tab shows metrics for individual nodes so you can ensure the load on your cluster is evenly distributed. The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Reference: https://azure.microsoft.com/en-us/blog/monitoring-on-hdinsight-part-1-an-overview/ https://ambari.apache.org/
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical data store?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a database-level firewall IP rule
D. a server-level firewall IP rule
Suggested Answer: A
Scenario: Ensure that the analytical data store is accessible only to the company’s on-premises network and Azure services.
Virtual network rules are one firewall security feature that controls whether the database server for your single databases and elastic pool in Azure SQL Database or for your databases in SQL Data Warehouse accepts communications that are sent from particular subnets in virtual networks.
Server-level, not database-level: Each virtual network rule applies to your whole Azure SQL Database server, not just to one particular database on the server. In other words, virtual network rule applies at the server-level, not at the database-level.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vnet-service-endpoint-rule-overview
Free Access Full DP-201 Practice Questions Free
Want more hands-on practice? Click here to access the full bank of DP-201 practice questions free and reinforce your understanding of all exam objectives.
We update our question sets regularly, so check back often for new and relevant content.





Which Azure services should you use for the cold path? To answer, drag the appropriate services to the correct layers. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place: